AWS Big Data Blog
Log analytics the easy way with Amazon OpenSearch Serverless
We recently announced the preview release of Amazon OpenSearch Serverless, a new serverless option for Amazon OpenSearch Service, which makes it easy for you to run large-scale search and analytics workloads without having to configure, manage, or scale OpenSearch clusters. It automatically provisions and scales the underlying resources to deliver fast data ingestion and query responses for even the most demanding and unpredictable workloads.
OpenSearch Serverless supports two primary use cases:
- Log analytics that focuses on analyzing large volumes of semi-structured, machine-generated time series data for operational, security, and user behavior insights
- Full-text search that powers customer applications in their internal networks (content management systems, legal documents) and internet-facing applications such as ecommerce website catalog search and content search
This post focuses on building a simple log analytics pipeline with OpenSearch Serverless.
Solution overview
In the following sections, we walk through the steps to create and access a collection in OpenSearch Serverless, and demonstrate how to configure two different data ingestion pipelines to index data into the collection.
Create a collection
To get started with OpenSearch Serverless, you first create a collection. A collection in OpenSearch Serverless is a logical grouping of one or more indexes that represent an analytics workload.
The following graphic gives a quick navigation for creating a collection. Alternatively, refer to this blog post to learn more about how to create and configure a collection in OpenSearch Serverless.
Access the collection
You can use the AWS Identity and Access Management (IAM) credentials with a secret key and access key ID for your IAM users and roles to access your collection programmatically. Alternatively, you can set up SAML authentication for accessing the OpenSearch Dashboards. Note that SAML authentication is only available to access OpenSearch Dashboards; you require IAM credentials to perform any operations using the AWS Command Line Interface (AWS CLI), API, and OpenSearch clients for indexing and searching data. In this post, we use IAM credentials to access the collections.
Create a data ingestion pipeline
OpenSearch Serverless supports the same ingestion pipelines as the open-source OpenSearch and managed clusters. These clients include applications like Logstash and Amazon Kinesis Data Firehose, and language clients like Java Script, Python, Go, Java, and more. For more details on all the ingestion pipelines and supported clients, refer to ingesting data into OpenSearch Serverless collections.
Using Logstash
The open-source version of Logstash (Logstash OSS) provides a convenient way to use the bulk API to upload data into your collections. OpenSearch Serverless supports the logstash-output-opensearch output plugin, which supports IAM credentials for data access control. In this post, we show how to use the file input plugin to send data from your command line console to an OpenSearch Serverless collection. Complete the following steps:
- Download the
logstash-oss-with-opensearch-output-pluginfile (this example uses the distro for macos-x64; for other distros, refer to the artifacts): - Extract the downloaded tarball:
- Update the
logstash-output-opensearchplugin to the latest version:The OpenSearch output plugin for OpenSearch Serverless uses IAM credentials to authenticate. In this example, we show how to use the file input plugin to read data from a file and ingest into an OpenSearch Serverless collection.
- Create a log file with the following sample data and name it sample.log:
- Create a new file and add the following content, and save the file as
logstash-output-opensearch.confafter providing the information about your file path, host, Region, access key, and secret access key: - Use the following command to start Logstash with the config file created in the previous step. This creates an index called
logstash-sampleand ingests the document added under thesample.logfile: - Search using OpenSearch Dashboards by running the following query:
In this step, you used a file input plugin from Logstash to send data to OpenSearch Serverless. You can replace the input plugin with any other plugin supported by Logstash, such as Amazon Simple Storage Service (Amazon S3), stdin, tcp, or others, to send data to the OpenSearch Serverless collection.
Using a Python client
OpenSearch provides high-level clients for several popular programming languages, which you can use to integrate with your application. With OpenSearch Serverless, you can continue to use your existing OpenSearch client to load and query your data in collections.
In this section, we show how to use the opensearch-py client for Python to establish a secure connection with your OpenSearch Serverless collection, create an index, send sample logs, and analyze those log data using OpenSearch Dashboards. In this example, we use a sample event generated from fleets carrying goods and packages. This data contains pertinent fields such as source, destination, weather, speed, and traffic. The following is a sample record:
To set up the Python client for OpenSearch, you must have the following prerequisites:
- Python3 installed on your local machine or the server from where you are running this code
- Package Installer for Python (PIP) installed
- The AWS CLI configured; we use it to store the secret key and access key for credentials
Complete the following steps to set up the Python client:
- Add the OpenSearch Python client to your project and use Python’s virtual environment to set up the required packages:
- Save your frequently used configuration settings and credentials in files that are maintained by the AWS CLI (see Quick configuration with aws configure) by using the following commands and providing your access key, secret key, and Region:
- The following sample code uses the
opensearch-pyclient for Python to establish a secure connection to the specified OpenSearch Serverless collection and index a sample document to index time series. You must provide values forregionandhost. Note that you must useaossas the service name for OpenSearch Service. Copy the code and save in a file assample_python.py: - Run the sample code:

- On the OpenSearch Service console, select your collection.
