亚马逊AWS官方博客
Amazon SageMaker BlazingText:在多个 CPU 或 GPU 上并行处理 Word2Vec
今天,我们推出了 Amazon SageMaker 的最新内置算法 Amazon SageMaker BlazingText。BlazingText 是一种无监督学习算法,用于生成 Word2Vec 嵌入,即单词在大型语料库中的密集向量表示。我们很高兴构建了 BlazingText,它可以最快的速度实现 Word2Vec,供 Amazon SageMaker 用户在以下实例上使用:
与在单一 c4.2xlarge 实例上运行 fastText 相比,BlazingText 在单一 p3.2xlarge (1 个 Volta V100 GPU) 实例上的运行速度要快 21 倍,但成本要少 20%。 跨多个 CPU 节点进行分布式训练时,BlazingText 在八个 c4.8xlarge 实例上的训练速度最高可达 5000 万单词/秒。这比一个 c4.8xlarge fastText CPU 实现要快 11 倍,并且对嵌入的质量几乎没有影响。
Word2Vec
搜索“梅西”时,如何让搜索引擎告知您有关足球或巴塞罗那的情况?在未显式定义单词之间的关系时,如何让机器理解文本数据以便更有效地执行分类或聚类?答案就是创建单词表示,以用于捕获单词的含义、语义关系及其所在的各种上下文。
Word2Vec 是一种热门算法,通过无监督学习为大型语料库中的单词生成密集向量表示。结果表明,所生成的向量可以体现相应单词之间的语义关系。这些向量已广泛应用到各种下游自然语言处理 (NLP) 任务,例如,情绪分析、命名实体识别和机器翻译。
以下部分将介绍实现的详细信息。您可以直接跳到入门部分,了解有关如何将该算法用于三种不同架构的示例。
建模
Word2Vec 是一种神经网络实现,可以学习单词的密集向量表示。此外,也建议使用其他深度或循环神经网络架构来学习单词表示。然而,它们所需的训练时间要比 Word2Vec 长很多。Word2Vec 直接根据已学习的密集嵌入向量 (视为模型的参数) 基于其相邻元素以无监督方式来预测单词。
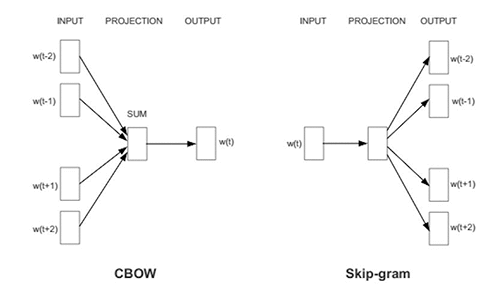
Word2Vec 采用两种不同的模型架构:Contextual Bag-Of-Words (CBOW) 和 Skip-Gram with Negative Sampling (SGNS)。CBOW 旨在根据单词的上下文来预测单词,而 skip-gram 尝试根据单词来预测上下文。实际上,skip-gram 的效果更好,但速度较慢。
Word2Vec 通过随机梯度下降 (SGD) 算法来进行优化,该算法以迭代方式解决问题。SGD 在每一步都会选取一对单词:一个输入单词和一个目标单词,这些单词要么来自其窗口,要么来自随机负采样。然后,它计算目标函数相对于两个选定单词的梯度,并根据梯度值来更新两个单词的单词表示。之后,该算法另外选择一对单词继续进行下一次迭代。
多核与众核架构上的分布
SGD 的一个主要问题是它本身就是连续执行的。因为一次迭代的更新与下一次迭代的计算之间存在依赖性 (它们可能会碰巧接触相同的单词表示),所以每次迭代可能都需要等待上次迭代更新完成。这样,我们便无法使用硬件的并行资源。
HogWild 并行 SGD
在 Hogwild 模式中,不同线程可以并行处理不同的单词对,并且会忽略在模型更新阶段可能出现的所有冲突。从理论上讲,与连续运行相比,这可减少算法的收敛率。但是,如果不可能对相同单词进行跨线程更新,则 Hogwild 方法会表现很出色。实际上,词汇量很大时,出现的冲突相对来说很少,通常也不会影响收敛。
HogBatch 并行 SGD
大部分 Word2Vec 实现都针对单节点多核 CPU 架构进行了优化。但是,它们基于采用 Hogwild 更新的向量-向量运算,这些运算会大量使用内存带宽并且无法有效使用计算资源。
Shihao Ji 和其他人提出了 HogBatch 的想法,用于改善各种数据结构在算法中的重复使用。这可通过运用小批量和负采样共享来实现。因此,我们可以使用矩阵乘法运算 (3 级 BLAS) 来表达问题。 为了在 CPU 上扩展 Word2Vec,BlazingText 使用 HogBatch 并且可以将其计算分布到计算集群中的多个节点上。
在 GPU 上扩展 Word2Vec
Hogwild/Hogbatch 方法成功运用于多核与众核架构中的 Word2Vec 后,此算法便成为了开发 GPU 的良好备选方案。GPU 的并行数量级要比 CPU 高。在使用 GPU 加速 Word2Vec 方面,Amazon SageMaker BlazingText 提供了有效的并行方法。该实现旨在最佳地利用 CUDA 多线程功能,但不会因过度利用 GPU 并行性而造成输出精度降低。应当在并行程度与同步之间做出合理的权衡考虑,目的是不允许多个线程同时对相同的单词向量进行读写访问。这样既能保证良好的准确度,又能加快训练过程。
BlazingText 还对 Word2Vec 进行了扩展,使用数据并行方法可利用多个 GPU。它确实可以有效地在 GPU 之间同步模型权重。有关 GPU 实现的详细信息,请参阅 BlazingText 文章。
