Amazon Web Services ブログ
Python アプリのモニタリングを Amazon CloudWatch Application Signals (プレビュー) で実施
AWS は re:Invent 2023 で Amazon CloudWatch Application Signals を発表しました。これは Java アプリケーションの健全性をモニタリングして理解するための新機能です。本日、Application Signals が Python アプリケーション のサポートを開始したことをお知らせします。 Application Signals を有効化することで、コード変更なしで Python アプリケーションに AWS Distro for OpenTelemetry (ADOT) を導入できるようになります。これにより、Python を使って開発されたライブラリやフレームワークの主要なメトリクスとトレースを収集できます。カスタムコードの作成やダッシュボードの作成なしに、運用上の健全性の優先順位付けやパフォーマンス目標のモニタリングが可能になります。
このブログ記事では、Amazon EKS クラスター上でデプロイされた Python アプリケーションに Application Signals をシームレスに統合する方法について詳しく説明します。具体的には、Django フレームワークで開発された Python アプリケーションと、psycopg2、boto3、requests などの人気のあるライブラリを使用したアプリケーションをモニタリングすることに焦点を当てます。その後、Application Signals コンソールを使用して、アプリケーションの稼働状況を可視化します。
ソリューションの概要
以下に、このソリューションの詳細な技術的な概要を示します。
- デモアプリケーションは Spring Cloud と Django フレームワークで構築されており、各サービスは Eureka discovery-service に登録されます。アプリケーションコードは GitHub リポジトリ にあります。
