亚马逊AWS官方博客
Amazon Personalize 现将快速变化的新产品与全新内容目录的个性化推荐效果提升达50%
Amazon Personalize现将快速变化的新产品与全新内容目录的个性化推荐效果提升达50%
Amazon Personalize 现在能够更轻松地为书籍、电影、音乐、新闻文章等目录创建个性化推荐,且通过AWS控制台进行几次点击即可将推荐效率提升高达50%(以点击率衡量)。无需对应用程序代码做出任何更改,Amazon Personalize将帮助客户在原有推荐机制当中纳入新的产品与内容,以更好的方式为最终用户提供远超其他推荐系统的发现、点击、购买或消费体验。
随着新产品与新内容的不断涌现,许多目录的规模也在持续扩张,帮助用户及时发现并使用这些产品或内容对企业来说至关重要。例如,新闻网站用户希望看到最新的个性化新闻推送,而视频点播服务消费媒体的用户则希望第一时间获得自己喜爱的影片与剧集。只有向用户展示新产品及内容并满足这些期望,企业才能持续保持用户体验的新鲜感,并通过直接转化或订阅用户转化及保留,提升自身运营收入。但不断变化的目录中往往包含过多新内容,很难向每位用户进行逐一展示。因此,根据用户的兴趣与喜好将新产品与用户进行匹配,从而使用户体验更加个性化。问题在于,新产品往往缺少历史浏览、点击、购买及订阅数据,因此为其生成个性化推荐往往难度更高。大部分传统推荐系统只能通过充足的历史数据进行产品推荐,这将导致目录中的众多新产品被忽略。
通过今天的发布,您只需要在Amazon Personalize控制台内进行几次单击,即可帮助企业客户为用户创建新的产品与内容个性化推荐。Amazon Personalize能够整合用户以往对于类似产品的积极交互(点击、购买等),并据此整理出新的产品推荐信息。如果用户对于推荐的新产品同样抱有积极态度,则Personalize会进一步将其推荐给更多具有相似喜好的用户。在Amazon,我们多年以来一直利用此项功能生成产品推荐,而且相较于不包含新产品的推荐方法,其客户转化率提高了21%。该功能已经通过Amazon Personalize免费提供,作为其深度学习算法的一部分,这些算法在Amazon多年的开发及实践使用中得到了持续完善。对客户来说,这是一个双赢的局面——既可以免费获取这项新功能,又不必放弃之前已经通过Amazon Personalize建立的高相关度推荐能力。
Amazon Personalize能够帮助客户轻松地开发具有广泛个性化用例的应用程序,包括实时产品推荐与定制化的市场营销。Amazon Personalize将Amazon.com使用的同一套机器学习技术方案交付给每一个人,供其在自己的应用场景中使用,且无需任何机器学习专业经验。Amazon Personalize客户只需要为实际服务使用量付费,不必承担任何最低费用或服务使用承诺。大家可以通过简单的三步走过程快速使用Amazon Personalize,期间只需要在AWS控制台中进行几次单击;当然,您也可以通过一组简单的API调用实现同样的效果。首先,将Amazon Personalize指向Amazon S3中的用户数据、目录数据以及查看、点击、购买等活动流,或者使用简单的API调用进行上传。第二步,在控制台中单击或执行API调用,借此为您的数据训练出自定义的私有推荐模型(CreateSolution)。第三步,通过创建活动(campaign)并使用GetRecommendations API为任意用户检索出个性化推荐结果。
