亚马逊AWS官方博客
在 Amazon EMR 上成功管理 Apache Spark 应用程序内存的最佳实践
在大数据领域,一个常见的用例是对来自各种数据源的大量数据执行提取、转换 (ET) 和数据分析。然后,通常是分析数据以获取洞察。处理如此庞大的数据最常用的基于云的解决方案之一是 Amazon EMR。
Amazon EMR 是一个托管集群平台,可简化在 AWS 上运行大数据框架的过程,如 Apache Hadoop 和 Apache Spark。Amazon EMR 使组织能够在几分钟内启动具有多个实例的集群。它还让您能够通过并行处理来处理各种数据工程和商业智能工作负载。这样做的话,您可以在很大程度上减少创建和扩展集群所涉及的数据处理时间、工作量和成本。
Apache Spark 是一个开源、快速和通用的集群计算软件框架,广泛应用于大数据的分布式处理。Apache Spark 在很大程度上依赖于集群内存 (RAM),因为其跨节点在内存中执行并行计算,以减少任务的 I/O 和执行时间。
通常,在 Amazon EMR 上运行 Spark 应用程序时,请执行以下步骤:
- 将 Spark 应用程序包上载到 Amazon S3。
- 使用已配置的 Apache Spark 配置并启动 Amazon EMR 集群。
- 将应用程序包从 Amazon S3 安装到集群上,然后运行该应用程序。
- 应用程序完成后终止集群。
根据数据和处理需求适当配置 Spark 应用程序以使其成功非常重要。使用默认设置时,Spark 可能不会使用集群的所有可用资源,最终可能会出现物理和/或虚拟内存问题。stackoverflow.com 上提出了数千个与此主题相关的问题。
本博文旨在通过详细介绍最佳实践来帮助您防范 Amazon EMR 上的 Apache Spark 出现内存相关的问题。
使用默认或不当配置的 Spark 应用程序中的常见内存问题
下面列出的是使用默认或不当配置的 Spark 应用程序中可能出现的几个内存不足错误示例。
内存不足错误,Java 堆空间
内存不足错误,超出物理内存
内存不足错误,超出虚拟内存
内存不足错误,超出执行程序内存
出现这些问题的原因有很多,其中几个原因如下所示:
- 当 Spark 执行程序实例数、执行程序内存量、核心数或并行度未正确设置以处理大量数据时。
- 当 Spark 执行程序的物理内存超过 YARN 分配的内存时。在此情况下,Spark 执行程序实例内存和内存开销的总和不足以处理内存密集型操作。内存密集型操作包括缓存、重排和聚合(使用
reduceByKey、groupBy等)。或者,在某些情况下,Spark 执行程序实例内存和内存开销的总和可能大于yarn.scheduler.maximum-allocation-mb中定义的值。 - Spark 执行程序实例中未提供执行垃圾回收等系统操作所需的内存。
在下面几节中,我将讨论如何正确配置以防止内存不足问题,包括但不限于上述问题。
在 Amazon EMR 上成功配置 Spark 应用程序
下列步骤有助于您在 Amazon EMR 上成功配置 Spark 应用程序。
1.根据应用程序需求确定实例的类型和数量
Amazon EMR 有三种类型的节点:
- 主节点:EMR 集群有一个主节点,充当资源管理器,管理集群和任务。
- 核心节点:核心节点由主节点管理。核心节点运行 YARN NodeManager 守护程序、Hadoop MapReduce 任务和 Spark 执行程序,管理存储、执行任务并向主节点发送脉动信号。
- 任务节点:与核心节点相比,可选的任务节点仅执行任务,不存储任何数据。
最佳实践 1:为 Amazon EMR 集群中的每个节点类型选择合适的实例类型。这一步是在 Amazon EMR 上成功运行任何 Spark 应用程序的关键。
AWS 提供了具有不同范围的 vCPU、存储和内存的实例类型,如 Amazon EMR 文档中所述。根据应用程序是计算密集型还是内存密集型,您可以选择具有正确计算和内存配置的合适实例类型。
对于内存密集型应用程序,首选 R 类型实例而非其他实例类型。对于计算密集型应用程序,首选 C 类型实例。 对于内存和计算平衡的应用程序,首选 M 类型通用实例。
要了解 AWS 提供的每种实例类型的可能用例,请参阅 EC2 服务网站上的 Amazon EC2 实例类型。
