
Sold by: cloudimg
Deployed on AWS
Free Trial
AWS Free Tier
This product has charges associated with it for seller support. Private GPU-accelerated LLM endpoint running in minutes. Ollama preinstalled with NVIDIA drivers, nginx auth proxy, and OpenAI-compatible API - no manual setup required.
Overview
This is a repackaged open source software product wherein additional charges apply for cloudimg support services.
Why This Image
Deploying Ollama on a GPU instance manually means installing NVIDIA drivers, configuring systemd services, setting up a reverse proxy, adding authentication, and provisioning storage for model weights. Most open-source Ollama deployments ship with no authentication, no proxy, and no separated storage - leaving you to handle production hardening yourself. This image eliminates that operational burden: launch the instance and your private, authenticated LLM endpoint is serving requests within minutes, with no manual driver installation, no proxy configuration, and no default credentials.
Overview
Ollama is the easiest way to run open large language models locally. It downloads, quantizes, and serves models such as Llama, Mistral, Gemma, Phi, Qwen, and DeepSeek with a single command, exposing a REST API that is also OpenAI chat-completions compatible. This image delivers Ollama fully installed and configured as a system service on an NVIDIA GPU instance, so a private, self-hosted LLM endpoint is running within minutes of launch. The current release available is Ollama 0.30.
GPU Accelerated
This image is built and shipped for NVIDIA GPU instances (g4dn, g5, g6 families). The NVIDIA datacenter driver is preinstalled and verified on real hardware during the build, and Ollama auto-detects the GPU to offload model inference, delivering far higher throughput than CPU. Launch on a GPU instance type and your models run on the GPU out of the box.
Application Stack
Ollama runs as an unprivileged service account on the loopback address, with an nginx reverse proxy fronting it on port 80. A systemd service starts the server on boot and restarts it on failure. Model weights live on a dedicated, independently resizable storage volume kept separate from the operating system disk, and a small starter model is pre-pulled so the API responds immediately.
Secure By Default
Ollama ships with no built-in authentication, so access is gated by HTTP Basic Authentication at the nginx reverse proxy. This image generates a fresh password, unique to your instance, on its first boot and writes it to a root-only file. The public version endpoint stays open for load balancers; model pull, generate, chat, and the OpenAI-compatible endpoints all require the password. No shared or default credentials ship in the image.
Ready To Use
Pull a model with'ollama pull', chat from the CLI, or call the REST and OpenAI-compatible endpoints from LangChain, LlamaIndex, or any OpenAI SDK by pointing base_url at your instance. Use Ollama as a drop-in private LLM backend for your own applications.
Use Cases
- A private, self-hosted LLM endpoint in your own VPC for teams with data residency or compliance requirements - no data leaves your account
- GPU-accelerated inference for Llama, Mistral, Gemma, Qwen, and DeepSeek
- A drop-in OpenAI-compatible backend for RAG and agent applications
- Offline and air-gapped LLM serving
cloudimg Support
24/7 technical support by email and live chat. Our engineers help with Ollama deployment, model selection, GPU sizing, quantization, the OpenAI-compatible API, TLS termination, and scaling. Critical issues receive a one-hour average response.
All product and company names are trademarks or registered trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.
Highlights
- Production-ready in minutes, not hours: Ollama preinstalled as a systemd service behind an nginx reverse proxy on port 80 with an OpenAI-compatible REST API. Unlike bare Ollama deployments, this image handles NVIDIA driver installation, service configuration, storage provisioning, and authentication setup so you skip the manual hardening that self-deployment requires. A starter model is pre-pulled so the API responds immediately after launch.
- GPU-accelerated inference out of the box: NVIDIA datacenter driver preinstalled and verified on real hardware during the build. Ollama auto-detects the GPU on g4dn, g5, and g6 instances to offload model inference, delivering far higher throughput than CPU without any driver installation or configuration on your part. Launch on a GPU instance and start serving models immediately.
- Secure by default with 24/7 expert support: HTTP Basic Authentication gates every sensitive endpoint with a unique password generated per instance on first boot - no shared or default credentials ever ship. Model weights live on a dedicated storage volume separate from the OS disk. cloudimg provides 24/7 technical support by email and live chat with one-hour average response for critical issues, covering deployment, GPU sizing, model selection, and scaling.
Details
Sold by
Delivery method
Delivery option
64-bit (x86) Amazon Machine Image (AMI)
Latest version
Operating system
Ubuntu 24.04
Deployed on AWS
New
Introducing multi-product solutions
You can now purchase comprehensive solutions tailored to use cases and industries.

