O blog da AWS
Como o Verizon Media Group migrou do Apache Hadoop e do Spark on-premisses para o Amazon EMR
Esta é uma postagem de convidados do Verizon Media Group
No Verizon Media Group (VMG), um dos principais problemas que enfrentamos era a incapacidade de dimensionar a capacidade de computação em um período de tempo necessário — as aquisições de hardware demoravam meses para serem concluídas. A escalabilidade e o upgrade do hardware para acomodar alterações na carga de trabalho não eram economicamente viáveis, e a atualização de softwares de gerenciamento redundantes exigia tempos de inatividade significativos e apresentava grandes riscos.
No VMG, dependemos de tecnologias como o Apache Hadoop e o Apache Spark para executar nossos pipelines de processamento de dados. Antes, gerenciávamos nossos clusters com o Cloudera Manager, que estava sujeito a ciclos de lançamento lentos. Como resultado, executávamos versões mais antigas de versões de código aberto disponíveis e não conseguíamos aproveitar as últimas correções de bugs e melhorias de desempenho em projetos do Apache. Esses motivos, combinados com nosso investimento já existente na AWS, nos fizeram explorar a migração dos nossos pipelines de computação distribuída para o o Amazon EMR.
O Amazon EMR é uma plataforma de cluster gerenciado que simplifica a execução de estruturas de big data, como o Apache Hadoop e o Apache Spark.
Esta postagem discute os problemas que encontramos e resolvemos ao criar um pipeline para atender às nossas necessidades de processamento de dados.
Sobre nós
O Verizon Media é, em última análise, uma empresa de publicidade online. A maioria da publicidade online hoje é feita por meio de exibição de Ads, também conhecidos como banners ou anúncios em video. Independentemente do formato, todos os anúncios da Internet geralmente acionam vários tipos de beacons para servidores de rastreamento, que são geralmente implantações de servidores Web altamente escaláveis com a responsabilidade exclusiva de registrar beacons recebidos em um ou vários coletores de eventos.
Arquitetura do pipeline
No nosso grupo, que lida principalmente com publicidade em vídeo, usamos servidores web NGINX implantados em vários locais geográficos, que registram eventos disparados do nosso player de vídeo diretamente no Apache Kafka para processamento em tempo real e no Amazon S3 para processamento em lote. Um pipeline de dados típico em nosso grupo envolve processar esses feeds de entrada, aplicar rotinas de validação e enriquecimento, agregar dados resultantes e replicá-los para outros destinos para fins de geração de relatórios. O diagrama a seguir mostra um pipeline típico que criamos.
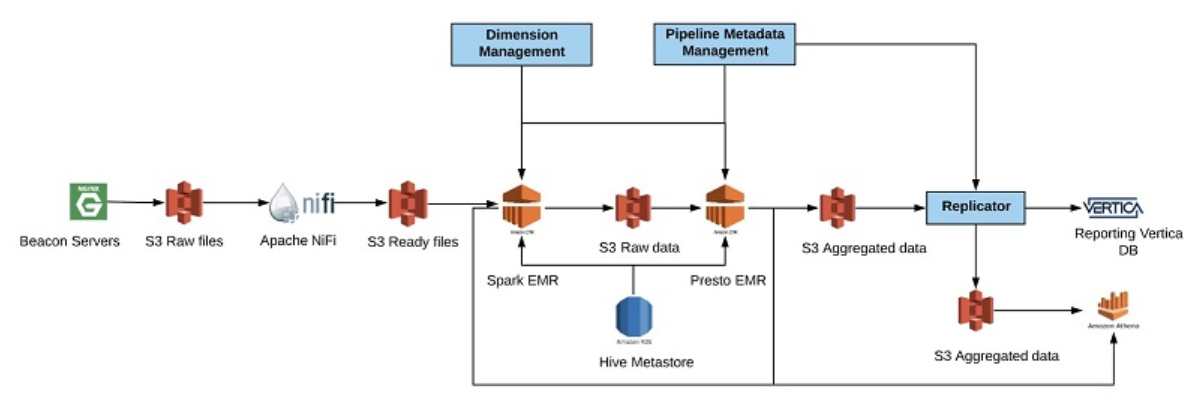
Começamos com a obtenção de dados em nossos servidores de beacons NGINX. Esses dados são armazenados em intervalos de 1 minuto no disco local em arquivos gzip. A cada minuto, movemos os dados dos servidores NGINX para a área de dados brutos no S3. Ao chegar no S3, o arquivo envia uma mensagem ao Amazon SQS. O Apache NiFi está ouvindo mensagens do SQS para começar a trabalhar em arquivos. Durante esse tempo, o NiFi agrupa arquivos menores em arquivos maiores e armazena o resultado em um caminho especial em um local temporário no S3. O nome do caminho é combinado usando um timestamp inverso para garantir que os dados sejam armazenados em um local aleatório para evitar gargalos de leitura.