- On OpenSearch Dashboards, choose Dev Tools.
- Run the following search query to retrieve documents:
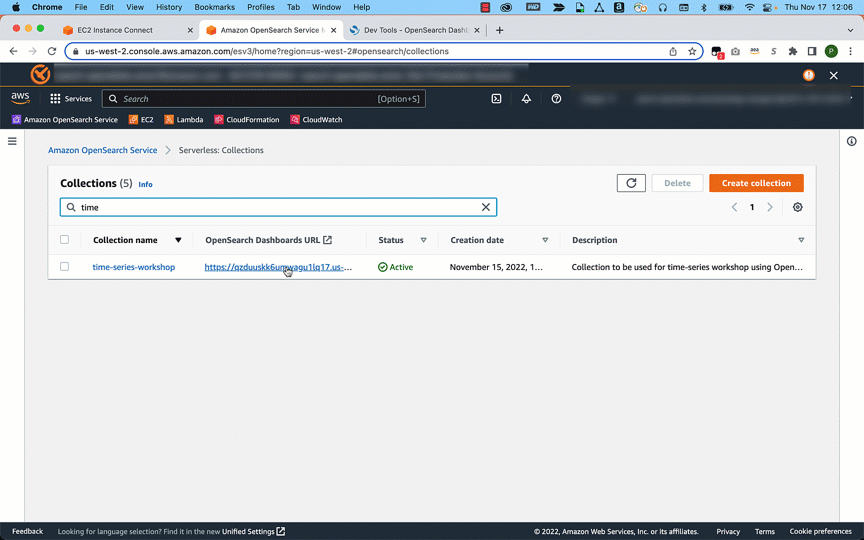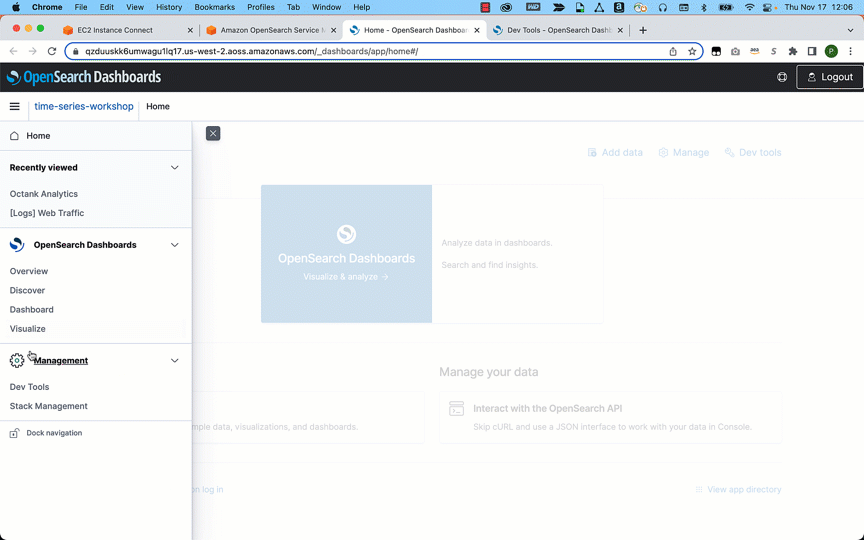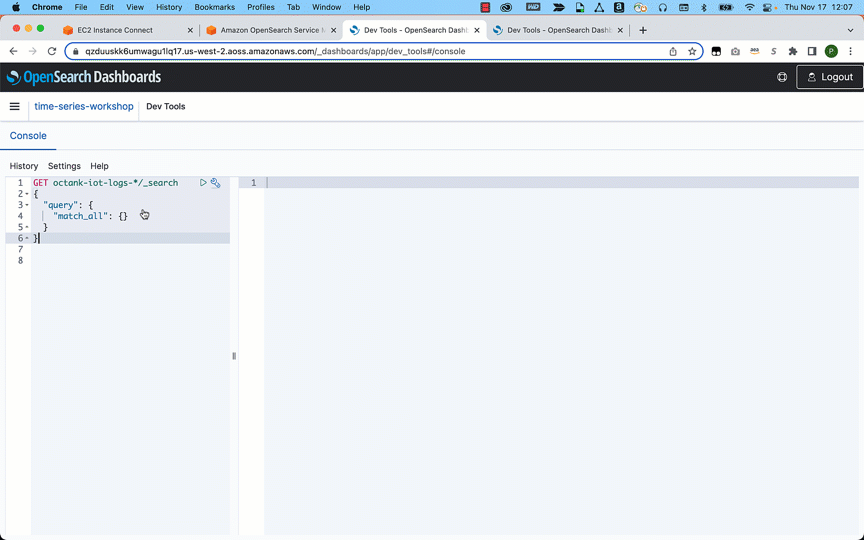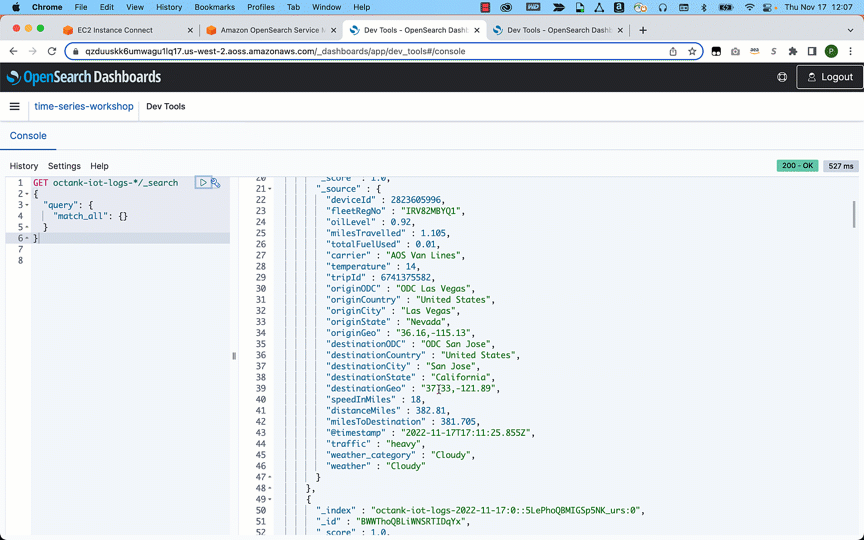
After you have ingested the data, you can use OpenSearch Dashboards to visualize your data. In the following example, we analyze data visually to gain insights on various dimensions such as average fuel consumed by a specific fleet, traffic conditions, distance traveled, and average mileage by the fleet.
