亚马逊AWS官方博客
在 AWS 中国区搭建基于 Kubernetes 的动态扩展的 TiDB 集群
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。 基于Kubernetes环境搭建TiDB具有易部署易调整、弹性、高可用等特点,越来越多的客户采用这种方式进行研发测试环境的TiDB集群搭建。
TiDB提供了对AWS平台的支持,官网也有提供guide 如何利用terraform模板一键在Amazon Elastic Kubernetes Service(EKS上)中部署整套环境。基于目前该模板暂不支持中国区的现状,本文详述了如何基于AWS中国区自建kubernetes环境,部署TiDB集群并且利用Cluster AutoScaler实现TiDB集群的动态扩展,并探讨了TiDB on Kubernetes中的存储方案选择问题。
内容概述
-
- 如何在Kubernetes上搭建TiDB集群
- 如何扩展Kubernetes集群中TiDB
- 存储方案的选择
- Sysbench压力测试
先决条件
-
-
- 拥有AWS中国区账号,如果还没有,点击此处注册
- 检查账户级别的EC2 Limits,确保你的EC2 limits多于你想要部署的node的数量。如果需要更多实例,可以申请提高instance limit.
-
如何在Kubernetes上搭建TiDB集群
此文章测试环境基于KUBERNETES v1.12.8, KOPS_VERSION 1.12.2,helm v2.14.3, tidb-operator v1.0.0, tidb-cluster v1.0.0, autoscaler v1.2.2
步骤1:配置堡垒机
此步骤会启动一台EC2,用于运维kubernetes集群的堡垒机。
-
-
- 启动EC2(推荐使用Amazon Linux2 AMI)
- IAM设置:创建一个具有特定权限的User,下载credentials文档或者手动记下“Access key ID”和“Secret access key”
-
Note: 该权限至少需要EC2以及auto scaling相关的权限,否则无法正常启动集群。本文为了演示方便,直接挂载了admin权限。在实际的生产中,建议只附加必须的权限。
-
-
- ssh到堡垒机(对于选择Amazon Linux镜像的用户;如选择其他镜像,请更改至对应用户名)
ssh -i <your-private-key-name>.pem ec2-user@<ip-address>在堡垒机中执行
aws configureNote:cn-north-1为北京区的region code,如果用宁夏,应该配置为cn-northwest-1
- AWS Access key ID: xxxxxxx
- AWS Secret access key: xxxxx
- Default Region name: cn-north-1
- Default output format: none (回车)
- ssh到堡垒机(对于选择Amazon Linux镜像的用户;如选择其他镜像,请更改至对应用户名)
-
步骤2:利用kops-cn创建kubernete集群
-
-
- 请参考利用kops-cn在AWS中国区快速创建kubernetes集群的详细文档 kops-cn ,完成Kubernetes集群的启动。
-
关于k8s的版本,此文章测试环境基于KUBERNETES v1.12.8, KOPS_VERSION 1.12.2.
-
-
- 针对TiDB集群特点,可考虑单AZ部署Kubernetes集群以实现更高性能,并降低数据传输成本。不过因此需要放弃跨AZ集群的可用性。这一点可根据您的实际需求进行权衡。 设置方法为在步骤5
make edit-cluster当中找到create-cluster部分,根据自身需求编辑相应的zones,subnet等字段,并保存退出。make edit-cluster ##找到create-cluster部分,根据自身需求编辑相应的zones, subnet等字段, 并保存退出 create-cluster: @KOPS_STATE_STORE=$(KOPS_STATE_STORE) \ AWS_PROFILE=$(AWS_PROFILE) \ AWS_REGION=$(AWS_REGION) \ AWS_DEFAULT_REGION=$(AWS_DEFAULT_REGION) \ kops create cluster \ --cloud=aws \ --name=$(CLUSTER_NAME) \ --image=$(AMI) \ --zones=cn-northwest-1a \ --master-count=$(MASTER_COUNT) \ --master-size=$(MASTER_SIZE) \ --node-count=$(NODE_COUNT) \ --node-size=$(NODE_SIZE) \ --vpc=$(VPCID) \ --kubernetes-version=$(KUBERNETES_VERSION_URI) \ --networking=amazon-vpc-routed-eni \ --subnets=subnet-xxxxxxxxxxxx \ --ssh-public-key=$(SSH_PUBLIC_KEY) make update-cluster - (可选选项) 如果您的AWS账号已经做过ICP备案,跳过此步;如果还没有做ICP备案,您账户下的80,8080,443端口是被屏蔽的,您需要配置以下选项更改默认端口。(如果仍需要这三个端口,请同时申请备案开放这三个端口。)
- 登录AWS控制台,在服务- EC2- 负载均衡器页面,选择~/.kube/config 当中的负载均衡器,并且更改以下配置:
- 添加安全组策略,允许8443端口对source:0.0.0.0/0开放。
- 点击listeners(侦听器)选项,将443端口更改成8443.