insurancesとbillingの 2 つのサービスは Django フレームワークで記述されており、Django REST フレームワークを通じて API を公開し、requests ライブラリを使用して外部サービスを呼び出しています。- サービスは psycopg2 を使用して Amazon RDS for PostgreSQL とやり取りし、boto3 ライブラリを使用して AWS DynamoDB に請求情報を格納しています。
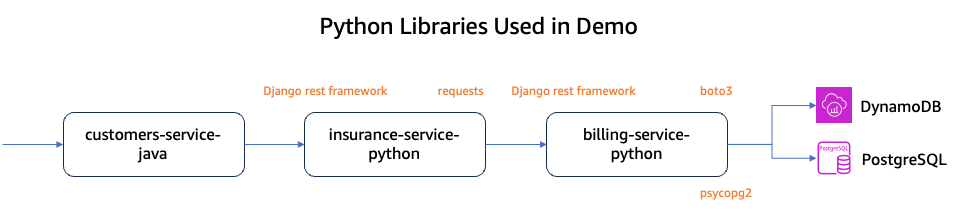
図 1: デモアプリケーションで使用される Python のライブラリとフレームワーク
図 2 に示すリソースを Terraform でデプロイします。CloudWatch エージェントと Fluent Bit をデーモンセットとしてデプロイし、Amazon CloudWatch Observability EKS アドオンを使用します。これらのコンポーネントは、メトリクス、ログ、トレースを管理します。
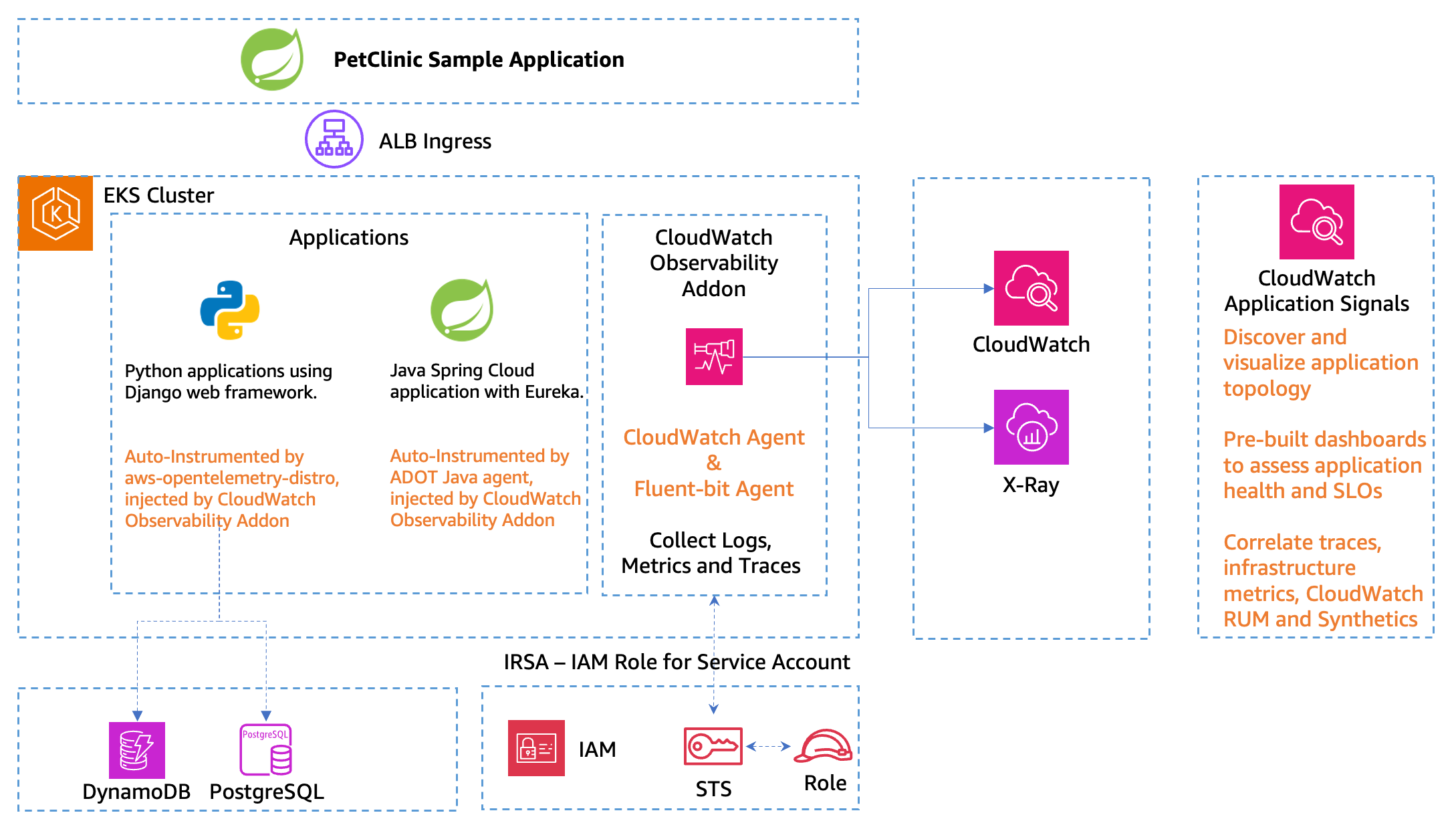
図 2: ソリューションアーキテクチャ
前提条件
解決策の手順解説
Application Signals の有効化
アカウントの Application Signals を有効化する手順に従ってください。
Terraform を使用したアプリケーションのデプロイ
- 以下のコマンドを実行して、Terraform を使用してアプリケーションをデプロイするために必要な 環境変数を設定し、バックエンドとして Amazon S3 バケットを設定します。
export AWS_REGION=<your-aws-region> aws s3 mb s3://tfstate-$(uuidgen | tr A-Z a-z) export TFSTATE_KEY=application-signals/demo-applications export TFSTATE_BUCKET=$(aws s3 ls --output text | awk '{print $3}' | grep tfstate-) export TFSTATE_REGION=$AWS_REGION