确定实例类型后,确定每个节点类型的实例数。您可以根据输入数据集的大小、应用程序执行时间和频率要求来执行此操作。
2.确定 Spark 配置参数
在深入了解 Spark 配置的详细信息之前,我们先用下图来概述执行程序容器内存的组织方式。
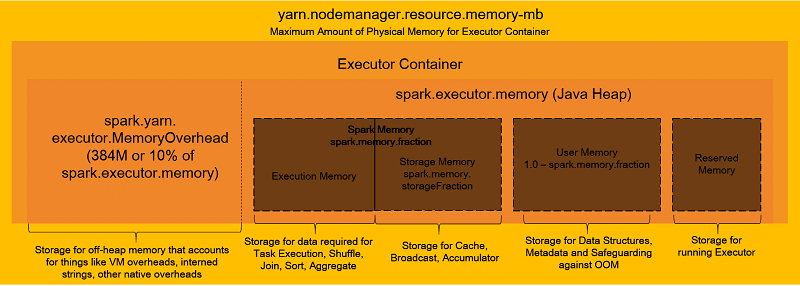
如上图所示,执行程序容器具有多个内存分区。其中,只有一个(执行存储器)实际上用来执行任务。应正确配置这些分区,以便高效且无故障地运行任务。
仔细计算并设置以下 Spark 配置参数以使 Spark 应用程序成功运行:
spark.executor.memory– 用于运行任务的每个执行程序的内存大小。spark.executor.cores– 虚拟核心数。spark.driver.memory– 用于驱动程序的内存大小。spark.driver.cores– 用于驱动程序的虚拟核心数。spark.executor.instances- 执行程序数。除非spark.dynamicAllocation.enabled设为 true,否则请设置此参数。spark.default.parallelism– 当用户未设置分区号时,由join、reduceByKey和parallelize等转换返回的弹性分布式数据集 (RDD) 中的默认分区数。
Amazon EMR 在发布指南中提供了有关如何设置 Spark 参数默认值的高级信息。这些值是根据集群中的核心和任务实例类型在 spark-defaults 设置中自动设置的。
要使用集群中的所有可用资源,请将 maximizeResourceAllocation 参数设为 true。此 EMR 特定选项将计算在核心实例组中的实例上执行程序可用的最大计算和内存资源。然后在 spark-defaults 设置中设置这些参数。即使使用此设置,默认数字通常较小,应用程序也无法充分利用集群的全部力量。例如,spark.default.parallelism 的默认值仅为可用虚拟核心数的 2 倍,但对于大型集群,并行度可能更高。
Spark on YARN 可根据工作负载动态扩展用于 Spark 应用程序的执行程序数。使用 Amazon EMR 版本 4.4.0 及更高版本,将默认启用动态分配(如 Spark 文档中所述)。
spark.dynamicAllocation.enabled 属性的问题是其需要设置子属性。一些示例子属性包括 spark.dynamicAllocation.initialExecutors、minExecutors 和 maxExecutors。大多数情况下,需要设置子属性才能在应用程序的集群中使用正确数量的执行程序,尤其是当您需要同时运行多个应用程序时。设置子属性需要大量的尝试和错误才能找到正确数字。如果数字不正确,则容量可能会保留,实际上不使用。对于其他应用程序来说,这将导致资源浪费或内存错误。
最佳实践 2:只有当正确确定了
spark.dynamicAllocation.initialExecutors/minExecutors/maxExecutors参数的数字时,才将spark.dynamicAllocation.enabled设为 true。否则,将spark.dynamicAllocation.enabled设为 false,并自行控制驱动程序内存、执行程序内存和 CPU 参数。为此,请为每个应用程序手动计算和设置这些属性(参见下面的示例)。
假设我们要处理分布在 Amazon S3 中数千个文件存储中的 200 TB 数据。此外,假设我们通过具有 1 个 r5.12xlarge 主节点和 19 个 r5.12xlarge 核心节点的 Amazon EMR 集群来执行此操作。每个 r5.12xlarge 实例具有 48 个虚拟核心 (vCPU) 和 384 GB RAM。所有这些计算都是针对 --deploy-mode 集群进行的,我们建议将其用于生产用途。
以下列表描述了如何以前面的案例为例设置一些重要的 Spark 属性。
spark.executor.cores
分配具有大量虚拟核心的执行程序会导致执行程序数减少并降低并行度。分配数量较少的虚拟核心会导致执行程序数增多,从而产生大量的 I/O 操作。根据历史数据,我们建议您为每个执行程序分配 5 个虚拟核心,以便在任何规模的集群中实现最佳结果。
对于前一个集群,对属性 spark.executor.cores 的分配如下所示:spark.executors.cores = 5 (vCPU)
spark.executor.memory
确定每个执行程序的虚拟核心数之后,计算此属性要简单得多。首先,使用虚拟核心和执行程序虚拟核心的总数来计算每个实例的执行程序数。从虚拟核心总数中减去一个虚拟核心,保留给 Hadoop 守护程序。
Number of executors per instance = (total number of virtual cores per instance - 1)/ spark.executors.cores
Number of executors per instance = (48 - 1)/ 5 = 47 / 5 = 9 (rounded down)然后,使用每个实例的总 RAM 和每个实例的执行程序数来计算执行程序总内存。为 Hadoop 守护程序保留 1 GB。
执行程序总内存包括执行程序内存和开销(spark.yarn.executor.memoryOverhead)。将此执行程序总内存中的 10% 分配给内存开销,剩余的 90% 分配给执行程序内存。
spark.driver.memory
我们建议将其设置为 spark.executors.memory。
spark.driver.cores
我们建议将其设置为 spark.executors.cores。
spark.executor.instances
这是通过将执行程序数和实例总数相乘得出的。为驱动程序保留 1 个。
spark.default.parallelism
使用以下公式设置此属性。
警告:虽然计算得出的结果是 1,700 个分区,但我们建议估算每个分区的大小,并使用 coalesce 或 repartition 对此数字进行相应的调整。
如果是数据帧,请配置参数 spark.sql.shuffle.partitions 和 spark.default.parallelism。
尽管前面的参数对于任何 Spark 应用程序都很重要,下列参数也有助于顺利运行应用程序,以避免其他超时和内存相关的错误。建议您在 spark-defaults 配置文件中设置这些参数。
spark.network.timeout– 所有网络交易超时。spark.executor.heartbeatInterval– 每个执行程序与驱动程序之间的脉动信号间隔。此值应大大低于spark.network.timeout。spark.memory.fraction– 用于 Spark 执行和存储的 JVM 堆空间分数值。此值越小,溢出和高速缓存数据移出的频率就越高。spark.memory.storageFraction– 表示为 spark.memory.fraction 预留的区域大小分数值。此值越高,可用于执行的工作内存就越少。这意味着任务可能会更频繁地溢出到磁盘。spark.yarn.scheduler.reporterThread.maxFailures– YARN 使应用程序出现故障之前允许的最大执行程序故障数。spark.rdd.compress– 当设为 true 时,通过压缩 RDD 此属性可以节省大量的空间,但需占用额外的 CPU 时间。spark.shuffle.compress– 当设为 true 时,此属性会压缩映射输出以节省空间。spark.shuffle.spill.compress– 当设为 true 时,此属性将压缩 shuffle 期间溢出的数据。spark.sql.shuffle.partitions– 设置连接和聚合的分区数。spark.serializer– 设置序列化程序以序列化或反序列化数据。对于序列化程序,我推荐 Kyro (org.apache.spark.serializer.KryoSerializer),它比 Java 默认序列化程序速度更快、更为紧凑。
要了解有关上述每个参数的更多信息,请参阅 Spark 文档。
我们建议您考虑使用其他编程技术进行高效的 Spark 处理:
coalesce– 减小分区数量以减少数据移动。repartition– 减小或增大分区数量,并执行数据 shuffle 而不是coalesce操作。partitionBy– 跨分区水平分布数据。bucketBy– 根据散列的列将数据分解为更易于管理的部分(存储桶)。cache/persist– 将数据集拉入集群范围的内存缓存中。当重复访问数据时,比如说查询小型查找数据集或运行迭代算法时,执行此操作很有用。
最佳实践 3:根据应用要求仔细计算前面的附加属性。当提交 Spark 应用程序 (
spark-submit) 或在SparkConf对象中时,在spark-defaults中正确设置这些属性。
3.采用适当的垃圾收集器以有效清除内存
在某些情况下,垃圾收集可能导致内存不足错误。这包括应用程序中存在多个大型 RDD 的情况。当任务执行内存和 RDD 缓存内存之间存在干扰时,会发生其他情况。
您可以使用多个垃圾收集器删除旧对象并将新对象放入内存中。但最新的 Garbage First 垃圾收集器 (G1GC) 克服了旧垃圾收集器的延迟和吞吐量限制问题。
最佳实践 4:通过 Spark 处理大量数据时,始终设置垃圾收集器。
参数 -XX:+UseG1GC 指定了应使用 G1GC 垃圾收集器。(默认为 -XX:+UseParallelGC。) 要了解垃圾收集的频率和执行时间,请使用参数 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps。要快速启动垃圾收集,请将 InitiatingHeapOccupancyPercent 设为 35(默认为 0.45)。这样有助于避免对总内存进行潜在的垃圾收集,此过程可能需要相当长的时间。 示例如下:
4.设置 YARN 配置参数
即使正确计算和设置了所有 Spark 配置属性,虚拟内存不足错误仍然时有发生,因为操作系统会大幅提升虚拟内存。要防止这些应用程序故障,请在 YARN 站点设置中设置以下标志。
最佳实践 5:始终将虚拟和物理内存检查标志设为 false。
5.执行调试和监控
要获取有关 spark 配置选项来源的详细信息,可使用 -verbose 选项运行 spark-submit。此外,还可以使用 Ganglia 和 Spark UI 监控应用程序进度、集群 RAM 使用情况和网络 I/O 等。
在以下示例中,我们使用 Ganglia 图来比较已配置和未配置的 Spark 应用程序之间的结果。
按照所述方法进行配置后,Spark 应用程序可成功处理 10 TB 数据,而 Amazon EMR 集群上未出现任何内存问题,其规格如下:
- 1 个 r5.12xlarge 主节点
- 19 个 r5.12xlarge 核心节点
- 8 TB 总 RAM
- 共 960 个虚拟 CPU
- 170 个执行程序实例
- 5 个虚拟 CPU/执行程序
- 37 GB 内存/执行程序
- 并行度等于 1,700
接下来,可以找到 Ganglia 图供您参考。


如果在同一集群上运行具有默认配置的同一 Spark 应用程序,则会因物理内存不足而出现故障。这是因为默认配置(2 个执行程序实例、并行度为 2、1 个 vCPU/执行程序、8 GB 内存/执行程序)不足以处理 10 TB 数据。虽然集群具有 7.8 TB 内存,但默认配置限制应用程序只能使用 16 GB 的内存,从而导致以下内存不足错误。
此外,对于大型数据集,默认的垃圾收集器不能有效清除足够的内存使任务并行运行,从而导致频繁发生故障。下图有助于将 RAM 使用情况和垃圾收集与默认和 G1GC 垃圾收集器进行比较。使用 G1GC 时,使用的 RAM 保持在 5 TB 以下(参见图中的蓝色区域)。

使用默认垃圾收集器 (CMS) 时,使用的 RAM 超过 5 TB。当连续运行多个任务时,这可能导致 Spark 作业失败。

示例:含配置的 EMR 实例模板
设置 Spark 和 YARN 配置参数的方法有很多种。其中一种是在创建 EMR 集群时传递这些信息。
要执行此操作,请在 Amazon EMR 控制台的编辑软件设置部分输入相应更新的配置模板(输入配置)。或者从 S3 传递配置(从 S3 加载 JSON)。

下面是包含样本值的配置模板。至少为成功的 Spark 应用程序计算并设置以下参数。
小结
在这篇博文中,我详细介绍了可能出现的内存不足错误及其原因以及在 Amazon EMR 上提交 Spark 应用程序时防止这些错误的最佳实践列表。
我和我的同事在深入研究和了解各种 Spark 配置属性并测试多个 Spark 应用程序之后,列出了这些最佳实践。这些最佳实践适用于大多数内存不足的场景,但可能存在一些不适用的罕见场景。但我们相信这篇博文介绍了所有必要的细节,因此您可以调整参数并成功运行 Spark 应用程序。