Features and programs
Financing for AWS Marketplace purchases
AWS Marketplace now accepts line of credit payments through the PNC Vendor Finance program. This program is available to select AWS customers in the US, excluding NV, NC, ND, TN, & VT.

Pricing
Free trial
Try this product free for 7 days according to the free trial terms set by the vendor. Usage-based pricing is in effect for usage beyond the free trial terms. Your free trial gets automatically converted to a paid subscription when the trial ends, but may be canceled any time before that.
Pricing is based on actual usage, with charges varying according to how much you consume. Subscriptions have no end date and may be canceled any time. Alternatively, you can pay upfront for a contract, which typically covers your anticipated usage for the contract duration. Any usage beyond contract will incur additional usage-based costs.
Additional AWS infrastructure costs may apply. Use the AWS Pricing Calculator to estimate your infrastructure costs.
If you are an AWS Free Tier customer with a free plan, you are eligible to subscribe to this offer. You can use free credits to cover the cost of eligible AWS infrastructure. See AWS Free Tier for more details. If you created an AWS account before July 15th, 2025, and qualify for the Legacy AWS Free Tier, Amazon EC2 charges for Micro instances are free for up to 750 hours per month. See Legacy AWS Free Tier for more details.
Dimension | Description | Cost/hour |
|---|---|---|
g4dn.xlarge Recommended | g4dn.xlarge | $0.12 |
t2.micro | t2.micro instance type | $0.04 |
t3.micro | t3.micro instance type | $0.04 |
c6i.16xlarge | c6i.16xlarge instance type | $0.24 |
i3en.large | i3en.large instance type | $0.08 |
vt1.24xlarge | vt1.24xlarge instance type | $0.24 |
m7a.4xlarge | m7a.4xlarge instance type | $0.24 |
c7i.48xlarge | c7i.48xlarge instance type | $0.24 |
g6e.16xlarge | g6e.16xlarge instance type | $0.24 |
i7ie.metal-24xl | i7ie.metal-24xl instance type | $0.24 |
Vendor refund policy
Refunds available on request.