export TF_VAR_cluster_name=app-signals-demo export TF_VAR_cloudwatch_observability_addon_version=v1.5.1-eksbuild.1 - 次に、アプリケーションリポジトリをクローンし、Terraform を使用してインフラストラクチャをデプロイします。リソースのプロビジョニングに成功するまで 15 ~ 20 分かかります。
git clone https://github.com/aws-observability/application-signals-demo cd application-signals-demo/terraform/eks terraform init -backend-config="bucket=${TFSTATE_BUCKET}" -backend-config="key=${TFSTATE_KEY}" -backend-config="region=${TFSTATE_REGION}" terraform apply --auto-approve
kubectl の設定
次のコマンドを実行して、kubeconfig ファイルを更新し、Amazon EKS Cluster エンドポイントをローカルに追加してください。
Kubernetes リソースのアノテーションを使ったデプロイ
- Python アプリケーションで Application Signals を有効にするには、クラスターのマニフェスト YAML に
instrumentation.opentelemetry.io/inject-python: 'true'というアノテーションを追加する必要があります。このアノテーションを追加すると、アプリケーションが自動的にインストルメント化され、メトリクス、トレース、ログを Application Signals に送信するようになります。spec: replicas: 1 selector: matchLabels: io.kompose.service: billing-service-python template: metadata: labels: io.kompose.service: billing-service-python annotations: instrumentation.opentelemetry.io/inject-python: 'true' /demo-app/k8s/の下にある デプロイ用の YAML ファイルには、必要なアノテーションが含まれています。以下のコマンドを実行してすべてのリソースをデプロイします。まず、アプリケーションをコンパイル、Docker イメージを作成し、リモートの ECR (Amazon Elastic Container Registry) の Docker リポジトリにプッシュしてから、EKS クラスターにデプロイします。cd ../.. ./mvnw clean install -P buildDocker export ACCOUNT=`aws sts get-caller-identity | jq .Account -r` export REGION=$AWS_REGION ./push-ecr.sh ./scripts/eks/appsignals/tf-deploy-k8s-res.sh
デプロイの結果の検証
- アプリケーションリソースが正常にデプロイされたことを確認するため、以下のコマンドを実行してください。ステータスが Running のポッドのリストが表示されるはずです。
kubectl get pods #Output NAME READY STATUS RESTARTS AGE admin-server-java-5c57ddcb46-t4b9l 1/1 Running 0 7m1s billing-service-python-6bf9766cfc-5g67s 1/1 Running 0 6m52s config-server-58d94894-dzdhz 1/1 Running 0 6m47s customers-service-java-69c5d75cc9-5hwrw 1/1 Running 0 6m42s customers-service-java-69c5d75cc9-tfrts 1/1 Running 0 6m43s