- 编辑.kube/config文件,在server这一行的最后添加”:8443″
- 登录AWS控制台,在服务- EC2- 负载均衡器页面,选择~/.kube/config 当中的负载均衡器,并且更改以下配置:
- 用kubectl命令检查集群是否配置成功
- 安装helm和tiller,点击此处查看详细的安装文档,需要将helm以及tiller可执行文件放到
/usr/local/bin/目录下。
- 针对TiDB集群特点,可考虑单AZ部署Kubernetes集群以实现更高性能,并降低数据传输成本。不过因此需要放弃跨AZ集群的可用性。这一点可根据您的实际需求进行权衡。 设置方法为在步骤5
-
步骤3:在kubernete集群安装配置TiDB
-
-
- 本地运行 helm 和 tiller, 操作请参考配合使用 Helm 与 Amazon EKS中的”本地运行 helm 和 tiller”
- 添加pingcap到helm repo list
helm repo add pingcap https://charts.pingcap.org/ helm repo update helm search tidb - 安装TiDB operator
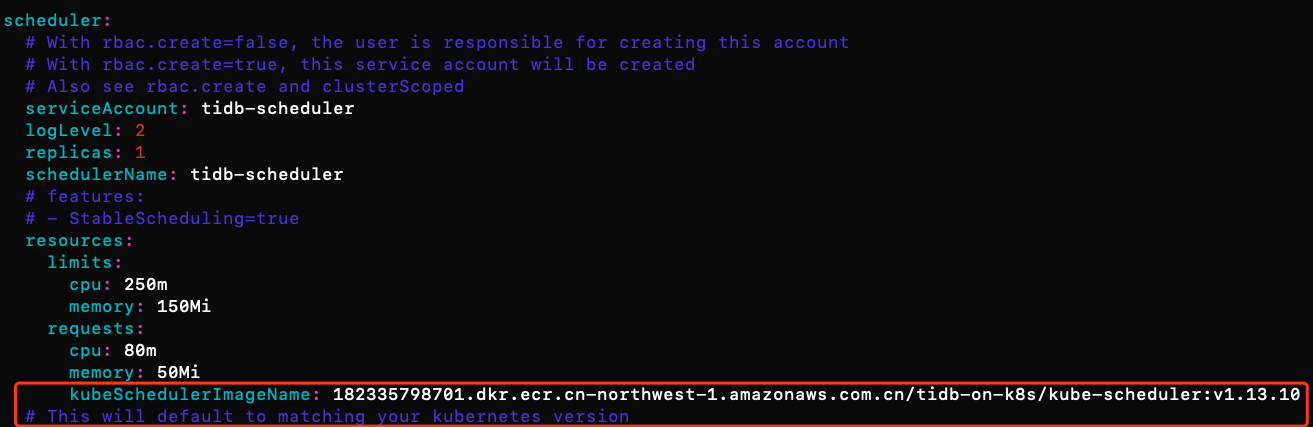
#to create TidbCluster customized resource type: kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/master/manifests/crd.yaml && \ kubectl get crd tidbclusters.pingcap.com #to get chart yaml file of tidb-operator #you could customize your folder location by chaging mkdir command mkdir -p ~/tidb-operator && \ helm inspect values pingcap/tidb-operator --version=v1.0.0 > ~/tidb-operator/values-tidb-operator.yaml #to modify the yaml file and specify local image repo: vim ~/tidb-operator/values-tidb-operator.yaml将scheduler.kubeSchedulerImage替换为国内的源,
182335798701.dkr.ecr.cn-northwest-1.amazonaws.com.cn/tidb-on-k8s/kube-scheduler:v1.13.10, 并保存文件。注:默认情况下,会自动与kubernetes的版本号保持一致,但此ECR Repo下没有其他版本的镜像库,如果要用其他版本或者拉取失败,请自行寻找国内的其他镜像库地址进行替换。
#install tidb-operator: helm install pingcap/tidb-operator --name=tidb-operator --namespace=tidb-admin --version=v1.0.0 -f ~/tidb-operator/values-tidb-operator.yaml #verify the installation: kubectl get po -n tidb-admin -l app.kubernetes.io/name=tidb-operator - 运行以下命令拿到tidb-cluster配置文件
