What is Synthetic Data?
Page topics
What is synthetic data?
Synthetic data is data generated by an algorithm rather than observed from real-world measurements, for example by generative AI technologies. A synthetic data set has the same mathematical properties as the actual data it is based on, but only for information that is permitted to be inferred especially when based on the source data's labeling. Organizations use synthetic data for research, testing, new development, and machine learning research. Recent innovations in AI have made synthetic data generation efficient and fast but have also increased its importance in data regulatory concerns.
What are the benefits of synthetic data?
Synthetic data offers several benefits to organisations. We go through some of these below.
Unlimited data generation
You can produce synthetic data on demand and at an almost unlimited scale. Synthetic data generation tools are a cost-effective way of getting more data. They can also pre-label (categorise or mark) the data they generate for machine learning use cases. You get access to structured and labeled data without going through the process of transforming raw data from scratch. You can also add synthetic data to the total volume of data that you have, yielding more training data for analysis.
Privacy protection
Fields like healthcare, finance, and the legal sector have many privacy, copyright, and compliance regulations to protect sensitive data. However, they must use data for analytics and research—often having to outsource data to third parties for maximum utilization. Instead of personal data, they can use synthetic data to serve the same purpose as these private datasets. They create similar data that shows the same statistically relevant information without exposing private or sensitive data. Consider medical research creating synthetic data from a live data set— the synthetic data maintains the same percentage of biological characteristics and genetic markers as the original data set, but all names, addresses, and other personal patient information is fake.
Bias reduction
You can use synthetic data to reduce bias in AI training models. As large models typically train on publicly available data, there can be bias in the text. Researchers can use synthetic data to provide a contrast to any biased language or information that AI models collect. For example, if certain opinion-based content is favoring a particular group, you can create synthetic data to balance out the overall dataset.
What are the types of synthetic data?
There are two main types of synthetic data—partial and full.
Partial synthetic data
Partially synthetic data replaces a small portion of a real dataset with synthetic information. You can use it to protect sensitive parts of a dataset. For example, if you need to analyze customer-specific data, you can synthesize attributes like name, contact details, and other real-world information that someone could trace back to a specific person.
Full synthetic data
Full synthetic data is where you completely generate new data. A fully synthetic dataset will not contain any real-world data. However, it will use the same relationships, plot distributions, and statistical properties as real data. While this data doesn’t come from actual recorded data, it allows you to make the same conclusions.
You can use fully synthetic data when testing machine learning models. It is useful when you want to test or create new models but dont have sufficient real-world training data for improved ML accuracy.
How is synthetic data generated?
Synthetic data generation involves the use of computational methods and simulations to create data. The result mimics the statistical properties of real-world data, but does not contain actual real-world observations. This generated data can take various forms, including text, numbers, tables, or more complex types like images and videos. Additionally, synthetic data sets generated from multiple data sources also mimic the statistical properties of real-world data and do not contain actual real-world observations, however, instances (records, rows) can be composed of the original attributes. There are three main approaches to generating synthetic data, each offering different levels of data accuracy and types.
Statistical distribution
In this approach, real data is first analyzed to identify its underlying statistical distributions, such as normal, exponential, or chi-square distributions. Data scientists then generate synthetic samples from these identified distributions to create a dataset that statistically resembles the original.
Model-based
In this approach, a machine learning model is trained to understand and replicate the characteristics of the real data. Once the model has been trained, it can generate artificial data that follows the same statistical distribution as the real data. This approach is particularly useful for creating hybrid datasets, which combine the statistical properties of real data with additional synthetic elements.
Deep learning methods
Advanced techniques like Generative adversarial networks (GANs), variational autoencoders (VAEs), and others can be employed to generate synthetic data. These methods are often used for more complex data types—like images or time-series data—and can produce high-quality synthetic datasets.
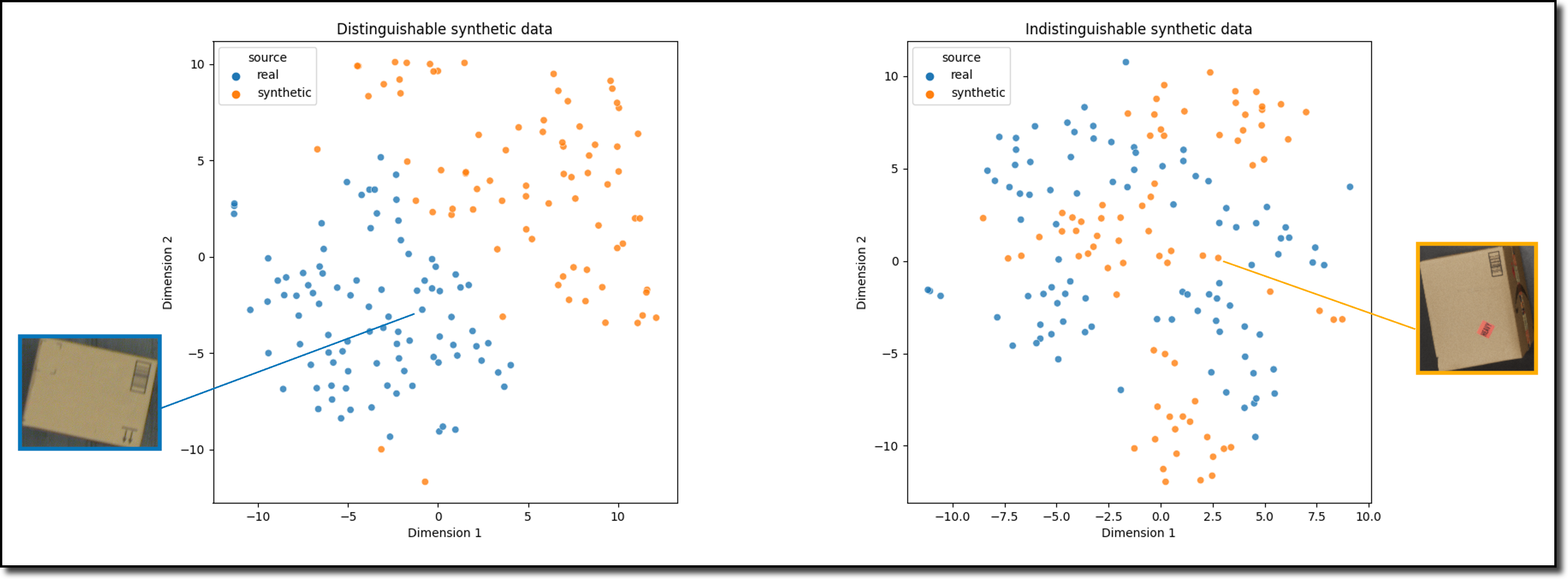
What are synthetic data generation technologies?
