亚马逊AWS官方博客
使用Amazon SageMaker将基于机器学习的实时洞见分析引入英式橄榄球运动
原文链接:
健力士六国锦标赛始于1883年,最初只是英格兰、爱尔兰、英格兰与威尔士之间组织的本国英式橄榄球锦标赛。法国与意大利先后于1910年和2000年正式加入。作为幸存下来的最古老的传统橄榄球项目之一,英式橄榄球成为全球参与人数最多的重量级体育赛事之一。COVID-19疫情爆发导致2020年冠军赛被迫中止,余下的四场比赛于10月24日恢复举办。而随着人工智能与机器学习(ML)在体育分析领域的应用日益广泛,AWS决定与Stats Perform联手将机器学习驱动的实时统计数据系统引入英式橄榄球赛,旨在提高球迷参与度并提供关于比赛的更多宝贵洞见。
本文总结了本届健力士六国英式橄榄球锦标赛上Stats Perform与AWS的通力合作,使用Amazon SageMaker及其他多项AWS服务开发出一种机器学习驱动型方法,用以在比赛期间实时预测结果并发布罚球得分的几率。AWS基础设施能够以个位数毫秒的延迟迅速完成推理计算,由此得出的结果以Kick Predictor统计信息的形式显示在AWS设计的动态Matchstat结果当中,帮助球迷们对比赛中的关键节点建立更深入的理解。关于使用AWS服务为英式橄榄球开发其他统计信息功能的详情,请参阅六国英式橄榄球网站。
英式橄榄球属于橄榄球的一个分支,每支队伍有23位球员。除了各队场上的15名球员之外,其他替补球员则随时准备接替上场。比赛的目标是拿下高分,而踢球射门正是得分的重要方法之一。准确的踢球能力也因此成为橄榄球场上最重要的技术,其得分方式又分两种:传/跑入端区(得2分)与罚球(得3分)。
预测踢球的成功几率非常重要,如果能够即时给出预测结果,那么球迷的参与度也将显著提升。球员准备踢球时,通常会有40到60秒的停顿时间,在此期间,球迷们会在屏幕上看到Kick Predictor给出的统计信息。评论员也会在此期间预测结果,描述当前的得分难度并比较类似情况下其他踢球手的表现。另外,球队还可能使用踢球概率模型来确定下一次得到罚球机会时应该派哪谁上场。
开发机器学习解决方案
为了计算罚球成功的可能性,Amazon机器学习解决方案实验室使用Amazon SageMaker通过历史赛事数据训练、测试并部署机器学习模型,借此结合现场的实际位置计算得分概率。在以下各节中,我们将具体了解数据集与预处理步骤、模型训练以及模型部署流程。
数据集与预处理
Stats Perform提供了用于训练射门模型的数据集,其中包含2007年至2019年期间46大联赛中各场比赛的数百万个事件。在比赛中收集到的原始JSON事件数据被存储在Amazon Simple Storage Service (Amazon S3)当中。接下来,Amazon SageMaker notebook实例将对其进行解析与预处理。在选定与踢球相关的事件之后,最终整理出的训练数据约包含67000次射门,其中有约50000次(占比75%)成功射门与17000次(占比25%)失败。
下图所示,为示例比赛中的踢球摘要信息。展示了运动员从不同的角度和距离踢球的情况。
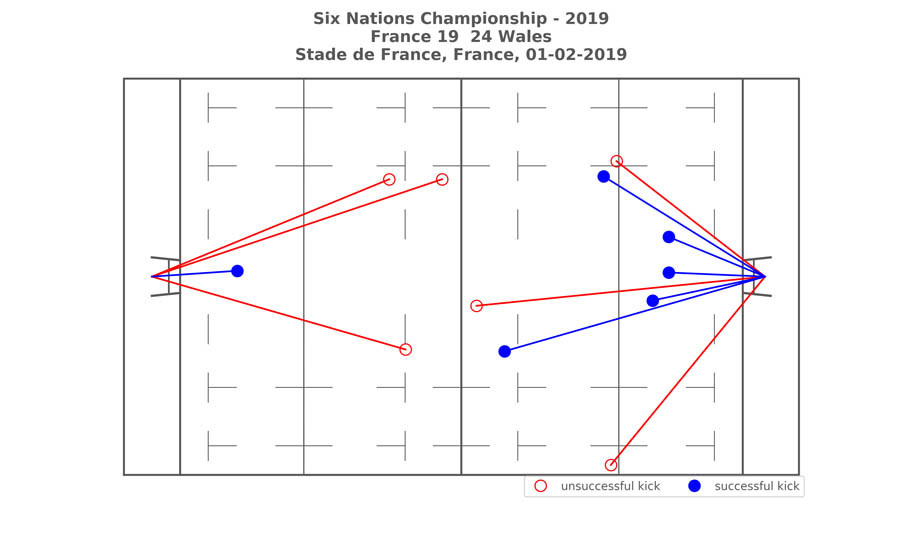
英式橄榄球专家也为数据的预处理提供了宝贵意见,包括检测并消除异常情况,例如不合理的踢球动作等。清洗完成的CSV数据并返回至S3存储桶以进行机器学习训练。
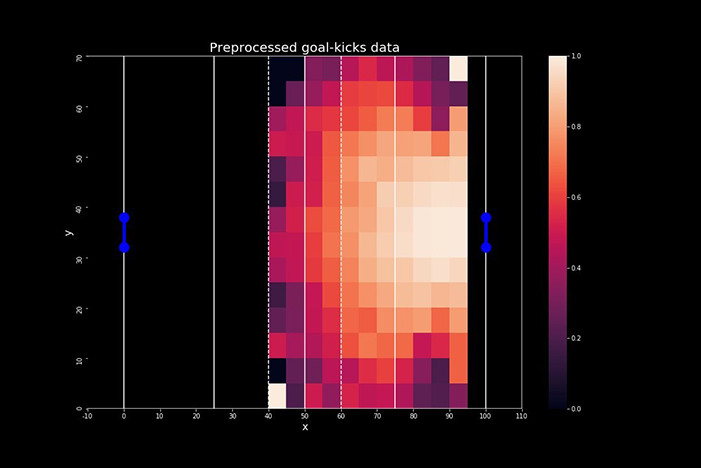
下图所示,为预处理之后的射门热图。左脚为主力脚的射门动作将进行镜像处理。亮度越高的部分,即代表得分机率更高,标准得分介于0到1之间。
特征工程
为了更好地反映现实世界中的事件,机器学习解决方案实验室采用探索性数据分析与英式橄榄球专家的见解设计出多项特征。用于建模的特征主要分为三大类:
- 基于位置的特征——包括运动员的射门动作,以及射门时与球之间的距离及角度。射门活动的x坐标将以橄榄球中心线为基准进行镜像处理,借此消除模型中惯用左脚及惯用右脚引发的偏差。
