AWS Partner Network (APN) Blog
How Genpact is Innovating the Data-Driven Finance Office
By Subrahmanyam Madduru, Global Partner Solutions Architect – AWS
By Sarvottam Darshan, Director, Data Services – Genpact LLC
By Jignesh Desai, Global Migration Partner Solutions Architect – AWS
 |
| Genpact |
 |
According to a recent Genpact report titled CFOs Empowering Enterprises in the Age of Instinct, 82% of CEOs believe the role of the Chief Financial Officer will increase in importance over the next three to five years.
For CFOs, this calls for an overdue transformation—from fiscal protector to champion of innovation and growth. For finance teams, this means accelerating the speed at which they turn data into insight and insight into action.
Forward-looking finance teams will build resilience and responsiveness to future disruption, while developing business partnerships internally and externally to lower costs, improve customer experiences, and unlock new opportunities for growth.
To deliver this strategic mandate, finance offices must be data-driven and share insights that help the organization connect, predict, and adapt within a changing business environment.
In this post, we discuss Genpact’s data lake analytics reference architecture and how it can help future-focused finance teams incorporate functional expertise into Amazon Web Services (AWS) cloud solutions with the goal of delivering business impact beyond increased productivity.
Genpact is an AWS Advanced Tier Services Partner with a core strength in domain-driven expertise running back offices for global Fortune 500 companies across the industry spectrum. Genpact helps customers to reinvent thousands of business processes and drive real-world business transformation at scale.
Challenges in Unlocking Business Insights
As a finance office embarks on this transformation, unlocking timely business insights from oceans of data can prove difficult.
There are three main challenges:
- Complex IT infrastructure: Legacy enterprise architectures reliant on multiple systems create operational roadblocks to global transformation.
- Data fragmentation and quality: Lack of systems integration and data standardization across business units and geographies leads to inaccurate and inefficient data collection and auditing.
- Slow and reactive insights: Without cloud-based data and advanced analytics, insight generation is a time-intensive process—often running slower than the needs of the business. Historical data only offers rearview insights and the opportunity for businesses to react.
A radically different approach is needed to connect technology, workforces, and data within finance.
Cloud-based data and analytics can address the above challenges by:
- Integrating enterprise-wide data from multiple sources into a central cloud-based data lake.
- Supporting enterprise-wide automation, artificial intelligence (AI), and analytics within a strong data framework.
- Enabling vast data processing that can be scaled to meet future business needs.
- Increasing speed to insights with a data-driven architecture and cloud culture.
- Increasing agility and responsiveness with AI-driven predictive insights and real-time forecasting.
Genpact’s Approach
Think of it this way—hidden data can generate previously untapped business value.
Consider tail-end spend optimization, contract leakage prevention, working capital optimization, and non-consumer market identification. In the past, these may have received less attention due to the considerable volume and complexity of data processing.
However, functional expertise can connect data and cloud strategy to help finance teams improve business partnerships, reduce costs, deliver insights at speed, and better predict future disruption.
In addition, a scalable AWS Cloud platform can provide business leaders and data scientists with self-service data and analytics capabilities. This requires a framework with clear, actionable steps—a data lake analytics architecture that is baked in with deep domain expertise to generate data-driven insights.
Data-Driven Finance Office Reference Architecture
Genpact, with its experience serving finance offices of Fortune 500 enterprises, has developed a data-driven finance office reference architecture using data lake and analytics consisting of eight logical layers composed of various AWS services.
This architecture allows you to rapidly build data and analytics pipelines, significantly accelerate data onboarding, and generate data-driven insights.