# fetch Tidb cluster package helm fetch pingcap/tidb-cluster # unzip it to get the config file tar -zxvf tidb-cluster-v1.0.0.tgz cd tidb-cluster - 在此文件夹下,会有一个values.yaml文件。这个是tidb-cluster的配置文件,里面包含不同组件,比如TiDB,Tikv, PD的详细定义。在启动集群之前,请您自行修改至期望的配置。比如storageclass,replicaset,pvReclaimPolicy等等。下面是一些sample。推荐阅读TiDB 软件和硬件环境建议配置
- 将storageclass修改为gp2(一种EBS卷类型)。关于不同类型的EBS介绍请参考EBS卷类型的定义和区别获取更多信息。有关于存储方案的介绍,请参考‘存储方案的选择’章节。

【重要】: 对于只支持EBS的实例类型,如c4,c5等,我们需要将所有默认的local-instance更改至一种EBS类型。请点击EC2实例类型介绍了解更多实例类型信息。
- 更改replica的数量

- 将storageclass修改为gp2(一种EBS卷类型)。关于不同类型的EBS介绍请参考EBS卷类型的定义和区别获取更多信息。有关于存储方案的介绍,请参考‘存储方案的选择’章节。
- 在确保已经自定义完所有所期望的配置后,运行以下安装命令。 namespace和name可自行替换。
helm install pingcap/tidb-cluster --name=tidb-cluster-test --namespace=tidbtest -f values.yaml - 查看tidb-cluster创建过程。
watch kubectl get pods --namespace tidbtest -l app.kubernetes.io/instance=tidb-cluster-test -o wide几分钟后,pod将按照replicaset处的定要数量成功启动。

- 列举tidb-cluster的服务
kubectl get services --namespace tidbtest -l app.kubernetes.io/instance=tidb-cluster-test
- 查看集群PVC分配状态 如果storageclass定义为ebs中的一种(如gp2),PV和PVC应已采取dynamic的方式分配成功。可以用
kubectl get pv | grep tidbtest查看pv是否创建成功,此时也可至控制台查看EBS卷的创建。有关于PV,可点击K8s的PV分配查看更多信息。

-
步骤4:部署后,如何访问TiDB集群
-
-
- 利用MySQL客户端访问TiDB集群
- 在kubectl client本机通过mysql客户端访问:
kubectl port-forward -n tidbtest svc/tidb-cluster-test-tidb 4000:4000 & mysql -h 127.0.0.1 -P 4000 -u root -D test - 通过四层网络可达的任意mysql client访问:
此处出于演示目的,通过ClusterIP方式访问,在生产环境中应考虑采用ingress controller方式访问
#查看当前tidb service的nodeport信息 kubectl get svc -n tidbtest #找到对应的tidb条目,如tidb-cluster-1-tidb NodePort 10.100.20.254 <none> 4000:31726/TCP,10080:31651/TCP 82m #确认主机端口为31726. 通过mysql client访问: mysql -h <any host ip from Kubernetes worker nodes> -P 31726 -u root -D test
- 在kubectl client本机通过mysql客户端访问:
- 为用户创建密码
SET PASSWORD FOR 'root'@'%' = 'JEeRq8WbHu'; FLUSH PRIVILEGES; - 为TiDB集群创建监控dashboard
- 如果是在本地PC作为堡垒机,执行下列命令,用本地浏览器打开localhost:3000访问。默认的用户名和密码为admin/admin.