在本文中,我们将向大家详细介绍整个实现流程,并讨论推荐系统层面的各项最佳实践。
将数据添加至Personalize
在本文中,我们将创建一个包含交互数据集与项目数据集(项目元数据)的数据集组。关于创建数据集组的相关说明,请参阅入门教程(控制台)。
创建交互数据集
要创建一个交互数据集,请使用以下schema并导入bandits-demo-interactions.csv文件,此文件为综合电影评分数据集:
现在,您可以选择将印象(impression)信息添加至Amazon Personalize。所谓印象,是指用户与特定项目交互时显示出的项目列表。以下截屏展示了与印象数据进行的部分交互。

印象的表现形式为通过管道进行分隔的项目ID的有序列表。以上截屏中的第一行数据显示,当user_id 1为项目 item_id 1270评分时,则用户将在实际展示中看到1270, 1...9的项目显示顺序。向用户推荐的项目和用户与之交互的项目之间的对比,能够帮助我们不断改进以生成更好的推荐结果。
Amazon Personalize提供两种印象信息输入模式:
- 显式印象——由您手动记录并发送至Personalize的印象。以上示例中包含的即为显式印象。
- 隐式印象——用户从Amazon Personalize处收取到的推荐项目列表。
Amazon Personalize现在能够在每一组推荐内容返回一条RecommendationID。如果大家没有在生成用户体验时更改推荐的顺序或内容,即可直接通过RecommendationID引用该印象,而无需单独发送ItemID列表(显式印象)。如果同时为交互提供显式与隐式印象,则显式印象优先。您还可以通过putEvents API发送隐式与显式推荐。关于更多详细信息,请参阅我们的说明文档。
创建项目数据集
我们可以按照类似的步骤创建项目数据集,并使用包含电影元数据的 bandits-demo-items.csv文件导入数据。我们为项目数据集中使用一个可选的保留关键字 CREATION_TIMESTAMP,借此帮助Amazon Personalize更好地计算各项目的新旧程度并相应地调整建议。在使用自有数据进行建模时,建议大家在此字段中记录首次向用户提供该项目的时间戳。我们将从数据集中最新一次交互时间戳作为参考点,推断特定项目的新旧程度。
如果不提供 CREATION_TIMESTAMP,则该模型会从交互数据集中推理出此信息,并使用当前项目的最早交互时间戳作为相应的发布日期。如果某个项目没有交互,则其发布日期将被设置为训练集中最近一次交互的时间戳,而新旧程度(或称年龄)将被设定为0以代表全新项。
本文中使用的数据集涵盖1931部电影,其中191部拥有创建时间戳,即交互数据集中最后一次交互的时间戳。这191个新项目亦被称为冷项目,且在数据集内的标签编号大于1800。这套项目数据集的schema如下所示:
模型训练
在数据集导入作业完成之后,接下来就是对模型进行训练。
- 在 Solutions选项卡上,选择Create solution创建解决方案。
- 选择新的
aws-user-personalization recipe。
新的recipe有效地将深度学习模型(RNN)与老虎机(bandits)结合起来,为您提供更加准确的用户建模(高相关性)与良好的探索效率。
- 直接保留Solution configuration部分所有内容的默认值,而后点击Next。

- 在Create solution version页面,选择Finish以启动训练。