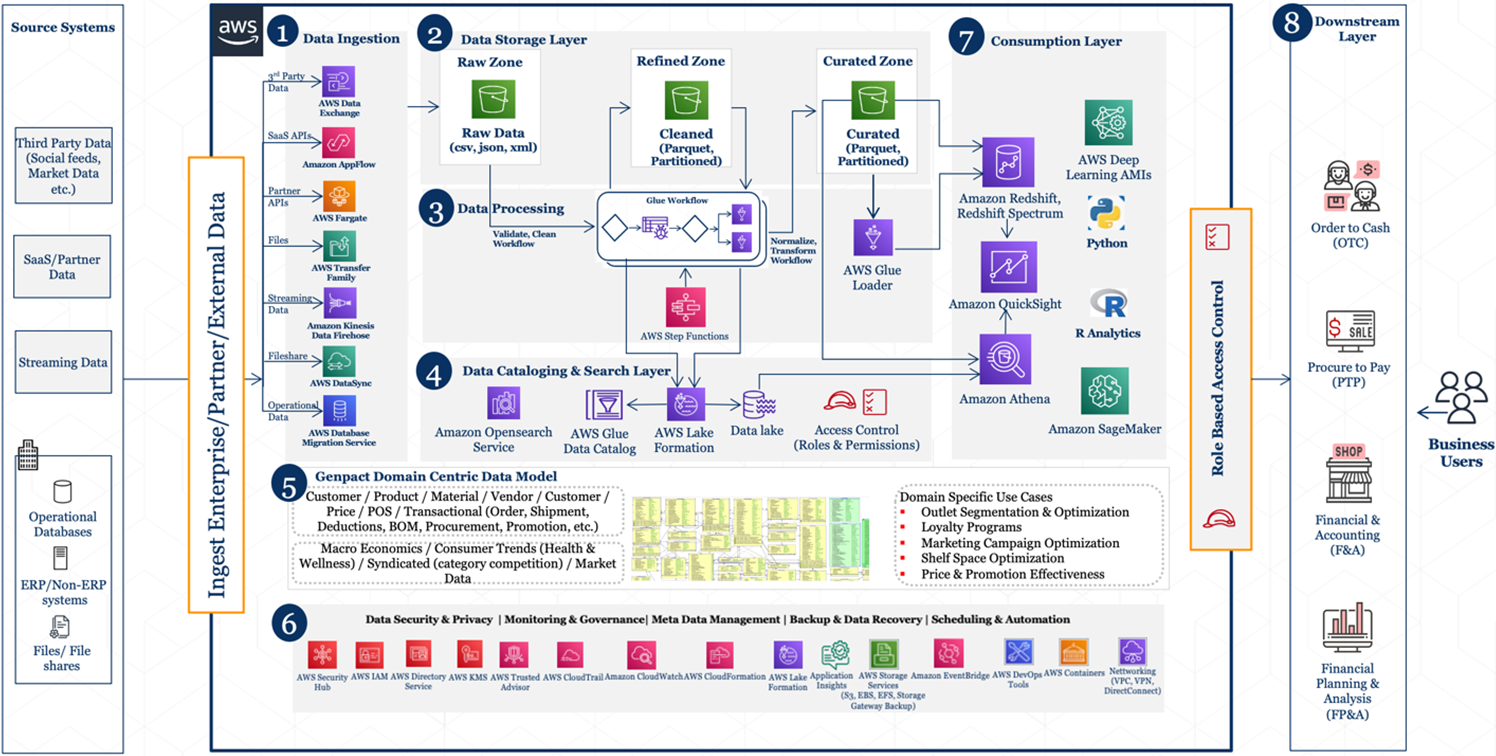
Figure 1 – Reference architecture for a data-driven finance office.
Various components and AWS services act as core building blocks and make up various layers of the reference architecture.
- AWS Data Exchange makes it easy to find, subscribe to, and use third-party data in the cloud from data providers across industries such as financial services, healthcare, retail, media and entertainment, and more.
- Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between software-as-a-service (SaaS) applications and AWS services such as Amazon S3 and Amazon Redshift in just a few clicks.
- Amazon Fargate is a serverless, pay-as-you-go compute engine that lets you focus on building applications without managing servers.
- AWS Transfer Family securely scales your recurring business-to-business file transfers to Amazon S3 and Amazon EFS using SFTP, FTPS, and FTP protocols.
- Amazon Kinesis Data Firehose securely loads streaming data into data lakes, data stores, and analytics services. It can capture, transform, and deliver streaming data to Amazon S3, Amazon Redshift, and other services.
- AWS DataSync is an online data transfer service that simplifies, automates, and accelerates moving data between on-premises storage systems and AWS storage services, as well as between AWS storage services.
- AWS Database Migration Service (AWS DMS) helps you migrate your data into AWS, and then to and from the most widely-used commercial and open-source databases.
- Amazon Simple Storage Service (Amazon S3) is an object storage service to store and protect any amount of data for a range of use cases, such as data lakes, websites, IoT devices, and enterprise applications.