A cada hora, escalamos um cluster Spark no Amazon EMR para processar os dados brutos. Esse processamento inclui enriquecer e validar os dados. Esses dados são armazenados em uma pasta de localização permanente no S3, em um formato de coluna do Apache ORC. Também atualizamos o Catálogo de dados do AWS Glue para expor esses dados no Amazon Athena caso precisemos investigá-lo em busca de problemas. Após a conclusão do processamento dos dados brutos, reduzimos a escala do cluster do Spark EMR e começamos a agregar dados com base em modelos de agregação predefinidos usando o Presto no Amazon EMR. Os dados agregados são armazenados no formato ORC em um local especial no S3 para dados agregados.
Também atualizamos nosso Catálogo de dados com a localização dos dados, para que possamos consultá-los com o Athena. Além disso, replicamos os dados do S3 no Vertica para que nossos relatórios exponham os dados a clientes internos e externos. Nesse cenário, usamos o Athena como a solução de recuperação de desastres (DR) para o Vertica. Todas as vezes que nossa plataforma de relatórios percebe que o Vertica está com problemas, fazemos automaticamente o failover para o Amazon Athena. Essa solução provou ser extremamente rentável para nós. Temos outro caso de uso para o Athena em nossa análise em tempo real que não discutimos nesta postagem.
Desafios da migração
A migração para o Amazon EMR exigiu que fizéssemos algumas alterações de design para obter os melhores resultados. Ao executarmos pipelines de big data na nuvem, a otimização de custos operacionais é o nome do jogo. Os dois principais custos são os de armazenamento e computação. Em warehouses Hadoop tradicionais locais, eles são acoplados como nós de armazenamento, que também servem como nós de computação. A desvantagem desse acoplamento é que quaisquer alterações na camada de armazenamento, como uma manutenção, também podem afetar a camada computacional. Em um ambiente como a AWS, podemos dissociar armazenamento e computação usando o S3 para armazenamento e o Amazon EMR para computação. Isso oferece uma grande vantagem de flexibilidade ao lidar com a manutenção dos clusters, pois todos os clusters são efêmeros.
Para economizar ainda mais custos, tivemos que descobrir como alcançar o máximo de utilização em nossa camada computacional. Isso significava que tínhamos que mudar nossa plataforma para o uso de vários clusters para diferentes pipelines, em cada cluster é dimensionado automaticamente dependendo das necessidades do pipeline.
Migração para o S3
A execução de um data warehouse do Hadoop no S3 apresenta considerações adicionais. O S3 não é um sistema de arquivos como o HDFS e não fornece as mesmas garantias imediatas de consistência. Você pode considerar o S3 como um armazenamento de objetos eventualmente consistente com uma API REST para acessá-lo.