在训练结束之后,大家可以导航至Solution Version Overview页面以查看离线指标。在某些情况下,与在HRNN-Metadata recipe上训练出的模型相比,示例模型的准确率指标(例如mrr或precision@k)以及coverage可能会略有下降。这是因为新的aws-user-personalization recipe给出的推荐不仅仅是基于先前经验的利用(exploitation),还可能会选择牺牲短期利益以获得长期回报。离线指标的计算使用各参数默认值(explorationWeight, explorationItemAgeCutoff),这些参数会影响项目的探索。大家可以在下面的小节中,了解与此相关的更多详细信息。
经过几轮再训练之后,准确率指标与项目覆盖率都将有所增加,这时全新的aws-user-personalization recipe的性能应该优于单纯基于历史记录的HRNN-Metadata recipe。
创建campaign
在Amazon Personalize中,我们使用campaign向用户提供推荐信息。在本节中,我们将通过上一节中创建完成的解决方案构建两项campaign,并演示不同程度的探索带来的影响。
要创建新的campaign,请完成以下操作步骤:
- 在Campaigns选项卡上, 选择 Create Campaign。
- 在 Campaign name部分,输入一项名称。
- 在Solution部分, 选择
user-personalization-solution。 - 在Solution version ID部分, 选择使用 aws-user-personalization recipe的解决方案版本。
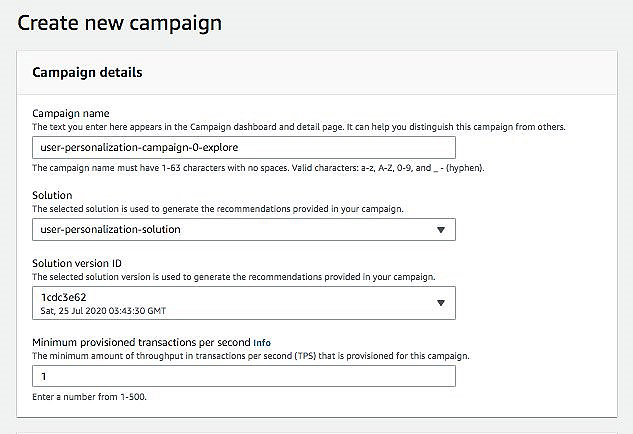
现在,您可以为campaign设定其他配置,借此调整Amazon Personalize对项目推荐的探索方式,进而修改推荐结果。请注意,这些设置选项仅适用于指定user-personalization recipe作为解决方案版本的campaign。具体配置选项如下:
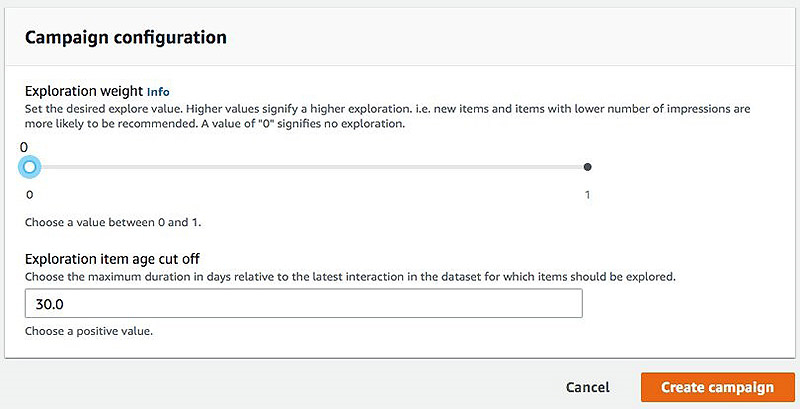
- explorationWeight –
explorationWeight的值越高,则代表探索度越高;展示更少的新项目被推荐的几率更大。值为0代表不进行探索,结果按照相关性进行排名。您可以在[0,1]范围内设置此项参数,其默认值为0.3。 - explorationItemAgeCutoff – 相对于训练数据内最新交互(事件)时间戳的最大持续时长(单位为天)。例如,如果您将
explorationItemAgeCutoff设置为7,则超过或等于7天的项目将不再被视为冷项目,系统不再对这些项目进行探索。当然,在推荐列表中仍会出现部分超过或等于7天的项目,这是因为其与用户的喜好相关,即使没有探索的帮助,推荐质量也很好。此参数的默认值为30,您可以将其设置为大于0的任何值。
为了演示探索效果,我们在这里创建两项campaign。
- 在首个campaign中,将Exploration weight设置为0。
- 将Exploration item age cut off保留为默认值,即30.0。
- 选择 Create campaign。
重复以上步骤以创建第二项campaign,但请注意为其指定不同的名称,并将探索权重更改为1。
获取推荐