- Amazon OpenSearch Service is a managed service for OpenSearch 1.0 in the AWS Cloud for serving use cases such as log analytics, real-time application monitoring, and click stream analytics.
- AWS Lake Formation sets up a secure data lake defining data sources and what data access and security policies you want to apply.
- AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development.
- AWS Step Functions is a low-code visual workflow service which allows you to express complex business logic as simple event-driven workflows that connect services, systems or people.
- Amazon Athena queries Amazon S3 using standard SQL to analyze data.
- Amazon QuickSight helps visualize and provide insights on the sensor data.
- AWS Deep Learning AMIs provide machine learning practitioners and researchers with the infrastructure and tools to accelerate deep learning in the cloud.
- Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning models quickly by bringing together a broad set of capabilities purpose-built for ML.
Furthermore, data security and privacy capabilities are provided by services such as AWS Security Hub, AWS Identity Access Management (IAM), AWS Directory Service, AWS Key Management Service (KMS), and AWS Trusted Advisor.
Infrastructure monitoring, governance, and observability can be achieved through AWS CloudTrail, Amazon CloudWatch, and Application Insights.
Scheduling and automation can be achieved via AWS CloudFormation, Amazon EventBridge, AWS Lake Formation, AWS DevOps tools, and AWS containers, networking, and storage services. These offer respective capabilities that are configurable and scalable with pay-as-you-go pricing.
Now, let’s look at how the reference architecture with its multiple layers promotes separation of concern. It offers the enterprises the agility to integrate with new and existing data sources and support new analytical processes and tools required to keep the solutions current.
Dissecting Layered Architecture
In the following sections, we dissect different layers of the proposed reference architecture and look at the key responsibilities, capabilities, and integration possibilities of each logical layer. These sections correspond with the numbers in the reference architecture shown in Figure 1.
1. Data Ingestion
The data ingestion layer brings data into the data lake, connecting internal and external data sources, and then delivers data into the data storage layer. You can leverage purpose-built AWS services to load structured/non-structured data, stream both batch and real-time data, and deliver data to a diverse set of targets.
One or more of the available AWS services can be leveraged based on the use case, type of data to ingest, and data source. This includes AWS Data Exchange to ingest third-party data, Amazon AppFlow to ingest data from SaaS application providers, AWS Transfer Family to ingest data from partners, Amazon Kinesis Data Firehose to ingest real-time data, or AWS DataSync to replicate data on on-premises systems.
2. Data Storage
The data storage layer provides a scalable, secure, and cost-effective solution to store vast amounts of data in a variety of structures and formats.
The data storage layer is organized into the following zones:
- Raw: This is where data from the ingestion layer lands. It’s a transient area—data engineers interact with the data stored in this zone.
- Cleaned: After preliminary quality checks, raw data moves into the cleaned zone for permanent storage. Here, data is stored in its original format. Having data from all sources permanently stored in the cleaned zone allows finance teams to retrace their steps in case of errors or data loss in downstream storage zones. Data engineers and data scientists interact with the data stored in this zone.
- Curated: Once raw data has been cleaned, it’s considered ready to use and moves into the curated zone. It conforms to organizational standards and data models, and it’s often segmented and stored in formats that support the consumption layer. Every employee across an organization can use this data to make more informed decisions.
You can leverage Amazon S3 to store and protect any amount of data that an enterprise generates. This storage service could serve as the data lake to run your extract, transform, load (ETL) workloads.
3. Data Processing
The data processing layer transforms data into a consumable format through data validation, cleanup, transformation, and enrichment. It moves data quickly between the raw, cleaned, and curated zones, and registers metadata for the cataloging layer.
The data processing layer also matches the right dataset characteristic to processing task. It can handle large data volumes and support schema-on-read, partitioned data, and diverse data formats. Finally, this layer builds and orchestrates data processing pipelines for each step.
AWS Glue along with AWS Step Functions can help you orchestrate the process of discovering, preparing, and integrating data for analytics, machine learning, and application development. You can use AWS Lake Formation to set up a secure data lake, defining data sources and what data access and security policies you want to apply.
4. Data Cataloging and Search
The data cataloging and search layer stores business and technical metadata for data hosted in the storage layer. It provides the ability to track schema and changes to the metadata.