discovery-server-d6bff754f-xgrxv 1/1 Running 0 6m36s insurance-service-python-6745799b9b-4hdxc 1/1 Running 0 6m33s pet-clinic-frontend-java-5696d89cd8-cpvj2 1/1 Running 0 6m56s pet-clinic-frontend-java-5696d89cd8-mlggq 1/1 Running 0 6m56s vets-service-java-5b6969b8d6-cfvsb 1/1 Running 0 6m29s visits-service-java-85b9c5c45-p57m5 1/1 Running 0 6m25s visits-service-java-85b9c5c45-vwkht 1/1 Running 0 6m25s visits-service-java-85b9c5c45-vx6gj 1/1 Running 0 6m25s - 次に、以下のコマンドを実行してアプリケーションにアクセスするための URL を取得してください。ウェブブラウザでその URL を開き、アプリケーションを体験することができます。URL が有効になるまで 2~3 分かかる場合があります。
echo "http://$(kubectl get ingress -o json --output jsonpath ='{.items[0].status.loadBalancer.ingress[0].hostname }')"
CloudWatch Canary を作成し、トラフィックを生成する
次に、以下のスクリプトを実行して Canary を作成します。このスクリプトは 10 分間実行され、アプリケーションのトラフィックを生成します。
CloudWatch Application Signals を使用したアプリケーションの可視化
CloudWatch コンソールに移動し、左側のナビゲーションペインの Application Signals セクションにある サービス を選択します。
サービスダッシュボード