kubectl port-forward -n tidbtest svc/tidb-cluster-test-grafana 3000:3000 &>/tmp/portforward-grafana.log- 如果是利用EC2做实验,在执行完上述命令后,需要加以下命令实现 ssh正向代理
ssh -i <your-pem-name>.pem -L 12000:localhost:3000 ec2-user@<ip address>此时,在本地PC(mac/windows)打开浏览器用localhost:3000 访问即可。
- 利用MySQL客户端访问TiDB集群
-
如何扩展Kubernetes集群中TiDB
TiDB本身的分布式设计能较好地利用到云上Infra层的扩展能力,实现随需扩展。这个section主要介绍实现TiDB的扩展。
-
-
- 手动扩展
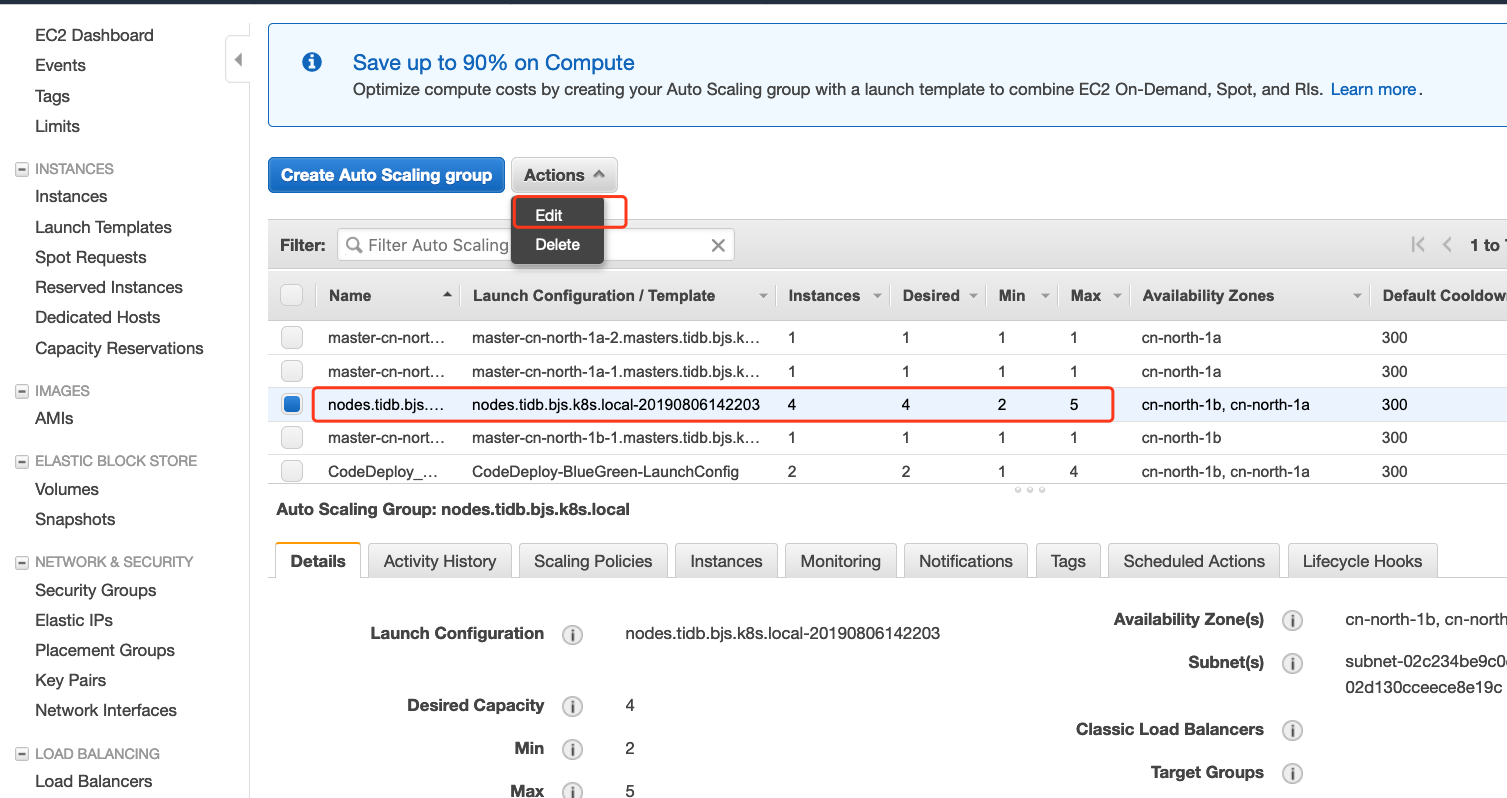
- 扩展Worker Node数量
在 AWS EC2 Console中查看Auto Scaling Group(ASG). 您可以自定义此ASG的最小值,最大值以及当前期望值。如果希望扩展node的数量,只需要更改期望值即可。另外,我们也可以设置规则,使得ASG可以在满足特定条件时(比如,当集群EC2的CPU平均利用达到80%时)自动扩展。但TiDB集群对这一层的扩展无感知。
- 手动扩展Pod数量
在确保node数量足够的情况下,扩展pod数量,只需要在yaml文件中修改对应组件的replicaset即可。修改完毕后运行以下指令。如果storageclass的配置没错,PV和PVC会自动创建。如果Kubernetes Worker Node剩余资源无法满足所有新扩pod的需求,部分pod会一直处于pending状态,此时可通过执行上一步:手动扩展Kubernetes Worker Node数量 来解决。helm upgrade tidb-cluster-test pingcap/tidb-cluster --namespace=tidbtest -f values.yaml
- 扩展Worker Node数量
- 基于Cluster Autoscaler实现Node和pod依次自动扩展