A renomeação
Uma diferença fundamental com o S3 é que a renomeação não é uma operação atômica. Todas as operações de renomeação no S3 executam uma cópia seguida de uma operação de exclusão. Executar renomeações no S3 não é desejável devido aos custos de tempo de execução. Para usar o S3 de forma eficiente, você deve remover o uso de qualquer operação de renomeação. Renomeações costumam ser usadas em warehouses do Hadoop em vários estágios de confirmação, como mover um diretório temporário para seu destino final como uma operação atômica. A melhor abordagem é evitar quaisquer operações de renomeação e, em vez disso, gravar dados uma vez.
Committers de saída
Ambos os trabalhos do Spark e Apache MapReduce têm estágios de commit que confirmam arquivos de saída produzidos por vários operadores distribuídos para diretórios de saída finais. Explicar como os committers de saída funcionam está além do escopo desta postagem, mas o importante é que os committers de saída padrão projetados para trabalhar no HDFS dependem de operações de renomeação, que, como explicado anteriormente, têm uma penalidade de desempenho em sistemas de armazenamento como o S3. Uma estratégia simples que funcionou para nós foi desabilitar a execução especulativa e mudar a versão do algoritmo do committer de saída. Também é possível gravar seus próprios committers personalizados, que não dependem de renomeações. Por exemplo, a partir do Amazon EMR 5.19.0, a AWS lançou um OutputCommitter personalizado para Spark que otimiza gravações no S3.
Consistência eventual
Um dos principais desafios de se trabalhar com o S3 é que ele é eventualmente consistente, enquanto o HDFS é fortemente consistente. O S3 oferece garantias de leitura após gravação para PUTS de novos objetos, mas isso nem sempre é suficiente para criar pipelines distribuídos consistentes. Um cenário comum que surge muito no processamento de big data é um trabalho gerando uma lista de arquivos para um diretório e outro trabalho lendo a partir desse diretório. Para que o segundo trabalho seja executado, ele precisa listar o diretório para encontrar todos os arquivos que precisa ler. No S3, não há diretórios; simplesmente listamos arquivos com o mesmo prefixo, o que significa que não é possível visualizar todos os novos arquivos logo após a execução do primeiro trabalho.
Para resolver esse problema, a AWS oferece o EMRFS, uma camada de consistência adicionada ao S3 para que ele se comporte como um sistema de arquivos consistente. O EMRFS usa o Amazon DynamoDB e mantém metadados sobre cada arquivo no S3. Em termos simples, com o EMRFS habilitado ao listar um prefixo do S3, a resposta real do S3 é comparada aos metadados no DynamoDB. Se houver uma um descompasso, o driver S3 sondará um pouco mais e aguardará que os dados apareçam no S3.
Em geral, descobrimos que o EMRFS era necessário para garantir a consistência dos dados. Para alguns dos nossos pipelines de dados, usamos o PrestoDB para agregar dados armazenados no S3, onde escolhemos executar o PrestoDB sem suporte ao EMRFS. Embora isso nos tenha exposto ao risco de consistência eventual para nossos trabalhos upstream, descobrimos que podemos contornar esses problemas monitorando discrepâncias entre dados downstream e upstream e refazendo os trabalhos upstream, se necessário. Em nossa experiência, problemas de consistência acontecem muito raramente, mas são possíveis. Se você optar por executar sem o EMRFS, deverá projetar seu sistema de acordo.
Estratégias de escalabilidade automática
Um desafio importante e ainda assim trivial foi descobrir como aproveitar os recursos de escalabilidade automática do Amazon EMR. Para obter os melhores custos operacionais, queremos garantir que nenhum servidor esteja ocioso.
Para isso, a resposta pode parecer óbvia — criar um cluster EMR de longa execução e usar recursos de escalabilidade automática prontamente disponíveis para controlar o tamanho de um cluster com base em um parâmetro, como memória livre disponível no cluster. No entanto, alguns dos nossos pipelines em lote começam a cada hora, funcionam por exatamente 20 minutos e são muito intensos em termos de computação. Como o tempo de processamento é muito importante, queremos ter certeza de que não perdemos tempo. A estratégia ideal para nós é redimensionar o cluster preventivamente por meio de scripts personalizados antes que determinados pipelines em lote muito grandes sejam iniciados.
