亚马逊AWS官方博客
Amazon Aurora 回溯功能 – 让时光倒转
我们都曾有过那样的经历!您需要对重要的生产数据库执行快速且看似简单的修复。您编写了查询,简单检查了一遍,然后运行查询。几秒钟后,您意识到自己忘记了 WHERE 子句,结果丢弃了错误的表格,或者犯了另一个严重的错误,并中断了查询,但损失已经无法挽回。您深呼吸了一下,透过齿缝发出“嘶”的一声,希望一个“撤消”选项出现在您眼前。接下来该怎么办呢?
全新的 Amazon Aurora 回溯功能
今天,我要为您介绍 Amazon Aurora 的全新回溯功能。就当今技术而言,该功能非常接近于实际为您提供了“撤消”选项。
此功能推出之后,可以为所有新启动的 Aurora 数据库集群启用此功能。要启用此功能,只需指定要回溯时长,并照常使用数据库即可(可以在配置高级设置页面中找到此功能):
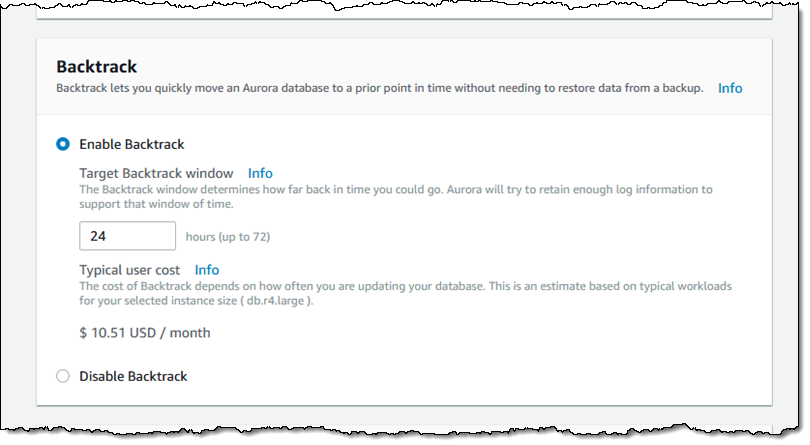
Aurora 使用分布式、日志结构的系统(请参阅 Design Considerations for High Throughput Cloud-Native Relational Databases 了解更多信息);每项数据库更改都会生成一条新的日志记录,以日志序列号 (LSN) 标识。启用回溯功能会在集群中为 LSN 存储预置一个 FIFO 缓冲区。这能实现以秒为单位的快速访问和恢复时间。
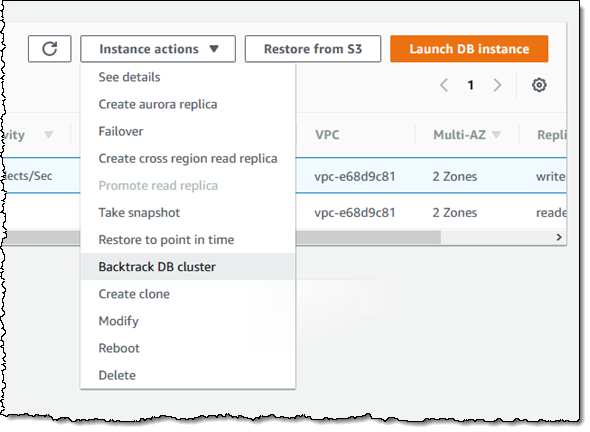
如果发生了上述令人遗憾的情况,所有内容看起来都已经丢失,那么您只需要暂停应用程序,打开 Aurora 控制台,选择集群,然后单击 Backtrack DB cluster(回溯数据库集群)即可:
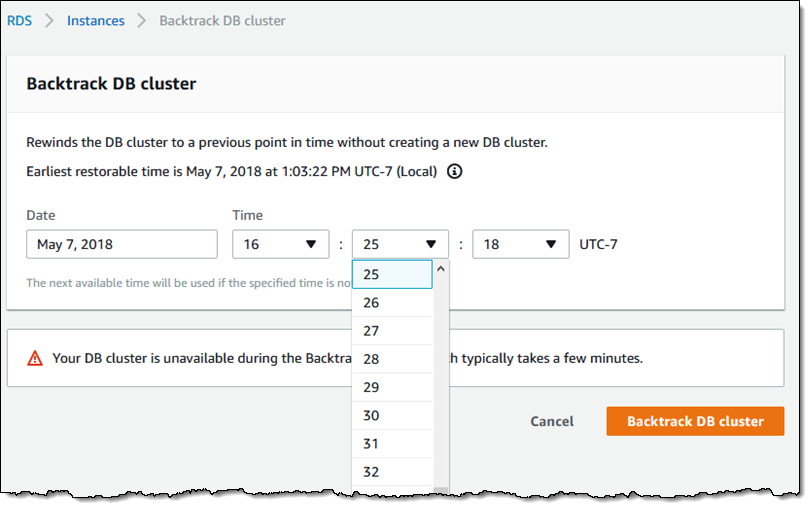
随后选择 Backtrack(回溯)、灾难发生前的时间点,并单击 Backtrack DB cluster(回溯数据库集群):
然后就可以静待回溯完成,再次运行应用程序并继续进行,就像什么都没有发生一样。启动回溯功能后,Aurora 将暂停数据库、关闭所有打开的连接、丢弃未提交的写入,并等待回溯完成。然后就会恢复正常操作并接受请求。在回溯过程中,实例状态为 backtracking(正在回溯):
![]()
回溯完成后,控制台会通知您:

如果回溯完成后,您发现回溯得过远了,可以再回溯到稍晚的时间。克隆、备份和恢复等其他 Aurora 功能可继续用于已配置回溯的实例。
我相信,您可以借助这项炫酷的新功能,想出一些创意十足、特色鲜明的使用案例。例如,您可以在测试对数据库所做的更改后,使用它来恢复测试数据库。您可以从 API 或 CLI 启动恢复,从而轻松将其集成到现有的测试框架中。
需知信息
此选项适用于新创建的兼容 MySQL 的 Aurora 数据库集群,以及已从备份恢复的兼容 MySQL 的集群。创建或恢复集群时必须选择使用此功能;无法为正在运行的集群启用此功能。
此功能现在可在运行 Amazon Aurora 的所有 AWS 区域中使用,您可以立即开始使用该功能。
— Jeff;