- 球员表现特征——踢球手在特定区域内、锦标赛中乃至整个职业生涯的平均射门成功率。
- 比赛内情境特征——踢球手的球队(主场或客场)、踢球前的得分情况以及当前射门在整场比赛中的所处时段。
基于位置的特征与球员表现特征也是模型当中最重要的特征所在。
在特征工程处理之后,还需要对分类变量进行一轮热编码;为了避免模型出现大值变量偏差,我们还对数值预测器进行了标准化。在模型训练阶段,球员的历史表现特征将被推送至Amazon DynamoDB表中。DynamoDB将帮助系统在推理过程中以个位数毫秒的延迟提供射门预测。
训练与部署模型
为了探索广泛的分类算法(例如逻辑回归、随机森林、XGBoost以及神经网络等),我们使用了10倍分层交叉验证法(stratified cross-validation)进行模型训练。在探索之后,我们发现Amazon SageMaker所内置的XGBoost拥有更高的预测性能以及更快的推理速度。此外,与原始代码库相比,XGBoost实现占用的内存空间更小、日志记录更全面、超参数优化(HPO)质量更高。
超参数优化又被称为调优,指的是为学习算法选择一组最佳超参数的过程。事实上,这也是任何机器学习过程中最具挑战的工作。Amazon SageMaker中的HPO使用贝叶斯优化实现,旨在为下一项训练作业选定最佳超参数。Amazon SageMaker HPO会自动启动采用不同超参数设置的多项训练作业,并根据预定义的客观指标评估训练结果,而后根据先前的结果为后续训练选择更好的超参数搭配。
下图所示,为模型训练工作流的基本架构。

在Amazon SageMaker中优化超参数
大家可以通过初始化估算器(estimator),借此配置训练作业以及何时启动超参数调优作业。这里的估算器包含算法的容器镜像(在本用例中为XGBoost)、训练作业的输出配置、静态算法的超参数值,以及用于训练作业的实例类型及数量。关于更多详细信息,请参阅训练模型。
要为本用例创建XGBoost估算器,请输入以下代码:
import boto3
import sagemaker
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
from sagemaker.amazon.amazon_estimator import get_image_uri
BUCKET = <bucket name>
PREFIX = 'kicker/xgboost/'
region = boto3.Session().region_name
role = sagemaker.get_execution_role()
smclient = boto3.Session().client('sagemaker')
sess = sagemaker.Session()
s3_output_path = ‘s3://{}/{}/output’.format(BUCKET, PREFIX)
container = get_image_uri(region, 'xgboost', repo_version='0.90-1')
xgb = sagemaker.estimator.Estimator(container,
role,
train_instance_count=4,
train_instance_type= 'ml.m4.xlarge',
output_path=s3_output_path,
sagemaker_session=sess)
在完成XGBoost估算器对象的创建之后,使用以下代码为其设定初始超参数值:
xgb.set_hyperparameters(eval_metric='auc',
objective= 'binary:logistic',
num_round=200,
rate_drop=0.3,
max_depth=5,
subsample=0.8,
gamma=2,
eta=0.2,
scale_pos_weight=2.85) #类不平衡权重
# 指定目标指标(验证集的auc)
OBJECTIVE_METRIC_NAME = ‘validation:auc’