CloudWatch Application Signals は、初期状態で追加のセットアップを必要とせずに、サービスダッシュボードからサービスの一覧を自動的に作成します。この統合されたアプリケーション中心のビューは、ユーザーがサービスとどのように対話しているかを全体的に把握するのに役立ちます。パフォーマンスの異常が発生した場合、この機能を使ってトラブルの切り分けをすることができます。
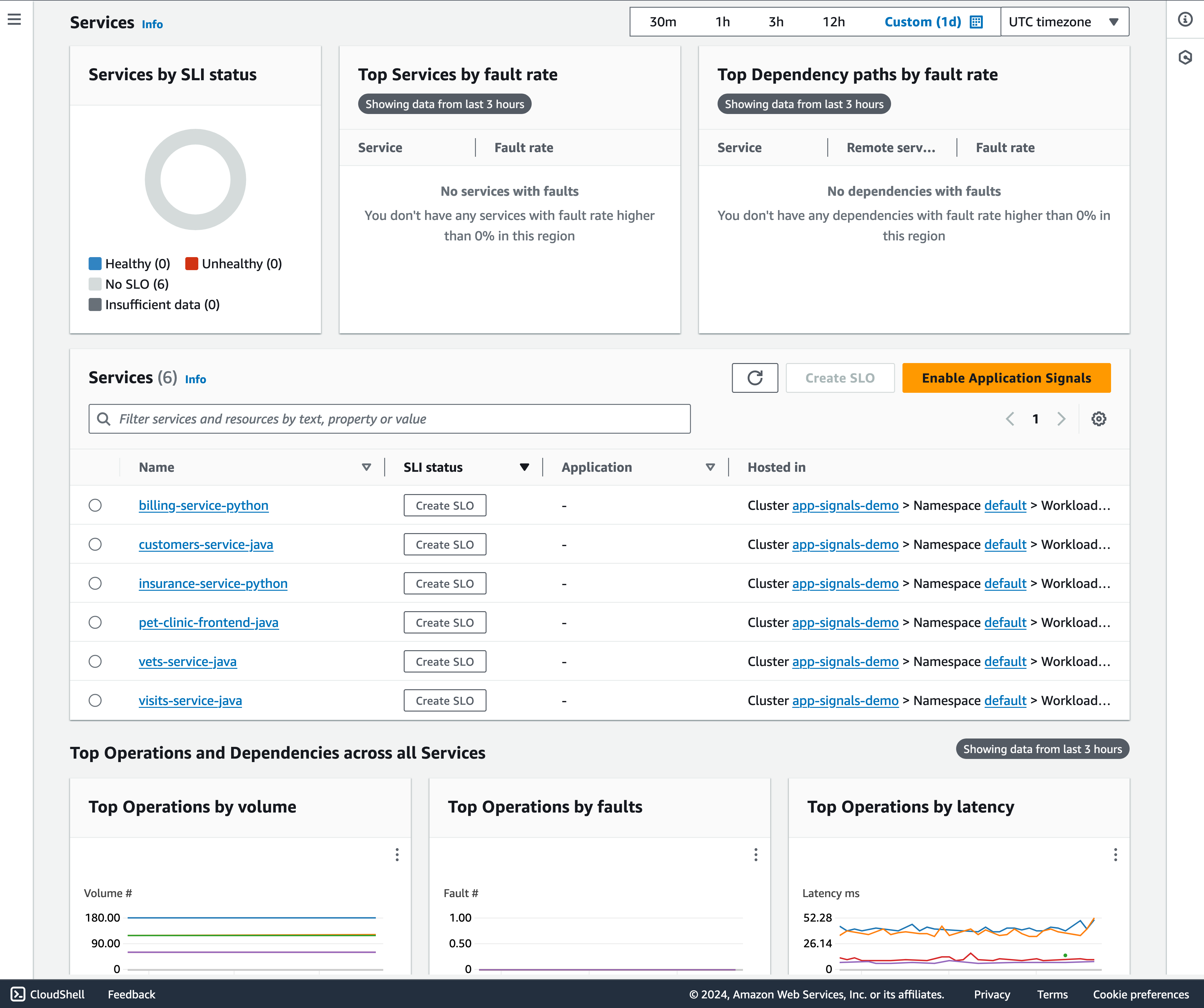
図 3: サービスダッシュボード
詳細なサービス情報と依存関係
サービス詳細ページには、Application Signals 機能を使用しているサービスについて、サービスの概要、オペレーション、依存関係、Canary、クライアントからの要求が表示されます。このページを表示するには、CloudWatch コンソールを開き、左側のナビゲーションペインの Application Signals セクションにある Services を選択します。そして、Services テーブルまたは Top service あるいは依存関係テーブルから、任意のサービス名を選択してください。
図 4 に示すように、Service Overview セクションでは、サービスを構成するコンポーネントを要約し、トラブルシューティングが必要な問題を特定するための重要なパフォーマンスメトリクスをハイライトしています。
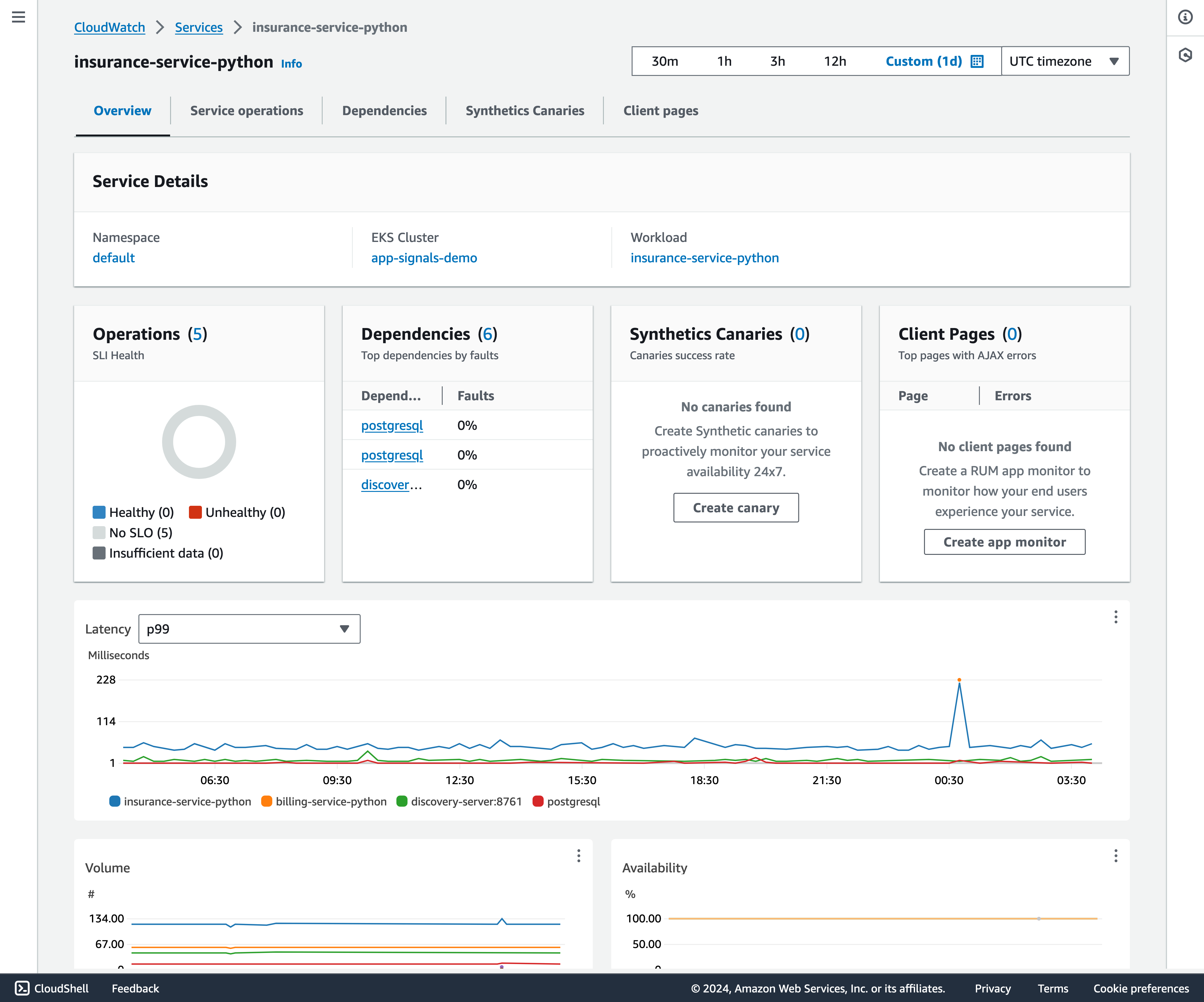
図 4: Service Overview
Service operationsタブに移動し、オペレーションを選択、メトリクスチャートの特定の時間ポイントをクリックすると、選択したポイントに関連する相関トレース、主要な要因、アプリケーションログを含むペインが開きます。
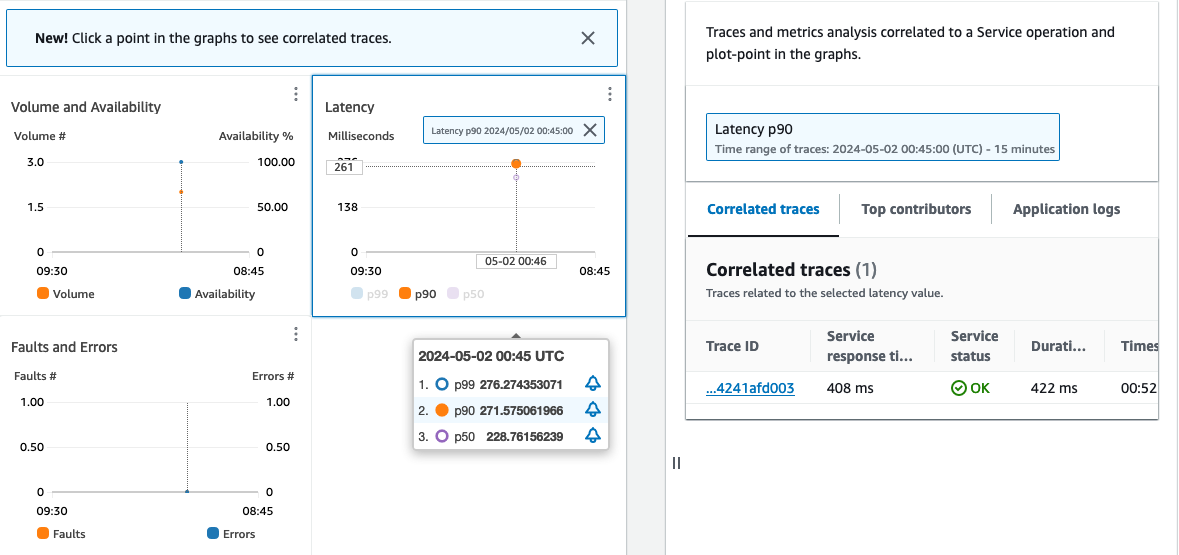
図 5: Service operations
トレース ID をクリックすると、トレースの詳細ページに移動します。そこではこのトレース ID に関連するすべてのアップストリーム及びダウンストリームのサービスが、AWS X-ray トレースマップに表示されます。