在上述两步中,我们均通过手动的方式,实现了集群的扩展。我们也可以通过配置Cluster AutoScaler(CA) 结合Auto Scaling Group实现半自动的动态扩展,即如果手动修改pod数量,node数量不够时,CA会自动启动node,并且在node创建成功后实现pod的自动部署。 以下为详细的配置和使用步骤:- 下载cluster_autoscaler.yml文件
mkdir ~/environment/cluster-autoscaler cd ~/environment/cluster-autoscaler wget https://eksworkshop.com/scaling/deploy_ca.files/cluster_autoscaler.yml - 在控制台找到AutoScaling Group(ASG)的名称

- 根据需要,修改ASG能扩展收缩的的最大值,最小值。ASG内的node数量将会在最小值-最大值之间。在这里的演示中,我们将最小值调整为2,最大值调整为8。

- 替换参数。打开cluster_autoscaler.yml文件,找到command–nodes对应的位置,(1)将 参数为替换为实际的ASG名称,前面的数字为自己定义的最小:最大值;(2)region改为实际使用的region,北京区为cn-north-1,宁夏区为cn-northwest-1。
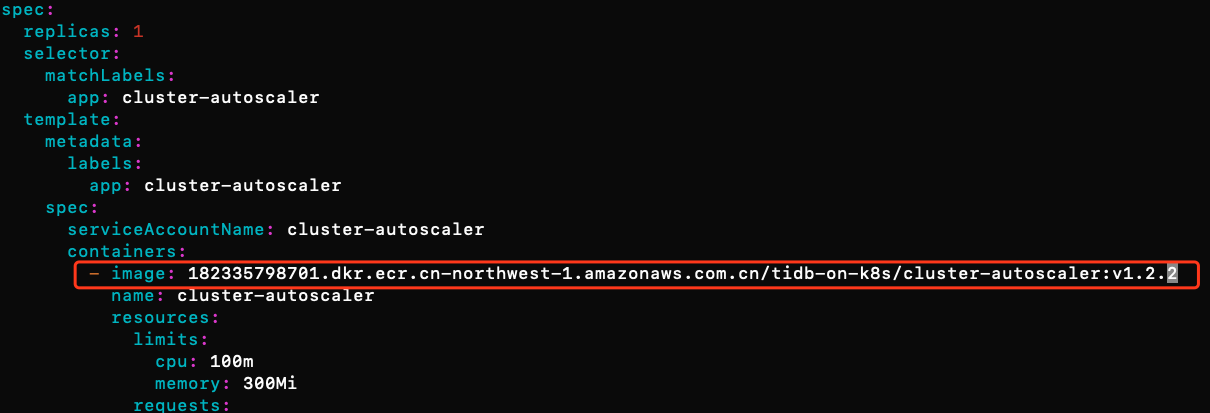
command: - ./cluster-autoscaler - --v=4 - --stderrthreshold=info - --cloud-provider=aws - --skip-nodes-with-local-storage=false - --nodes=2:8:eksctl-eksworkshop-eksctl-nodegroup-0-NodeGroup-SQG8QDVSR73G env: - name: AWS_REGION value: cn-north-1 - 对于中国用户,需要修改cluster-autoscaler的镜像地址为中国国内的镜像
182335798701.dkr.ecr.cn-northwest-1.amazonaws.com.cn/tidb-on-k8s/cluster-autoscaler:v1.2.2,否则会拉取失败。如果需要其他版本的autoscaler,请自行寻找镜像地址。
- 确保本地credentials具有auto scaling的权限。
- 部署CA
kubectl apply -f ~/environment/cluster-autoscaler/cluster_autoscaler.yml - 查看logs
kubectl logs -f deployment/cluster-autoscaler -n kube-system - 验证。再次修改yaml文件为desired count并执行
helm upgrade操作。这里需确保新pod所需资源超过当前Kubernetes集群的capacity,以验证CA能否自动触发扩展node的动作。可观察到刚开始,某些pod由于Node资源不足处于pending状态。
 3-4分钟后,可以从控制台或者通过
3-4分钟后,可以从控制台或者通过kubectl get nodes对比观察到新的node是否创建成功。

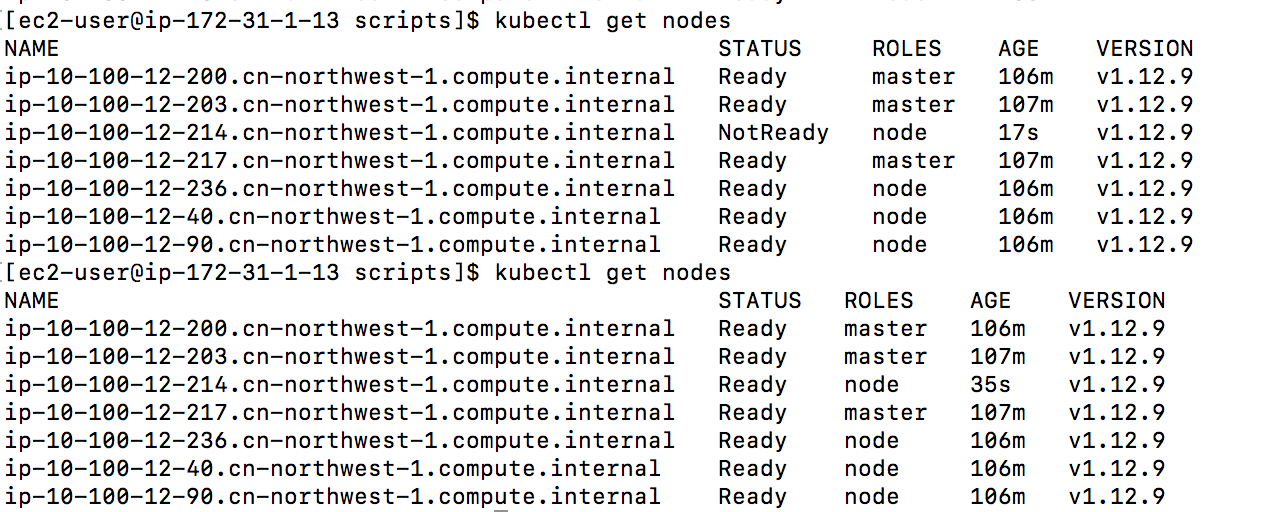 Node数量足够后,pending的pod成功处于running状态
Node数量足够后,pending的pod成功处于running状态

- 下载cluster_autoscaler.yml文件
- 手动扩展
-
存储方案的选择
在AWS上,有两类块存储介质可以用作TiDB PV,分别为EBS和Instance Store。
-
-
- Instance Store存储:提供更低延迟的访问,与TiKV的Raft机制结合可实现高性能高可用的数据层,适合对性能要求较高的场景;
- EBS存储 :提供更好的数据持久性,基于api的资源操作,适合对集群的弹性和灵活性有要求的场景。
-
Sysbench压力测试
本章节演示如何采用sysbench工具对该cluster做模拟压力测试。 本部分旨在从功能性上完成TiDB on Kubernetes的压力测试场景,不涉及性能优化。 如需达到更高性能,建议从以下几个方向考虑:
-
-
- 采用instance store或大容量EBS作为tikv PV空间;
- Kubernetes Worker node采用较高配置实例;
- 集群单AZ部署;
- 参照TiDB文档为各Worker node配置优化的系统参数(inode等)
MySQL Client及sysbench的安装过程不在本文中展开, 可参考如何用 Sysbench 测试 TiDB进行配置。
-
- 按照步骤4所述连接tidb集群并创建DB:
mysql> create database mydb1; mysql> exit; - 写性能测试
由于TiDB在数据写入时的调度遵循基于Primary Key的Range方式,在执行大量插入的场景时,TiDB会将该批次数据落入相同的TiKV节点,造成热点问题。解决方案是可对表结构做一些改造,将原主键设为Unique Key,这样 TiDB 内部会添加一个自增的伪列 _tidb_rowid。我们可以通过修改shard_row_id_bits的方式来将数据打散, 方法如下。
ALTER TABLE my SHARD_ROW_ID_BITS = 3以下命令演示采用Sysbench脚本向数据库持续插入250张表,每张表25000条记录。./sysbench --test=/home/ec2-user/sysbench/sysbench/tests/db/oltp.lua --mysql-host=10.100.12.90 --oltp-tables-count=250 --mysql-user=root --mysql-password=<mypassword> --mysql-port=31726 --oltp-table-size=25000 --mysql-db=mydb1 --db-driver=mysql prepare此时通过CloudWatch观察各Kubernetes worker node节点以及单个tikv的PV卷所对应的EBS性能指标,可发现磁盘写throughput压力较大(~10MB/s),符合单盘10GiB EBS的吞吐性能预期(100 iops * 100KB/io = 10MB/s)。请参考EBS的性能表现以及规划获取更多内容。

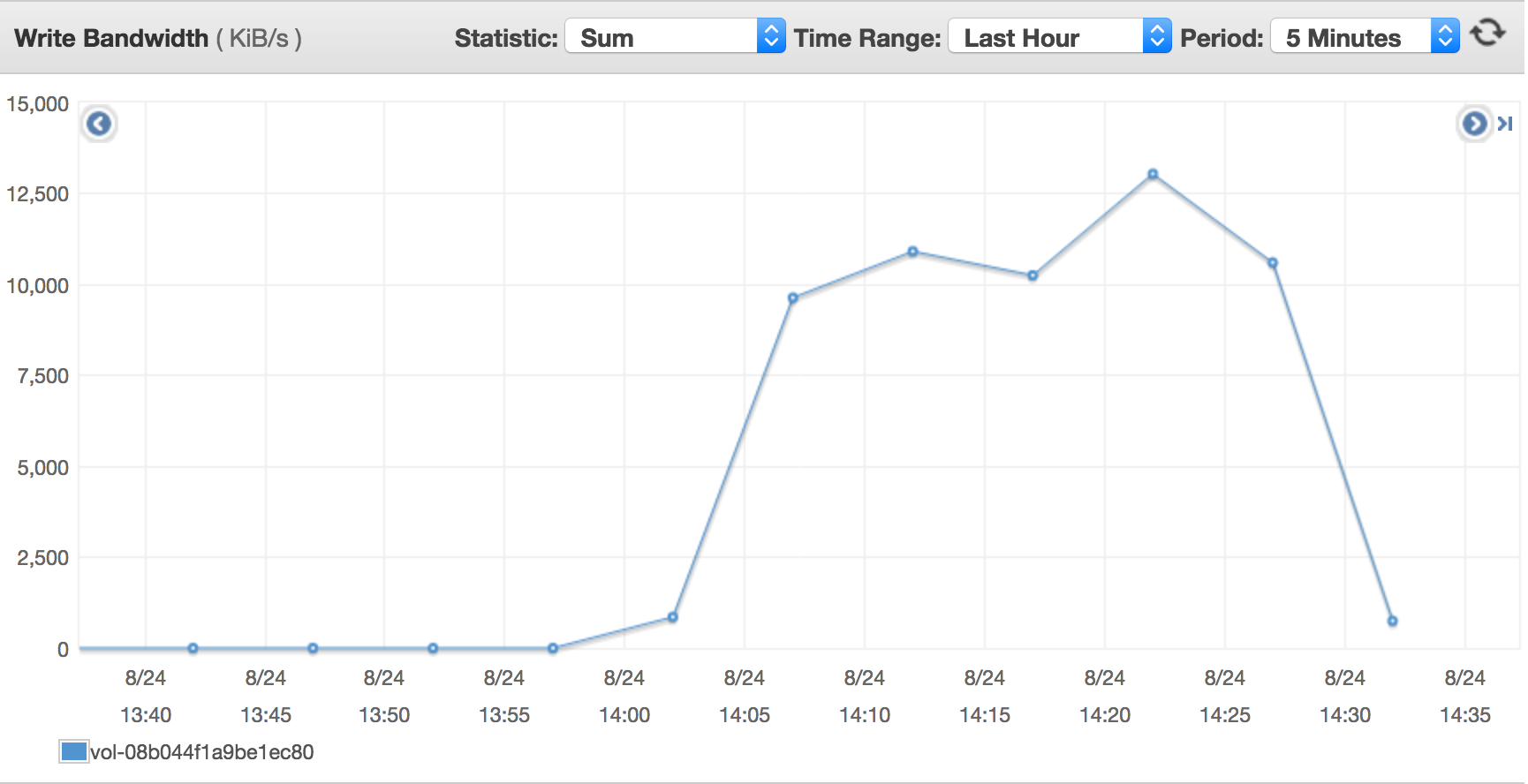

- OLTP性能测试
./sysbench --test=/home/ec2-user/sysbench/sysbench/tests/db/oltp.lua --mysql-host=10.100.12.90 --oltp-tables-count=250 --mysql-user=root --mysql-password=<mypassword> --mysql-port=31726 --db-driver=mysql --oltp-tablesize=25000 --mysql-db=mydb1 --max-requests=0 --oltp_simple_ranges=0 --oltp-distinct-ranges=0 --oltp-sum-ranges=0 --oltp-order-ranges=0 --maxtime=600 --oltp-read-only=on --num-threads=50 run通过CloudWatch观察相关资源,发现两个Worker node出现cpu瓶颈。由于本次模拟50个并发的OLTP读写业务,对tidb组件的性能压力较大,而tidb仅有两个pod,对应的两个node的CPU出现瓶颈,符合预期。可通过修改上文values.yaml中的tidb replica数量进行在线扩展来解决该瓶颈。

- 按照步骤4所述连接tidb集群并创建DB:
-
故障排查
-
-
- Error: trying and failing to pull image error
此error的常见原因是,中国block了google的源,所以需要将google的源替换为国内的源。 由于都是第三方的库,如存在拉取失败的情况,请灵活替换。 - Error: cannot find tiller
- tiller执行文件在helm的压缩包当中,需要将helm可执行文件移到
/usr/local/bin/目录下 - 每次在您想要为集群使用 helm 时重复本地运行 helm 和 tiller的过程
- tiller执行文件在helm的压缩包当中,需要将helm可执行文件移到
- 启动新资源失败
检查账户EC2 limits。确保有足够的limit可以启动期望数量的EC2。如果实例数量不够,请点击请求限额资源。
- PV创建失败
检查storageclass的定义。
- Error: trying and failing to pull image error
-
删除资源
-
-
- 如需一键删除整个环境,建议采用kops-cn所提供的
make delete-cluster命令完成AWS资源的删除。 - 也可根据需求自行删除namespace, pod,node等,留意如果您的pvReclaimPolicy设置的为Retain, 在pod删除后,pv不会自动删除,您需要手动删除EBS卷或者通过
kubectl delete pv命令来删除。
- 如需一键删除整个环境,建议采用kops-cn所提供的
-
总结
本文描述了如何利用kops-cn,在AWS中国区搭建kubernetes集群并且部署TiDB,并实现了TiDB的弹性扩展。采用EBS作为PV存储方案的优势在于节点agnostic,可支持基于api的自动provisioning,适合集群的快速搭建和调整。该方案建议用于研发测试环境的TiDB集群快速搭建,以及对数据持久性有极严格要求的场景。