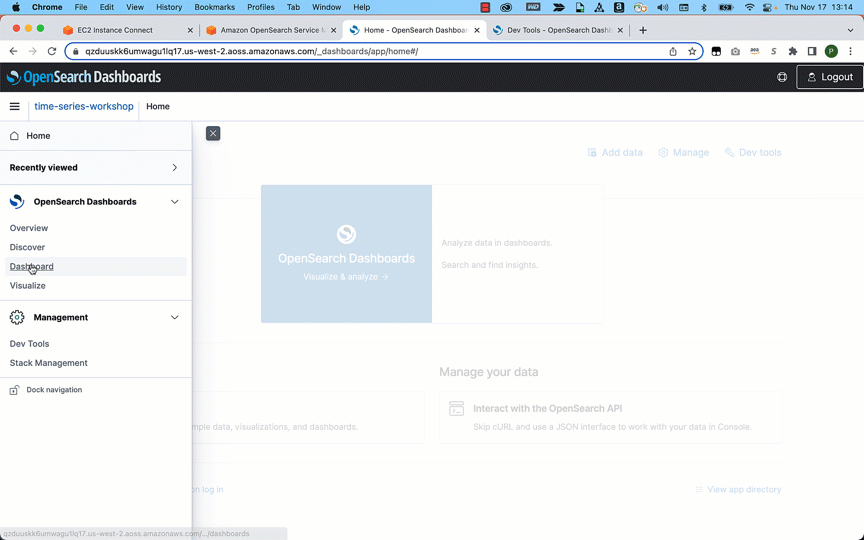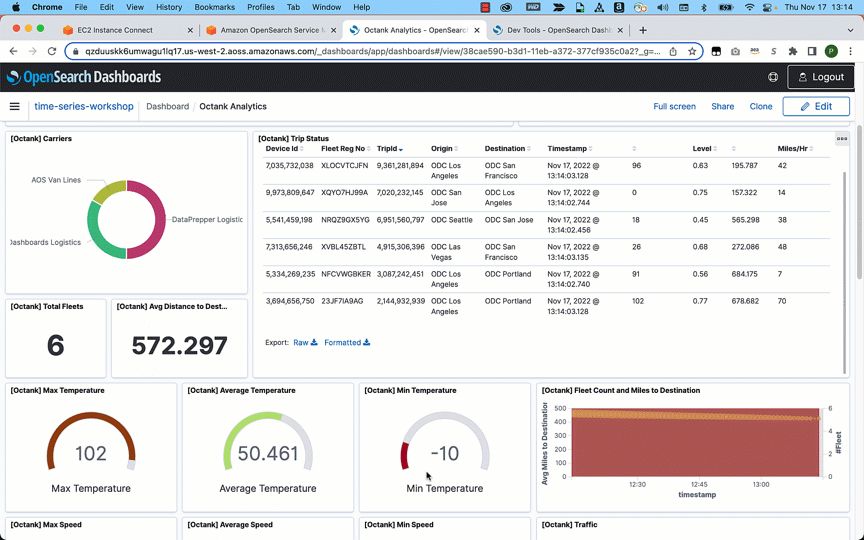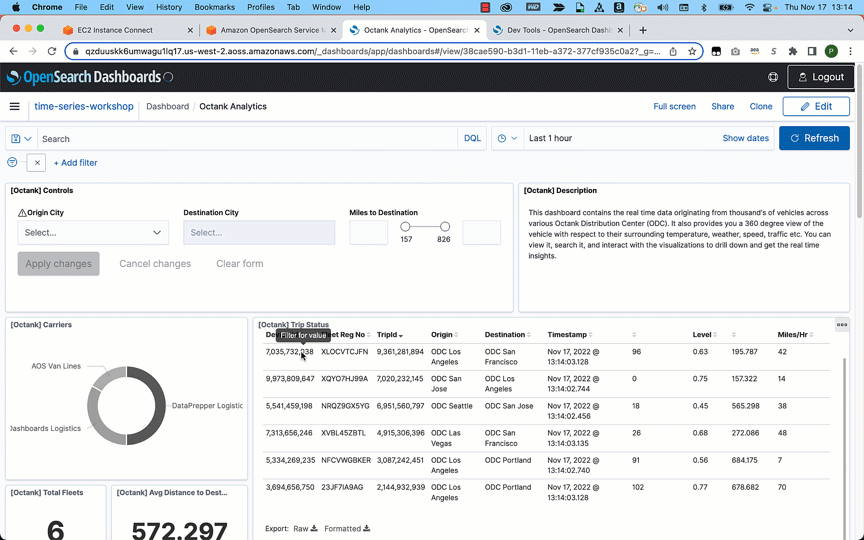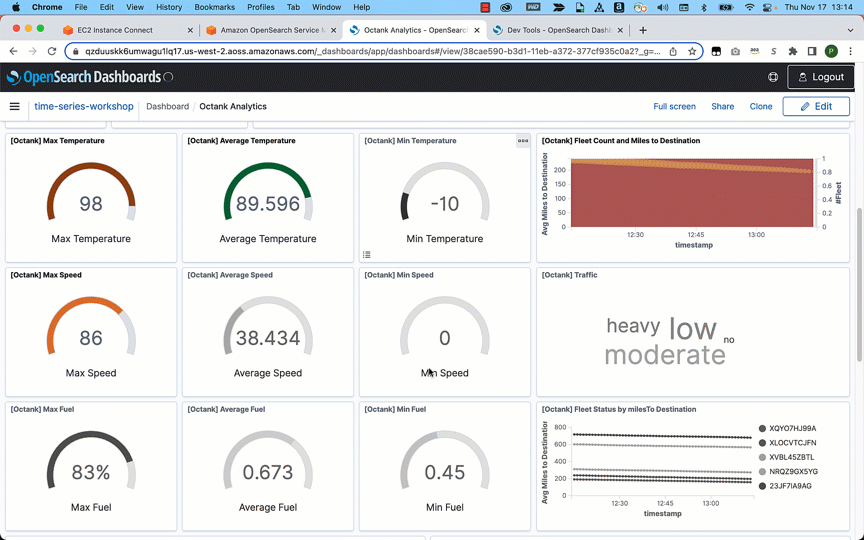
Conclusion
In this post, you created a log analytics pipeline using OpenSearch Serverless, a new serverless option for OpenSearch Service. With OpenSearch Serverless, you can focus on building your application without having to worry about provisioning, tuning, and scaling the underlying infrastructure. OpenSearch Serverless supports the same ingestion pipelines and high-level clients as the open-source OpenSearch project. You can easily get started using the familiar OpenSearch indexing and query APIs to load and search your data and use OpenSearch Dashboards to visualize that data.
Stay tuned for a series of posts focusing on the various options available for you to build effective log analytics and search applications. Get hands-on with OpenSearch Serverless by taking the Getting Started with Amazon OpenSearch Serverless workshop and build a similar log analytics pipeline that was discussed in this post.
About the authors
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
 Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.
Pavani Baddepudi is a senior product manager working in search services at AWS. Her interests include distributed systems, networking, and security.