Além disso, seria difícil executar vários pipelines de dados em um único cluster e tentar mantê-lo com a capacidade ideal em qualquer momento, pois cada pipeline é um pouco diferente. Em vez disso, optamos por executar todos os nossos principais pipelines em clusters do EMR independentes. Isso tem muitas vantagens e apenas uma pequena desvantagem. As vantagens são que cada cluster pode ser redimensionado exatamente no tempo necessário, executar a versão de software exigida por seu pipeline e ser gerenciado sem afetar outros pipelines. A desvantagem secundária é que há uma pequena quantidade de desperdício computacional ao executar nós extra para trabalho e coordenação dos jobs.
Ao desenvolver uma estratégia de escalabilidade automática, primeiro tentamos criar e eliminar clusters sempre que precisamos executar nossos pipelines. No entanto, descobrimos rapidamente que o bootstrapping de um cluster a partir do zero pode demorar mais tempo do que gostaríamos. Em vez disso, mantemos esses clusters sempre em execução e aumentamos o cluster adicionando nós de tarefas antes que o pipeline seja iniciado e removemos esses nós de tarefas assim que o pipeline é encerrado. Descobrimos que com a simples adição de nós de tarefas, podemos começar a executar nossos pipelines muito mais rápido. Se nos depararmos com problemas com clusters de longa execução, poderemos reciclar rapidamente e criar um novo a partir do zero. Continuamos trabalhando com a AWS nesses problemas.
Nossos scripts personalizados de escalabilidade automática são scripts Python simples, que geralmente são executados antes de um pipeline começar. Por exemplo, suponha que nosso pipeline consista em um trabalho MapReduce simples com uma única fase de map e reduce. Também suponha que a fase de mapeamento seja mais cara em termos computacionais. Podemos escrever um script simples que analise a quantidade de dados que precisam ser processados na próxima hora e descubra a quantidade de mapeadores que são necessários para processar esses dados da mesma maneira que um trabalho Hadoop faz. Quando sabemos a quantidade de tarefas de mapeamento, podemos decidir em quantos servidores queremos executar todas as tarefas de mapeamento em paralelo.
Ao executar pipelines em tempo real do Spark, as coisas são um pouco mais complicadas, pois às vezes temos que remover recursos computacionais enquanto o aplicativo está em execução. Uma estratégia simples que funcionou para nós é criar um cluster em tempo real separado em paralelo ao existente, dimensioná-lo para um tamanho necessário com base na quantidade de dados processados durante a última hora com uma certa capacidade extra e reiniciar o aplicativo em tempo real no novo cluster.
Custos operacionais
Você pode avaliar todos os custos da AWS antecipadamente com a calculadora do EC2. Os principais custos ao executar pipelines de big data são o armazenamento e a computação, com alguns custos menores extras, como o DynamoDB, ao usar o EMRFS.
Custos de armazenamento
O primeiro custo a considerar é o armazenamento. Como o HDFS tem um fator de replicação padrão de 3, ele exigiria 3 PB de capacidade de armazenamento real em vez de 1 PB.
Armazenar 1 GB no S3 custa ± 0,023 USD por mês. Como o S3 já é altamente redundante, você não precisa levar em conta o fator de replicação, o que reduz nossos custos imediatamente em 67%. Você também deve considerar os outros custos para solicitações de gravação ou leitura, mas estes geralmente tendem a ser pequenos.
Custos de computação
O segundo maior custo após o armazenamento é o custo de computação. Para reduzir os custos de computação, você deve aproveitar os preços de instância reservadas o máximo possível. Um tipo de instância m4.4xlarge com 16 vCPUs na AWS custa 0,301 USD por hora quando reservado por 3 anos, com todas as taxas adiantadas. Uma instância sob demanda custa 0,8 USD por hora, o que é uma diferença de 62% no preço. Isso é mais fácil de alcançar em organizações maiores que realizam o planejamento regular da capacidade. Uma taxa extra por hora de 0,24 USD é adicionada a cada máquina do Amazon EMR para o uso da plataforma do Amazon EMR. É possível reduzir ainda mais os custos usando instâncias Spot do Amazon EC2. Para obter mais informações, consulte Opções de compra de instâncias.