BlazingText 中的单一实例模式同时支持 HogWild (CBOW 和 skip-gram) 和 HogBatch (batch_skipgram),而分布式 CPU 模式支持 HogBatch Skipgram (batch_skipgram)。
下表汇总了 Amazon SageMaker BlazingText 在不同架构上支持的模式。
| 硬件类型/模式 | CBOW | skip-gram | batch_skipgram |
| 单一实例 (CPU) | ✔ | ✔ | ✔ |
| 分布式 (CPU) | ✔ | ||
| 单一实例 (1 个或多个 GPU) | ✔ | ✔ |
BlazingText 在 Amazon SageMaker 上的性能
我们根据 fastText CPU 实现 (无子词嵌入) 对 Amazon SageMaker BlazingText 进行了基准测试。我们在标准单词相似性测试集 WS-353 中报告已学习嵌入的吞吐量 (按百万单词/秒计) 和准确度。
硬件:我们对 Amazon SageMaker 进行了所有实验。对于 BlazingText,我们报告单一 GPU 实例 (p3.2xlarge、p2.xlarge、p2.8xlarge 和 p2.16xlarge) 和单一/多个 CPU 实例 (c4.2xlarge 和 c4.8xlarge) 的性能数据。BlazingText 在 GPU 实例上使用 CBOW 和 skip-gram 模式运行,而在 CPU 实例上使用 batch_skipgram 模式运行。我们在单一 CPU 实例上使用 CBOW 和 skip-gram 运行 fastText。
请注意,使用 CBOW 和 skip-gram 时,BlazingText 的性能与在单一 CPU 实例上运行 fastText 的性能相当。因此,我们未在此报告这些数据。
训练语料库:我们基于十亿单词基准数据集训练我们的模型。
超参数:在我们所有的实验中,我们报告的结果基于 CBOW、skip-gram 和 batch_skipgram 模式 (采用负采样) 以及 fastText 的默认参数设置 (向量维数 = 100,窗口大小 = 5,采样阈值 = 1e-4,初始学习速率 = 0.05)。

基于十亿单词基准数据集的吞吐量比较 (百万单词/秒)
如图所示,硬件类型相同时,CBOW 速度最快,其次是 batch_skipgram 和 skip-gram。但是,CBOW 的准确度并不是最高的。这一点在下面的气泡图上很明显。

BlazingText 基准测试 – 十亿单词基准数据集用于训练,WS-353 数据集用于进行评估
由于 BlazingText 可以跨多个 CPU 实例利用多个 GPU 和分布式计算,因此,运行速度比 fastText 快几倍。但是,为了选择最佳的实例配置,我们需要在嵌入质量 (准确度)、吞吐量和成本之间实现平衡。上面的气泡图体现了这些维度。
气泡图中的每个圆表示在使用不同的算法模式和硬件配置时 BlazingText 或 fasttext 训练任务的性能。圆的半径与吞吐量成正比。下表详细列出了与图上的任务编号相对应的各种任务。由于 BlazingText 可以跨多个 CPU 实例利用多个 GPU 和分布式计算,因此,运行速度比 fastText 快几倍。但是,为了选择最佳的实例配置,我们需要在嵌入质量 (准确度)、吞吐量和成本之间实现平衡。
| 任务编号 | 实现 | 实例 | 实例数量 | 模式 | 吞吐量 (百万单词/秒) | 准确度 | 成本 (USD) |
| 1 | fastText | ml.c4.2xlarge | 1 | skip-gram | 1.05 | 0.658 | 1.24 |
| 2 | fastText | ml.c4.8xlarge | 1 | skip-gram | 3.49 | 0.658 | 1.67 |
| 3 | fasttext | ml.c4.2xlarge | 1 | CBOW | 3.62 | 0.6 | 0.41 |
| 4 | fasttext | ml.c4.8xlarge | 1 | CBOW | 12.36 | 0.599 | 0.63 |
| 5 | blazingtext | ml.p2.xlarge | 1 | skip-gram | 2.58 | 0.655 | 1.25 |
| 6 | blazingtext | ml.p2.8xlarge | 1 | skip-gram | 11.82 | 0.635 | 3.1 |
| 7 | blazingtext | ml.p2.16xlarge | 1 | skip-gram | 23.52 | 0.613 | 4.49 |
| 8 | blazingtext | ml.p3.2xlarge | 1 | skip-gram | 22.16 | 0.658 | 0.97 |
| 9 | blazingtext | ml.p2.xlarge | 1 | CBOW | 9.92 | 0.602 | 0.44 |
| 10 | blazingtext | ml.p2.8xlarge | 1 | CBOW | 44.93 | 0.576 | 1.69 |
| 11 | blazingtext | ml.p2.16xlarge | 1 | CBOW | 79.16 | 0.562 | 2.89 |