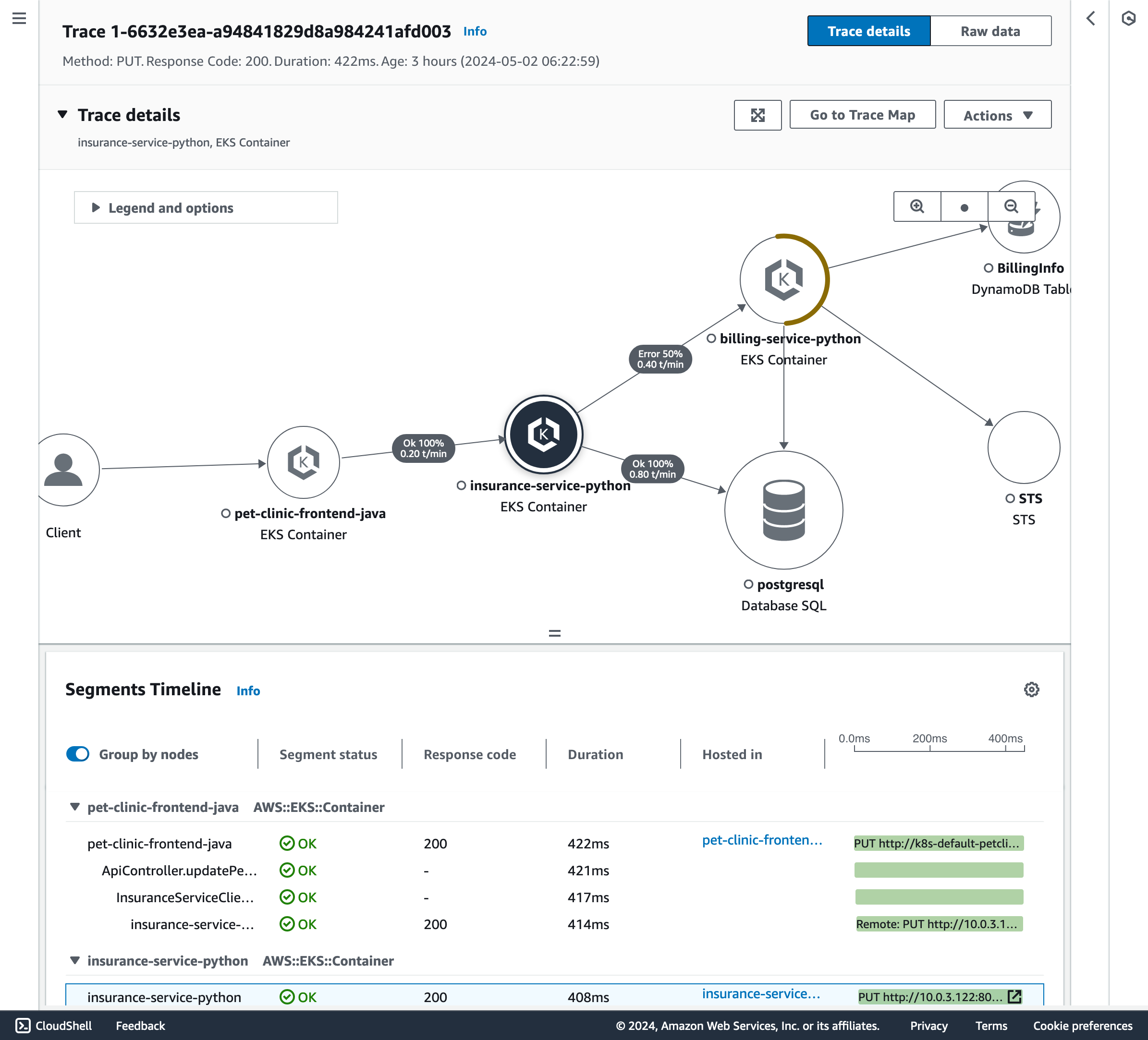
図 6: サービスオペレーションメトリクスと関連付けられたトレースを可視化
Top Contributors セクションでは、Call Volume、Availability、Average Latency、ErrorsとFaultsのメトリックを、インフラストラクチャコンポーネント別に直接表示します。Application Logsタブでは、関連するアプリケーションログを表示するための Logs Insights クエリを確認できます。
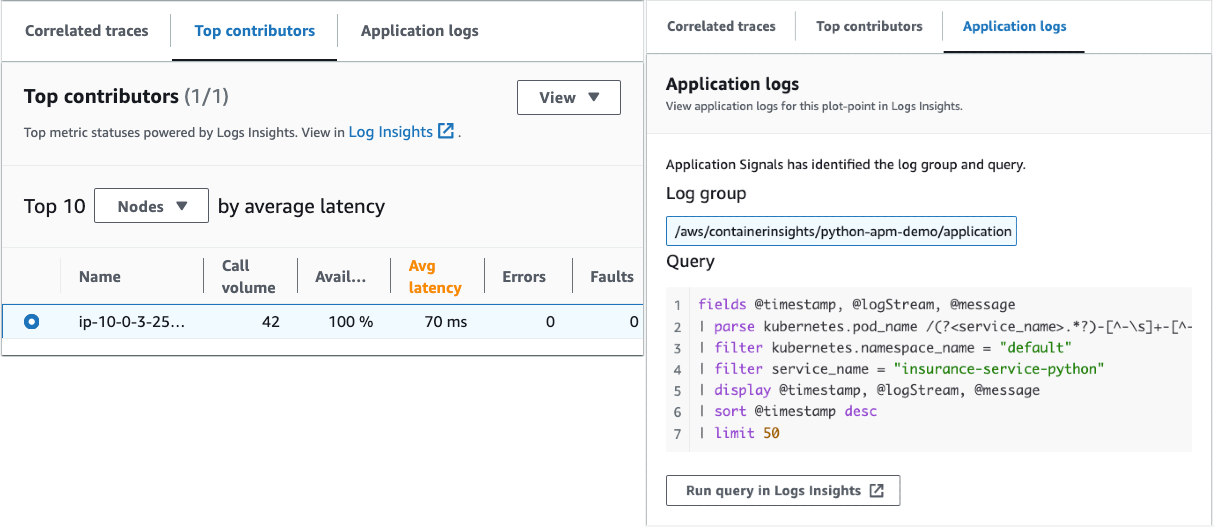
図 7: Top Contributors と Application Logs
数クリックすると相関のあるトレースが表示されます。これにより、手動でトレースを別々に照会することなく問題の根本原因を理解できます。
サービスマップ
サービスマップを表示するには、CloudWatch コンソールを開き、左側のナビゲーションペインにある Application Signals セクションの Service Map を選択して図 8 に示されているように、billing-service-pythonのサービスノードを選択すると、それらのサービス間の接続およびサービスの依存関係ノードを確認できます。これにより、アプリケーションのトポロジーと実行フローを理解しやすくなります。サービスの運用と開発が別組織の場合に特に有用です。
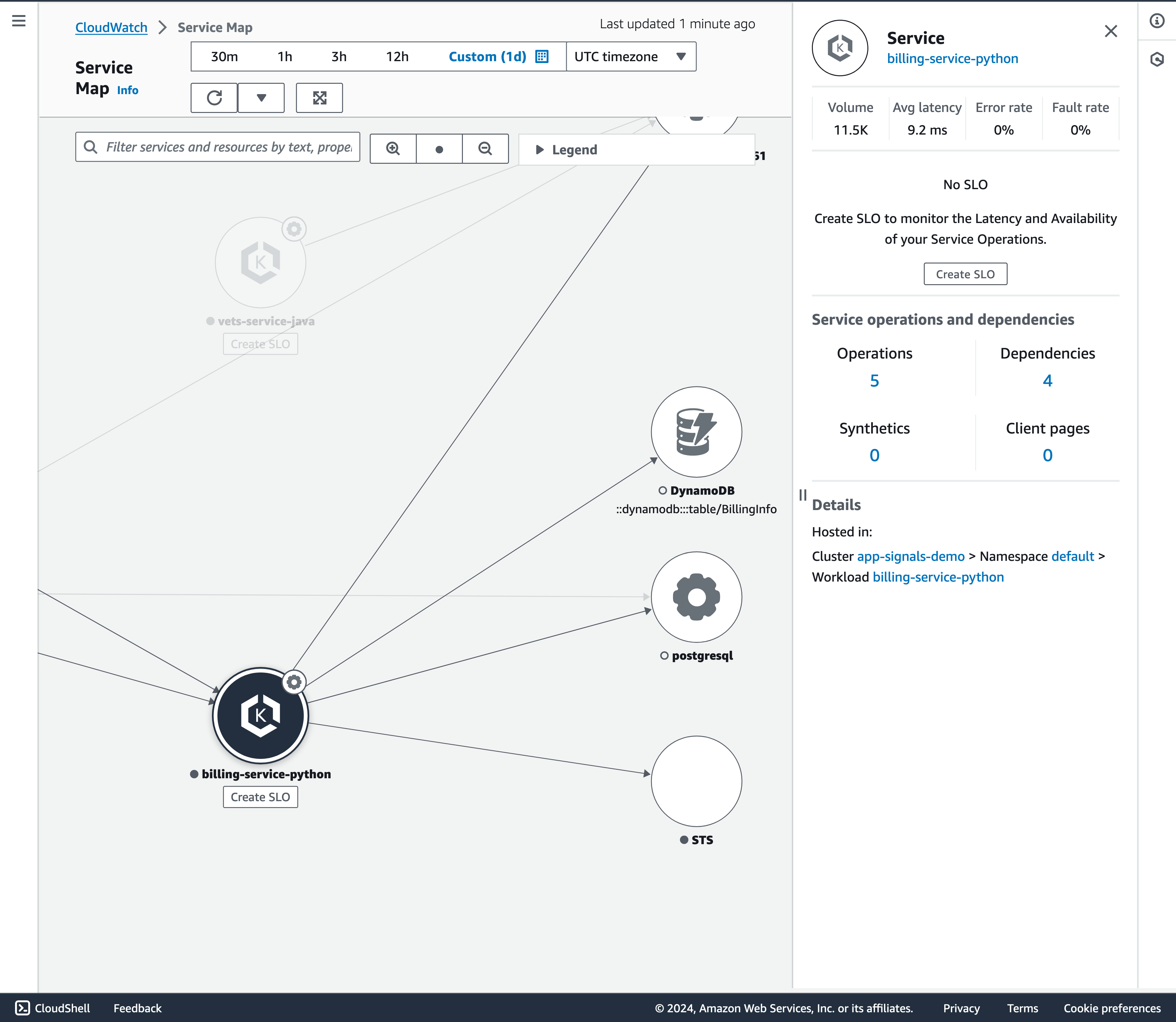
図 8: サービスマップを使ってアプリケーショントポロジーを表示
サービスレベル目標 (SLOs)
Application Signals を使用して、最も重要なビジネス オペレーションのサービス レベル目標 (SLO) を定義します。これらのサービスの SLO を定義すると、SLO ダッシュボードでそれらを監視できるようになり、最も重要なオペレーションの概要を素早く把握できます。SLO の条件には、レイテンシ、可用性、CloudWatch メトリクスが含まれ、包括的な監視機能を提供します。
PetClinic アプリケーションの SLO 作成 の手順に従って、SLO を作成してください。
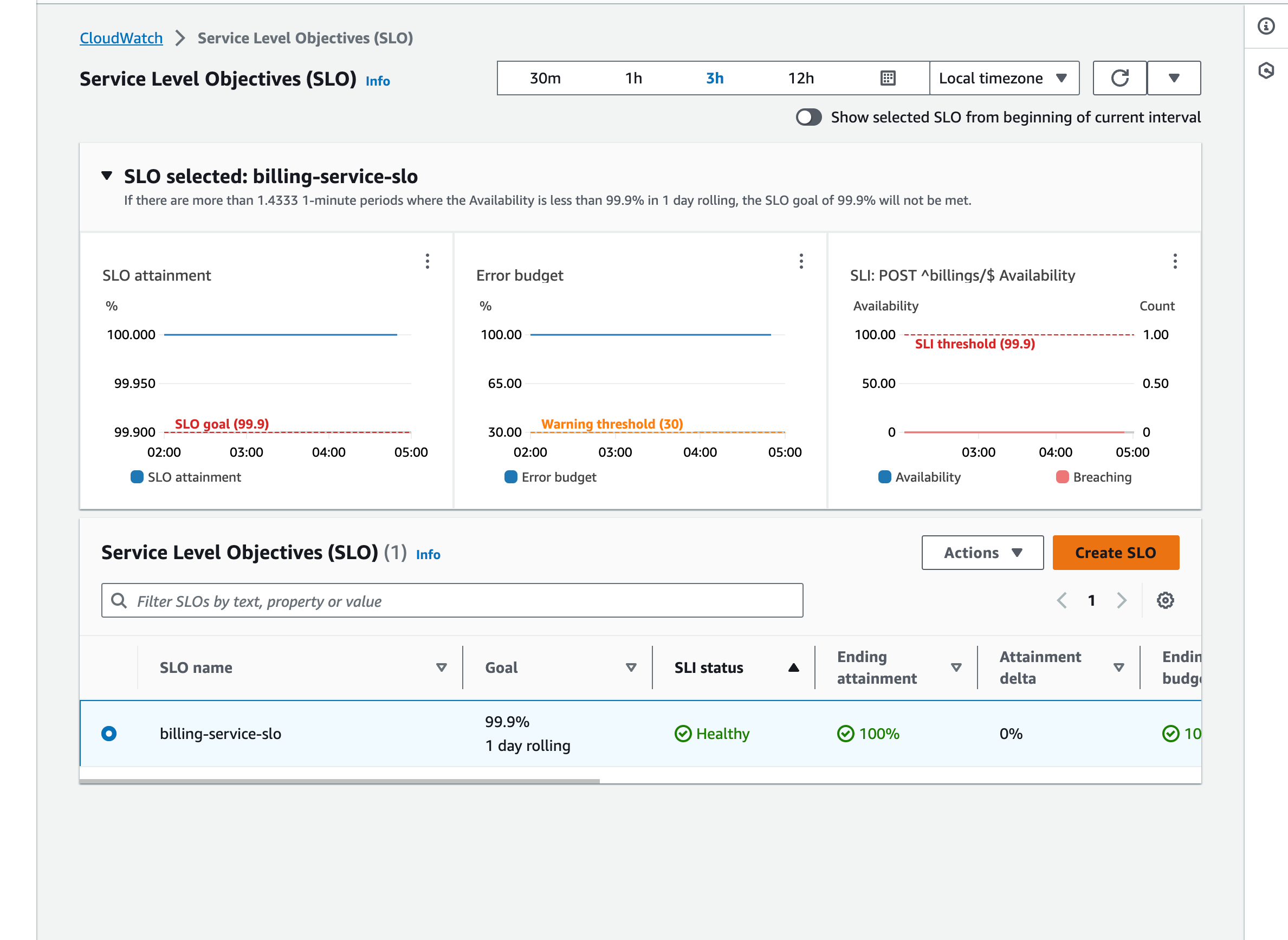
図 9: サービスレベル目標 (SLO) を作成し可視化する
クリーンアップ
注意: アプリケーションを正常に削除するには、前に定義した環境変数の値が必要です。
料金の発生を停止するには、次のコマンドを実行してアプリケーションをクリーンアップしてください。所要時間は 15 ~ 20 分です。
結論
このブログでは、Amazon EKS クラスター上で実行されている Python アプリケーションを、コード変更を行うことなくシームレスに計装するための CloudWatch Application Signals の活用方法について説明しました。この強力な機能により、アプリケーションサービスのゴールデンメトリクス (リクエスト数、可用性、レイテンシー、障害、エラー) とトレースを簡単に収集でき、監視とトラブルシューティングが容易になります 。
さらに、Application Signals が提供する既製のダッシュボードを使うことで、アプリケーションサービスの全体の活動状況と運用の健全性をどのように視覚化できるかを説明しました。これらのダッシュボードを活用することで、主要なパフォーマンスメトリクスにすばやくアクセスし、トレースと関連付けて、根本的な問題を数クリックで簡単に特定して対処できます。次のステップとして、お客様の環境で Application Signals を試してみることをお勧めします。
CloudWatch Application Signals のドキュメント を参照して、さらに詳しい情報を確認するか、One Observability Workshop の CloudWatch Application Signals のユースケース を体験してみてください。
著者について
本記事は、Monitor Python apps with Amazon CloudWatch Application Signals (Preview) を翻訳したものです。翻訳はテクニカルアカウントマネージャーの日平が担当しました。