Para obter os custos operacionais ideais, tente garantir que seus clusters de computação nunca estejam ociosos e tente reduzir a escala dinamicamente com base na quantidade de trabalho que seus clusters estão fazendo em qualquer momento.
Considerações finais
Operamos nossos pipelines de big data no Amazon EMR há mais de um ano e armazenamos todos os nossos dados no S3. Às vezes, nossos pipelines de processamento em tempo real atingiram o pico ao lidarem com mais de 2 milhões de eventos por segundo, com uma latência total de processamento desde o evento inicial até agregados atualizados de 1 minuto. Temos aproveitado a flexibilidade do Amazon EMR e sua capacidade de desmontar e recriar clusters em questão de minutos. Estamos satisfeitos com a estabilidade geral da plataforma do Amazon EMR e continuaremos trabalhando com a AWS para melhorá-la ainda mais.
Como mencionamos antes, o custo é um fator importante a considerar, e você pode argumentar que pode ser mais barato executar o Hadoop em seus próprios data centers. No entanto, esse argumento depende da capacidade da sua organização de fazer isso de forma eficiente, pois ele pode ter custos operacionais ocultos, além de reduzir a elasticidade. Sabemos por experiência em primeira mão que a execução on-premisses é um empreendimento que você não deve subestimar e que requer muito planejamento e manutenção. Acreditamos que plataformas como o Amazon EMR trazem muitas vantagens no design de sistemas de big data.
Aviso de isenção: O conteúdo e as opiniões desta postagem são de um autor externo, e a AWS não é responsável pelo conteúdo ou pela precisão da postagem.
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre os autores
 Lev Brailovskiy é Diretor do engenharia que lidera o Grupo de engenharia de serviços da SSP (Supply Side Platform) no Verizon Media. Ele tem mais de 15 anos de experiência em projetar e construir sistemas de software. Nos últimos seis anos, Lev passou tempo projetando, desenvolvendo e executando softwares de processamento de dados e relatórios em grande escala, tanto em data centers privados quanto na nuvem pública.
Lev Brailovskiy é Diretor do engenharia que lidera o Grupo de engenharia de serviços da SSP (Supply Side Platform) no Verizon Media. Ele tem mais de 15 anos de experiência em projetar e construir sistemas de software. Nos últimos seis anos, Lev passou tempo projetando, desenvolvendo e executando softwares de processamento de dados e relatórios em grande escala, tanto em data centers privados quanto na nuvem pública.
 Zilvinas Shaltys é líder técnico da plataforma de data warehouse na nuvem de Video Syndication da Verizon. Zilvinas tem vários anos de experiência de trabalho com uma ampla variedade de tecnologias de big data implantadas em escala considerável. Ele foi responsável pela migração de pipelines de big data dos data centers da AOL para o Amazon EMR. Zilvinas está atualmente trabalhando para melhorar a estabilidade e a escalabilidade dos sistemas de big data existentes em lote e em tempo real.
Zilvinas Shaltys é líder técnico da plataforma de data warehouse na nuvem de Video Syndication da Verizon. Zilvinas tem vários anos de experiência de trabalho com uma ampla variedade de tecnologias de big data implantadas em escala considerável. Ele foi responsável pela migração de pipelines de big data dos data centers da AOL para o Amazon EMR. Zilvinas está atualmente trabalhando para melhorar a estabilidade e a escalabilidade dos sistemas de big data existentes em lote e em tempo real.
|
|
Use seus dados para impulsionar o crescimento do negócio. Inove continuamente usando o data flywheel
|