We outline some advanced technologies that you can use for synthetic data generation below.
Generative adversarial network
Generative adversarial network (GAN) models use two neural networks that work together to generate and classify new data. One uses raw data to produce synthetic data while the second evaluates, characterizes, and classifies that information. Both networks compete with each other until the evaluating network can no longer differentiate between the synthetic data and original data.
You can use GAN to create artificially generated data that is highly naturalistic and closely presents variations of real-world data, like realistic-looking videos and images.
Read about generative adversarial networks (GAN) »
Variational auto-encoders
Variational auto-encoders (VAE) are algorithms that generate new data based on representations of original data. The unsupervised algorithm learns the distribution of the raw data, then uses encoder-decoder architecture to generate new data via a double transformation. The encoder compresses the input data into a lower-dimensional representation, and the decoder reconstructs new data from this latent representation. The model uses probabilistic calculations for smooth re-creations.
VAE is most useful when generating very similar synthetic data with variations. For example, you can use VAE when generating new images.
Transformer-based models
Generative pre-trained transformers or GPT-based models use large original datasets to understand the structure and typical distribution of data. You mainly use them in natural language processing (NLP) generation. For instance, if a transformer-based text model is trained on a large dataset of English text, it learns the structure, grammar, and even the nuances of the language. When generating synthetic data, the model starts with a seed text (or prompt) and predicts the next word based on the probabilities it has learned, generating a complete sequence.
What are the challenges in synthetic data generation?
There are several challenges when creating synthetic data. Below are some general limitations and challenges you will likely experience with synthetic data.
Quality control
Data quality is vital in statistics and analytics. Before you incorporate synthetic data into learning models, you must check that it is accurate and has a minimum level of data quality. However, ensuring that no-one can trace synthetic data points back to real information may require a reduction in accuracy. A trade-off in privacy and accuracy could impact quality.
You can perform manual checks of synthetic data before you use it, which can help to overcome this issue. However, manually checking can become time-consuming if you need to generate lots of synthetic data.
Technical challenges
Creating synthetic data is difficult—you must understand techniques, rules, and current methods to ensure its accuracy and utility. You need high expertise in this field before you’ll be generating any useful synthetic data.
No matter how much expertise you have on your side, it is challenging to generate synthetic data as a perfect imitation of its real-world counterpart. For instance, real-world data often includes outliers and anomalies that synthetic data generation algorithms can rarely recreate.
Stakeholder confusion
Although synthetic data is a useful supplementary tool, not all stakeholders may understand its importance. As a more recent technology, some business users may not accept synthetic data analytics as having real-world relevance. On the flip side, others may over-emphasise the results due to the controlled aspect of generation. Communicate the limits of this technology and its outcomes to stakeholders, making sure they understand both benefits and shortfalls.
How can AWS support your synthetic data generation efforts?
Amazon SageMaker is a fully managed service used to prepare data and build, train, and deploy machine learning (ML) models. These models are suitable for any use case, with fully managed infrastructure, tools, and workflows. SageMaker offers two options that enable you to label raw data—such as images, text files, and videos—and generate labeled synthetic data to create high-quality datasets for training ML models.
-
Amazon SageMaker Ground Truth is a self-service offering that makes it easy to label data. It gives you the option to use human annotators through Amazon Mechanical Turk, third-party vendors, or your own private workforce.
-
Amazon SageMaker Ground Truth Plus is a fully managed service that allows you to create high-quality training datasets. You don’t have to build labeling applications or manage labeling workforces on your own.
First, you specify your synthetic image requirements or provide 3D assets and baseline images, such as computer-aided design (CAD) images. AWS digital artists then create images from scratch or use customer-provided assets. The generated images imitate pose and placement of objects, include object or scene variations, and optionally add specific inclusions—such as scratches, dents, and other alterations. This eliminates the time-consuming process of collecting data or the need to damage parts to acquire images. You can generate hundreds of thousands of synthetic images that are automatically labeled with high accuracy.
AWS Clean Rooms ML helps you and your partners apply privacy-enhancing machine learning (ML) to generate predictive insights without having to share raw data with each other. With AWS Clean Rooms ML custom modeling, you and your partners can generate statistically representative synthetic datasets from your collective data to train regression and classification ML models without revealing sensitive information from the original data.
Get started with synthetic data generation on AWS by creating a free account today.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages