Amazon Web Services ブログ
新機能 – AWS Lambda :あらゆるプログラム言語への対応と一般的なコンポーネントの共有
私は2014年にアナウンスしたAWS Lambdaを発表した興奮を覚えています。4年の間でお客様は様々な異なるユースケースでLambda関数をご利用頂いています。
例をあげると iRobotはAWS Lambdaをロボット掃除機のroombaのコンピュートサービスとして利用しています、Fanne MaeはMonte Carloの100万をこえる抵当のシミュレーションとして利用、Bustleは彼らのデジタルコンテンツへの数百万のリクエストとして利用しています。本日、私は2つの新しい機能をご紹介します、これは今までよりサーバレスの開発を簡単にするものです:
- Lambda Layers, 複数の関数で共用されるコードやデータをセンタライズし管理するものです
- Lambda Runtime API, あなたが開発する、どんなプログラム言語や特定のバージョンでも簡単に利用できるようになるものです
これら2つの機能は一緒に利用することができます。ランタイムはレイヤとして共有できるために、開発者はLambda関数を作成時にお好みの言語で利用することができます。
Lambda Layers
サーバレスアプリケーションを開発する際に、複数のLambda関数から共有されるコードを持つことは極めて一般的なことです。Lambda Layersにより、ビジネスロジックの実装を簡素化するために複数の関数追加することまたは標準ライブラリによって使用されるカスタムコードにすることができます。
これまではすべての関数で、共有されるコードを一緒にして1つのパッケージ化し、デプロイすることが必要でした。これからは、一般的なコンポーネントを1つのzipファイル作成し、それをLambda Layerとして置くことができます。関数のコードは変更する必要はなく、通常のようにレイヤー内のライブラリーを参照することができます。
レイヤーにはバージョンを設定しアップデートを管理することができまし、各バージョンはイミュータブルなものとなります。バージョンを削除もしくは権限を剥奪した場合、関数は前のバージョンで動くでしょう。しかし、新しいものを作れなくなります。
関数の設定において、最大5つのレイヤーまで参照することができます。それのうち1つはオプションでランタイムとして指定することができます。関数が実行されると各レイヤはあなたが指定した順序で/optに展開されます。レイヤはすべて同じPath情報となるために順序が重要です、これは先に展開したものを上書きして可能性があることを示唆しています。このアプローチを使用して環境をカスタマイズすることができます。 たとえば、最初のレイヤーはランタイムになり、2番目のレイヤーは必要なライブラリの特定のバージョンを追加すると言ったこともできます。関数とレイヤの未圧縮状態のサイズについては通常の未圧縮状態のサイズの制限と一致します。
レイヤを利用するといくつかのアドバンテージを得ることができます。例えば、以下のためにLambda Layersを利用することが考えられます
- 依存関係とあなたのビジネスロジックの懸念の分離
- コードを小さくし、あなたがやりたことにより集中できる
- 少ないコードでのパッケージ化、アップロードと依存関係を再利用できることでデプロイがもっと高速になる
お客さまのフィードバックに基づいて、そしてどのようLambda Layersを使うかの例を提示するために、私達は、NumPy/SciPyを含むパブリックレイヤを公開します。この2つは有名なサイエンティフィックなPythonのライブラリです。このプレビルドされたレイヤは、あなたがデータプロセッシングや機械学習のアプリケーションを作るのに役立つでしょう。
加えて、あなたは、アプリケーションモニタリング、セキュリティ、そして管理のためレイヤをDatadog、Epsagon、IOpipe、NodeSource、Thundra、Protego、PureSec,Twistlock、ServerlessそしてStackeryのようなパートナーから見つけることができるでしょう。
Lambda Layersの利用
Lambdaのコンソールから私のレイヤを管理します。
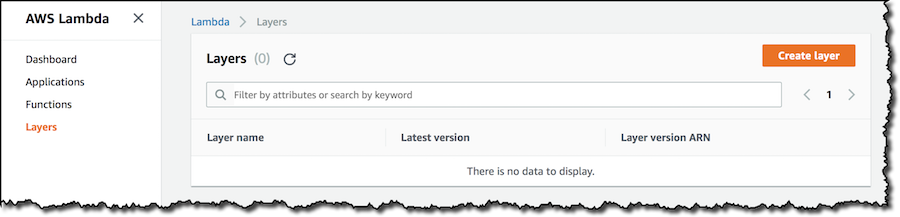
私は今、新しいレイヤーを作成するのではなく、既存のレイヤーを関数内で使ってみようと思います。1つの新しい Pythonの関数を作成しました、そして、関数の設定において参照するレイヤがないことが見えています。新しいレイヤを1つ追加してみます。
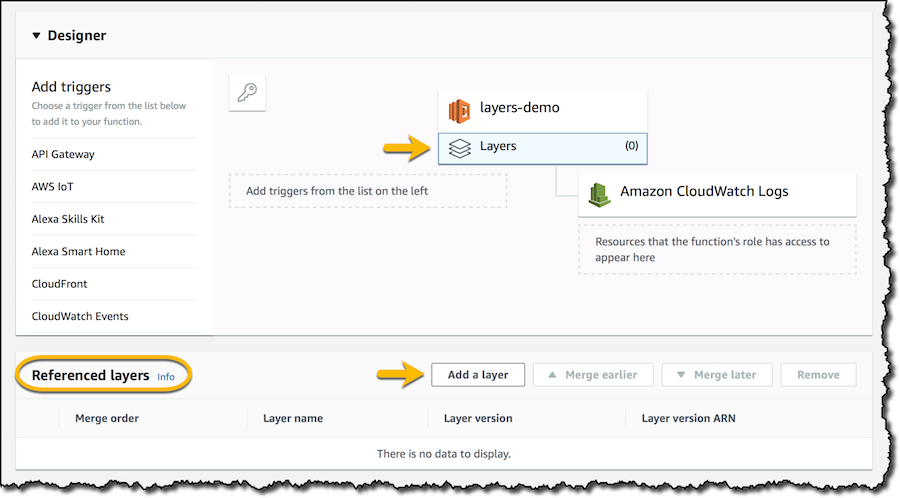
私の関数のランタイムと互換性のあるレイヤのリストから、NumPy と SciPyの最新バージョンを選択します。
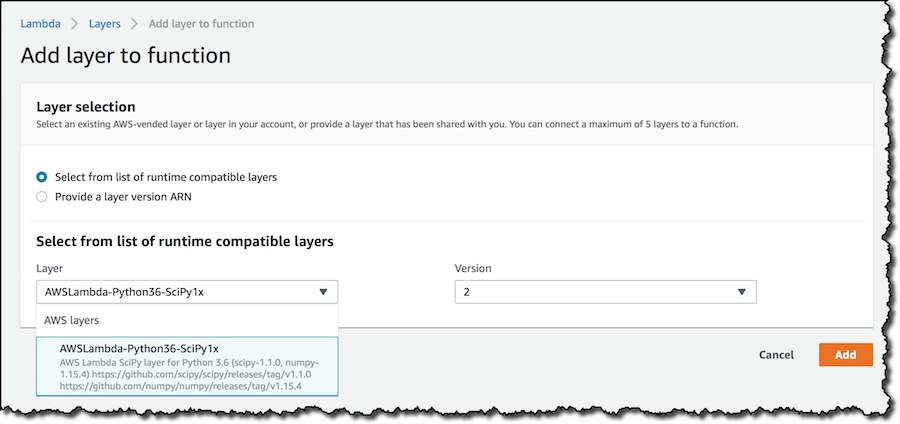
レイヤを追加した後、Saveをクリックし関数のアップデートを行います。1つ以上のレイヤを利用する場合、ここでコードにマージするための順番を調整することができます。

関数内でレイヤを利用するために機能を importする必要があります。
import numpy as np
from scipy.spatial import ConvexHull
def lambda_handler(event, context):
print("\nUsing NumPy\n")
print("random matrix_a =")
matrix_a = np.random.randint(10, size=(4, 4))
print(matrix_a)
print("random matrix_b =")
matrix_b = np.random.randint(10, size=(4, 4))
print(matrix_b)
print("matrix_a * matrix_b = ")
print(matrix_a.dot(matrix_b)
print("\nUsing SciPy\n")
num_points = 10
print(num_points, "random points:")
points = np.random.rand(num_points, 2)
for i, point in enumerate(points):
print(i, '->', point)
hull = ConvexHull(points)
print("The smallest convex set containing all",
num_points, "points has", len(hull.simplices),
"sides,\nconnecting points:")
for simplex in hull.simplices:
print(simplex[0], '<->', simplex[1])
関数を実行することで以下のログが表示されます、いくつかの興味深い結果を見ることができます。
第一に、私はNumPyを行列演算のために使っています。(ニューラルネットワークの入力、出力、および重みを表すために行列とベクトルがよく使われます。)

次に、SciPyの先進的な空間アルゴリズムを使用して、自分で構築することが非常に難しいものを計算します。平面上の点のリストを含む最小の「convex set(凸集合)」を見つけます、 たとえば、複数の地理的な場所(建物、顧客の場所、またはデバイスに対応)からのイベントを受け取るLambda関数で、これを視覚的に「グループ化」して、効率的な方法でより複雑なイベントを生成することができます。

私がこの例を作成する際に、追加インストールやパッケージの依存関係はありませんでした。私はすばやくコードのイテレーションを行うことができました。大きなライブラリやモジュールなどがないのでデプロイもとても早く行うことができました。
SciPyの結果を可視化するために、追加のmatlotlibをimportすることも私は簡単に行えました。数行の追加を行い、私はAmazon Simple Storage Service(S3)に”convex set”がどのようになっているを示す点を示す画像をアップロードできます。
plt.plot(points[:,0], points[:,1], 'o')
for simplex in hull.simplices:
plt.plot(points[simplex, 0], points[simplex, 1], 'k-')
img_data = io.BytesIO()
plt.savefig(img_data, format='png')
img_data.seek(0)
s3 = boto3.resource('s3')
bucket = s3.Bucket(S3_BUCKET_NAME)
bucket.put_object(Body=img_data, ContentType='image/png', Key=S3_KEY)
plt.close()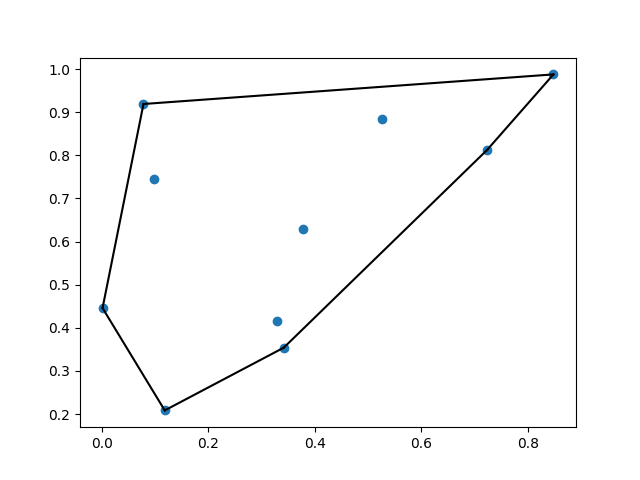
Lambda Runtime API
関数をアップデートする際に、カスタムランタイムの設定が可能になりました。

この選択で、関数は必ずbootstrapと呼ばれる実行ファイルを含む(コードもしくはレイヤ内)必要があります。bootstrapはあなたの関数(どんな言語で書かれたものでも)とLmabda環境の通信に責務を持ちます。
このランタイムbootstrapは単純なHTTPベースのインターフェースでevent payloadを新しいLambdaの呼び出しに通知するのと、関数からのレスポンスを受け取ります。インターフェースのエンドポイント情報とファンクションハンドラーは環境変数として共用されます。
あなたの関数を実行するために、Lmabdaの実行環境でできることすべてが可能です、例えばあなたの選択した言語のインタープリターを持ちこむこともできます。
もしあなたが、あなたのランタイムのAPI管理、公開をしたいのであれば、あなたはランタイムAPIがどのように動くかを知るだけでよいのです。開発者としてランタイムを使うのであればレイヤとして共有されているものを使えば良いです。
以下のオープンソースランタイムが間もなく利用可能になります。
- C++
- Rust
また、パートナーとオープンソースランタイムについて協業しています。
- Erlang(Alert Logic)
- Elixir(ALert Logic)
- Cobol(Blu Age)
- N|Solid (nodeSource)
- PHP (Stackery)
ランタイムAPIは将来、Lambdaで新しい言語をサポートする方法でもあります。 たとえば、これでRuby対応が構築されました。
利用可能
runtimesとLayersはLambdaが提供されているすべてのリージョンでコンソールもしくはAWS Command Line Interface(CLI)で利用可能です。そしてAWS Serverless Application Model(SAM)とSAM CLIも利用することができます。
このruntimes/Layersの機能には追加のコストが発生しません。Layersで利用するストレージはAWS Lambdaのリージョンごとの関数のストレージ制限に含まれます。
Runtime APIとLambda Layersについてもっと学びたい方は、webinarをお見逃しなく。
12/11に、プリンシパル デベロッパーアドヴォケート Chirs Munnsによるホストで開催されます。
この新機能に私は興奮しています。皆様が、次に開発してほしいものについてぜひ教えてください。
著者:

Danilo Poccia
Daniloはあらゆる規模のスタートアップ企業の支援をしています。Amazon Web Servicesのエバンジェリストのロールを担い、サーバレスアーキテクチャやイベント駆動型プログラミング、機械学習やエッジコンピューティング技術にフォーカスをあてた活動をしています。AWS Lambda in Manningの作者であります。
飜訳はSA 小梁川が担当しました。原文はこちら