| 12 | blazingtext | ml.p3.2xlarge | 1 | CBOW | 32.65 | 0.601 | 0.82 |
| 13 | blazingtext | ml.c4.2xlarge | 1 | batch_skipgram | 2.65 | 0.647 | 0.53 |
| 14 | blazingtext | ml.c4.2xlarge | 2 | batch_skipgram | 4.1 | 0.637 | 0.74 |
| 15 | blazingtext | ml.c4.2xlarge | 4 | batch_skipgram | 7.15 | 0.632 | 0.95 |
| 16 | blazingtext | ml.c4.2xlarge | 8 | batch_skipgram | 12.54 | 0.621 | 1.36 |
| 17 | blazingtext | ml.c4.8xlarge | 1 | batch_skipgram | 9.96 | 0.641 | 0.77 |
| 18 | blazingtext | ml.c4.8xlarge | 2 | batch_skipgram | 15.6 | 0.637 | 1.15 |
| 19 | blazingtext | ml.c4.8xlarge | 4 | batch_skipgram | 28.26 | 0.63 | 1.75 |
| 20 | blazingtext | ml.c4.8xlarge | 8 | batch_skipgram | 52.41 | 0.628 | 2.9 |
性能特色
虽然上表较为全面地汇总了各种得失情况,下面我们来重点介绍其中几项。
- 任务 1 与任务 8:就准确度和成本来说,BlazingText 在 p3.2xlarge (Volta GPU) 实例上运行时性能最佳。它的速度比 fastText (在 c4.2xlarge 上) 快了将近 21 倍,成本却要少 20%,而准确度却相同。
- 任务 2 与任务 17:与 FastText skipgram 相比,在 CPU 上使用 batch_skipgram 的 BlazingText 的运行速度要快 2.5 倍,成本要少 50%,而准确度只有小幅下降。
- 任务 17-20:如果数据集的大小特别大 (> 50 GB),可以在多个 CPU 实例上使用 BlazingText 与 batch_skipgram。增加实例数量会使速度几乎呈线性增长,但准确度会有小幅下降。下降量可能处于可接受的限值范围内,具体取决于下游 NLP 应用程序。
开始使用
BlazingText 根据文本文档训练模型,并返回一个包含单词到向量映射的文件。正如其他 Amazon SageMaker 算法一样,此算法也依靠 Amazon Simple Storage Service (Amazon S3) 存储训练数据和生成的模型项目。在训练期间,Amazon SageMaker 会代表客户自动启动和停止 Amazon Elastic Compute Cloud (Amazon EC2) 实例。
模型经过训练后,您可以从 Amazon S3 下载所生成的单词嵌入词典。与其他 Amazon SageMaker 算法不同的是,您无法将此模型部署到终端节点,因为此时的推理只是向量查找。有关 Amazon SageMaker 工作流程的综合高级概述,请参阅 Amazon SageMaker 文档。
数据格式化
BlazingText 需要单个预处理文本文件,其中包含空格分隔的令牌,并且文件的每一行都有一个句子。应该将多个文本文件连接成单个文件。BlazingText 不会执行任何文本预处理步骤。因此,如果语料库包含“apple”和“Apple”,系统将会为它们生成两个不同的向量。
训练设置
要启动训练任务,客户可以使用适用于 Python (Boto3) 的低级 AWS SDK 或 AWS 管理控制台。指定硬件配置和超参数后,您需要在 Amazon S3 上指定训练数据的位置。BlazingText 要求训练数据位于“训练”通道中。
其他资源
有关更多信息,请参阅 BlazingText 文档。有关在 Amazon SageMaker Notebook 实例中使用此新算法的动手演练,请参阅 BlazingText Notebook 实例。此 Notebook 展示了各种模式,在这些模式中,您可以使用该算法并提供一些自定义超参数。
作者简介
 Saurabh Gupta 是 AWS 深度学习部门的应用科学家。他在加州大学圣地亚哥分校获得了人工智能和机器学习专业的理学硕士学位,目前,正在为 Amazon SageMaker 构建自然语言处理算法。
Saurabh Gupta 是 AWS 深度学习部门的应用科学家。他在加州大学圣地亚哥分校获得了人工智能和机器学习专业的理学硕士学位,目前,正在为 Amazon SageMaker 构建自然语言处理算法。
 Vineet Khare 是 AWS 深度学习部门的科学经理。他专注于使用最前沿的科学技术为 AWS 客户构建人工智能和机器学习应用程序。在业余时间,他喜欢阅读、徒步旅行以及与家人共享天伦之乐。
Vineet Khare 是 AWS 深度学习部门的科学经理。他专注于使用最前沿的科学技术为 AWS 客户构建人工智能和机器学习应用程序。在业余时间,他喜欢阅读、徒步旅行以及与家人共享天伦之乐。