This layer also makes data lakes searchable to ensure data stays organized as the number of datasets increases. You can use AWS Glue with Amazon OpenSearch Service for your ETL jobs while cataloging the metadata in the data lake and making it searchable.
5. Genpact Domain-Centric Data Model
The Genpact domain-centric data model layer consists of the data model that was developed and perfected over 20+ of years of Genpact experience running back offices for clients and delivering use cases across various industries.
The layer primarily consists of domain data models, common business dictionary, and a number of financial and accounting KPIs that were identified in running these operations. This domain knowledge is extensively leveraged in data preparation activities, and in the processing and transformation of fragmented data models from disparate systems to deliver a single pane of glass for business users.
A common business dictionary facilitates business SMEs to link disparate terminologies with physical data to help develop a common interpretation of the data and, hence, the critical business insights.
6. Security and Governance
The security and governance layer protects the data in the storage layer and the processing resources in all layers. It ensures access control, encryption, network protection, usage monitoring, and auditing.
This layer also monitors activities in other layers for detailed audit trails. Various AWS security services depicted in this layer will help you to implement enterprise-grade optimal security posture for your data and processes.
The security and governance layer provides infrastructure automation and scheduling capabilities that range from spinning containers to setting up secure data lakes.
7. Data Consumption
The data consumption layer is scalable and provides performance tools to uncover insights from the data lake. It democratizes analytics across finance using purpose-built analytical tools, including structured query language, batch analytics, business intelligence dashboards, and machine learning.
This layer integrates with the storage, cataloging, and security layers. It also supports schema-on-read, a variety of data structures and formats, and uses data partitioning for cost and performance optimization.
8. Downstream
The downstream layer consists of business applications built on enterprise application frameworks such as Genpact’s Cora—an AI-based business platform that accelerates digital transformation for enterprises.
These application frameworks use the consumption layer to provide dashboards and self-service capabilities for data governance, certification teams, and financial teams. The data is kept secure and only provides access and reporting to appropriate individuals.
Summary of the Layered Architecture
The layered architecture detailed in this post promotes opportunities for integrating the solution with other AWS services and third-party solutions, as well as the flexibility to extend the functionality and distributing tasks across different layers.
In turn, this provides enterprises with the agility needed to integrate new data sources and add new tools to keep pace with the ever-changing analytics landscape.
The reference architecture we have shown here leverages various AWS serverless offerings and managed services, which help free finance and IT teams from the burden of undifferentiated heavy lifting in managing IT infrastructure by providing scalable, resilient, secure, and cost-effective AWS cloud services.
Genpact’s data-driven finance office reference architecture allows you to focus on rapidly building data and analytics pipelines. It significantly accelerates new data onboarding and drives insights from your data.
The AWS serverless and managed components enable self-service across all data consumer roles by providing the following key benefits:
- Easy configuration-driven use.
- Freedom from infrastructure management.
- Pay-per-use pricing model.
Conclusion
Genpact has delivered solutions to finance teams across several industry verticals using the data-driven finance office reference architecture presented in this post.
Leveraging the reference architecture, Genpact has delivered:
- Procure-to-pay transformation for a global energy major to deliver $100 million+ measured and certified business impact.
- Record-to-report transformation of an industrial conglomerate to deliver $70 million+ impact
- Cloud transformation for one of the world’s largest hedge funds to reduce operating cost by over $60 million.
- Order-to-cash transformation for a medical equipment and devices business to create $20 billion end-to-end sales visibility.
- Financial planning and analytics modernization for a leading healthcare services major to deliver $20 million impact.
- Operations transformation for a leading investment and asset management firm to improve assets under management forecasting by 5% and cost savings by 15%.
The synergy of domain data and analytics, combined with cutting-edge cloud technology, is a game changer in ushering organizations on a transformation journey like never before.
Genpact and AWS encourage organizations to reimagine their finance offices as a data and analytics-driven, future-ready business partner that helps companies prepare and respond comprehensively to inevitable compressive disruption in the industry.
Learn more about how Genpact is transforming finance offices.
.

.
Genpact – AWS Partner Spotlight
Genpact is an AWS Partner with a core strength in domain-driven expertise running back offices for global Fortune 500 companies across the industry spectrum.
Contact Genpact | Partner Overview
*Already worked with Genpact? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.