Legal
Vendor terms and conditions
Upon subscribing to this product, you must acknowledge and agree to the terms and conditions outlined in the vendor's End User License Agreement (EULA) .
Content disclaimer
Vendors are responsible for their product descriptions and other product content. AWS does not warrant that vendors' product descriptions or other product content are accurate, complete, reliable, current, or error-free.
Delivery details
64-bit (x86) Amazon Machine Image (AMI)
Amazon Machine Image (AMI)
An AMI is a virtual image that provides the information required to launch an instance. Amazon EC2 (Elastic Compute Cloud) instances are virtual servers on which you can run your applications and workloads, offering varying combinations of CPU, memory, storage, and networking resources. You can launch as many instances from as many different AMIs as you need.
Version release notes
Initial release of Ollama 0.30 for GPU-accelerated local LLM inference.
Additional details
Usage instructions
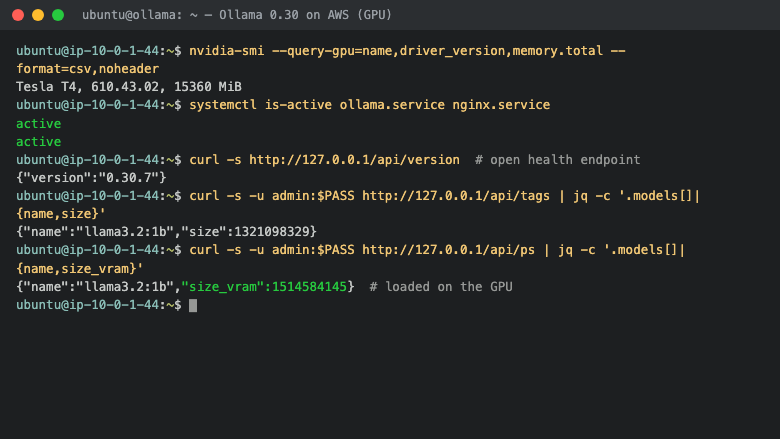
Launch on an NVIDIA GPU instance type (g4dn.xlarge or larger). Connect via SSH on port 22 as the default login user for your operating system variant (the user guide lists it per variant; on Ubuntu it is 'ubuntu'). Ollama is served by nginx on port 80. Retrieve the generated password with: sudo cat /root/ollama-credentials.txt. The version endpoint is open at http://<instance-public-ip>/api/version; everything else is gated by HTTP Basic Authentication (user 'admin' + the password). Pull a model: curl -u admin:<password> http://<instance-public-ip>/api/pull -d '{"name":"llama3.2:3b"}'. Generate: curl -u admin:<password> http://<instance-public-ip>/api/generate -d '{"model":"llama3.2:1b","prompt":"Hello","stream":false}'. Use the OpenAI-compatible endpoint at http://<instance-public-ip>/v1/chat/completions with the same basic-auth credentials. The server runs on loopback 127.0.0.1:11434 and is managed with systemctl (ollama.service, nginx.service). Models are stored under /var/lib/ollama/models. Confirm GPU offload with: ollama ps (size_vram greater than zero). The user guide covers pulling models, the OpenAI SDK, GPU sizing, backups and enabling HTTPS.
Resources
Vendor resources
Support
Vendor support
cloudimg provides 24/7 technical support for this product by email and live chat.
What is covered:
- Ollama deployment and configuration
- Model selection and GPU sizing guidance
- Quantization and performance tuning
- OpenAI-compatible API integration
- TLS termination and scaling
- Troubleshooting and updates
Response times:
Critical issues receive a one-hour average response. Our engineers work with you through resolution, including configuration changes, service restarts, and upgrade assistance.
How to get help:
Email: support@cloudimg.co.uk Live chat: Available 24/7
For refund requests or billing questions, contact support@cloudimg.co.uk with your AWS account ID and instance details.
AWS infrastructure support
AWS Support is a one-on-one, fast-response support channel that is staffed 24x7x365 with experienced and technical support engineers. The service helps customers of all sizes and technical abilities to successfully utilize the products and features provided by Amazon Web Services.
Similar products

This product has charges associated with it for support. Ollama is a cutting-edge AI tool that empowers users to set up and run large language models, such as Llama 2 and 3, directly on their local machines. This innovative solution caters to a wide range of users, from experienced AI professionals to enthusiasts, enabling them to explore natural language processing without depending on cloud-based services.

This product has charges associated with it for seller support. This image comes with the following softwares: Ollama and Open Webui
This is a repackaged software product wherein additional charges apply for seller maintenance.
Deploy a powerful, self-hosted AI server supporting multiple LLMs (including Deepseek) via Open WebUI and Ollama. Streamline AI inference, customization, and local model management in a scalable AWS environment.

Deploy Open WebUI instantly with a preconfigured AMI for self hosted AI chat, LLM interaction, and collaborative AI workflows. This platform provides a modern web interface for large language models with secure access, customizable deployment, and scalable infrastructure for teams and developers.

This product has charges associated with it for seller support. This image comes with a prebuilt Ubuntu 26.04 AMI for private local LLM experimentation on EC2 with Ollama, Open WebUI, and a small preloaded validation model.
Customer reviews
No customer reviews yet
Be the first to review this product . We've partnered with PeerSpot to gather customer feedback. You can share your experience by writing or recording a review, or scheduling a call with a PeerSpot analyst.