在创建或更新您的campaign之后,接下来即可获取面向用户的推荐项目,为项目获得相似的推荐,或者对用户的输入项目列表进行重新排序。
- 在Campaigns详情页面,为您的用户个性化campaign输入用户ID。
以下截屏为带有GetRecommendations调用结果的campaign详情页面,其中包括推荐项目与推荐ID。您可以将其作为隐式印象使用。Amazon Personalize服务会在训练过程中对推荐ID进行解释。
- 输入在交互数据集内存在交互的用户ID。在本文示例中,我们为用户ID 1获取推荐内容。
- 找到探索权重为0的campaign,在其campaign详情页面中选择Detail。
- 在User ID部分,输入
1。 - 选择 Get recommendations。
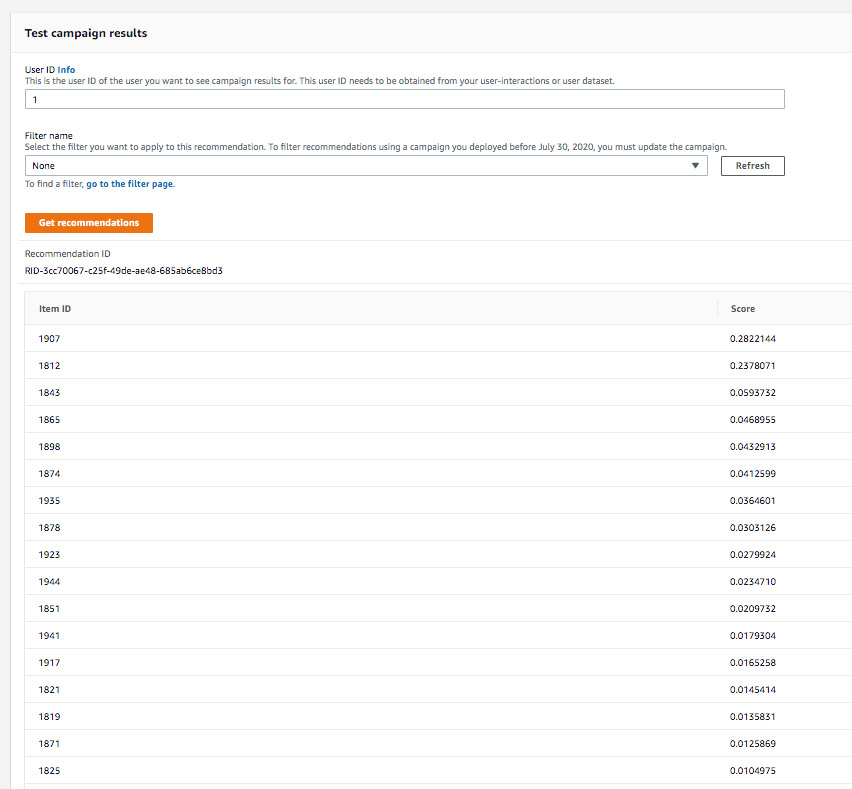
以下截屏为探索权重为0的campaign;可以看到其中的推荐项目属于旧项目,即用户已经观看或评价过这些电影。

以下截屏为同一用户并且探索权重设置为1的campaign推荐结果。可以看到,推荐内容中新近添加的、用户较少评分的电影占比更高。此外,相关性(即利用)与探索之间的权衡,将根据新项目冷的程度自动调整,并结合用户的最新反馈。
Campaign的重新训练与更新
针对已探索项目进行的新一轮交互,将带来关于项目质量的重要反馈,您可以使用此反馈来更新对该项目的探索。在这里,我们建议每小时更新一次模型,借此调整后续项目的探索。
要对模型(solutionVersion)进行更新,您可以调用createSolutionVersion API并将trainingMode 设置为 UPDATE。这项操作将使用最新项目信息更新模型,并根据来自用户的隐式反馈调整探索。这种方法与将trainingMode 设定为 FULL的全量模型训练有所不同。本文建议大家尽量减少对模型的全量训练,一般每1~5天进行一次即可。在创建新的solutionVersion更新后,您可以同步更新campaign以获取新的推荐结果。
以下代码将引导您完成这些步骤:
最佳实践
我们将以最佳实践为本文作结。在使用新的‘aws-user-personalization’ recipe时,请务必关注以下几项最佳实践。
- 别忘了进行重新训练。通过“UPDATE”模式进行重新训练,将帮助您的模型充分了解“冷”项目并在推荐结果中加以体现。在推理期间,模型会向用户推荐“冷”项目并收集用户反馈,重新训练则会引导模型利用这些反馈结果探索“冷”项目的具体属性。如果不进行重新训练,那么模型将永远无法在项目元数据之外,了解关于各“冷”项目的更多细节信息,深入探索自然也就无从谈起。
- 提供良好的项目元数据。即使进行探索,项目元数据在冷项目的推荐当中仍然至关重要。模型将从交互与项目元数据这两种资源中学习项目属性;由于“冷”项目没有任何交互记录,因此模型只能探索相应的元数据以完成初步学习。
- 通过项目数据集中的“CREATION_TIMESTAMP”提供准确的项目发布日期。此信息用于对项目的时间影响进行建模,保证我们不会对旧项目进行探索。
总结
Amazon Personalize提供的全新aws-user-personalization recipe能够在推荐结果中引入交互量较少的新项目,并在重新训练期间通过用户反馈学习项目属性,有效地缓解了项目冷启动问题。关于使用Amazon Personalize优化用户体验的更多详细信息,请参阅Amazon Personalize文档。