# 指定超参数及其范围
HYPERPARAMETER_RANGES = {'eta': ContinuousParameter(0, 1),
'alpha': ContinuousParameter(0, 2),
'max_depth': IntegerParameter(1, 10)}
在本文中,我们使用AUC(ROC曲线下面积)作为评估指标。以此为基础,调优作业得以衡量不同训练作业的性能。射门预测同样属于典型的二元分类问题,在objective参数中指定为binary:logistic。大家还可以对另一组XGBoost专用超参数进行调优。关于更多详细信息,请参阅XGBoost模型调优。
接下来,通过指示XGBoost估算器、超参数范围、传递参数、设置目标指标名称与定义、调节资源配置(例如需要运行的总训练作业数量以及可以并发运行的训练作业)这一系列过程创建出HyperparameterTuner对象。Amazon SageMaker会使用正则表达式从Amazon CloudWatch Logs 当中提取指标,具体参见以下代码:
tuner = HyperparameterTuner(xgb,
OBJECTIVE_METRIC_NAME,
HYPERPARAMETER_RANGES,
max_jobs=20,
max_parallel_jobs=4)
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(BUCKET, PREFIX), content_type='csv')
s3_input_validation = sagemaker.s3_input(s3_data='s3://{}/{}/validation/'.format(BUCKET, PREFIX), content_type='csv')
tuner.fit({'train': s3_input_train, 'validation':
最后,通过调用fit() 函数启动超参数调优作业。此函数将使用S3存储桶中的训练与验证数据集路径。在创建超参数调优作业之后,您可以通过Amazon SageMaker控制台跟踪其进度。训练时间取决于实例类型以及您在调优设置当中选择的实例数量。
在Amazon SageMaker上部署模型
在训练作业完成之后,您可以部署性能最佳的模型。如果希望比较模型性能以进行A/B测试,Amazon SageMaker也支持为多个模型托管代表性状态传输(REST)终端节点。要进行此设置,请创建一个终端节点配置,在其中描述模型之间的流量分发方式。此外,终端节点配置还将描述模型部署所需要的实例类型。这里我们首先获取性能最佳训练作业的名称,并创建模型名称。
在终端节点配置创建完成之后,即可部署实际终端节点以支持推理请求。我们需要验证示例端点,并将其合并至生产应用程序当中。关于部署模型的更多详细信息,请参阅将模型部署至Amazon SageMaker托管服务。要创建终端节点并调整配置,请输入以下代码:
endpoint_name = 'Kicker-XGBoostEndpoint'
xgb_predictor = tuner.deploy(initial_instance_count=1,
instance_type='ml.t2.medium',
endpoint_name=endpoint_name)
在终端节点创建完成之后,即可实时请求预测结果。
为实时模型推理构建RESTful API
我们可以创建一个安全且可扩展的RESTful API,基于输入值请求模型预测。在AWS服务的帮助下,大家能够轻松便捷地创建出各种不同API。
下图所示,为模型推理工作流的基本架构。

首先,我们通过Amazon API Gateway传递参数以请求踢球进入端区的可能性,具体参数包括踢球的位置与区域、踢球手ID、当前联赛及冠军ID、比赛时段、踢球者所属球队当前为主队还是客队、球队当前得分状态等。
API Gateway将这些值传递给AWS Lambda函数,由函数解析这些值并从DynamoDB表中请求与球员表现相关的其他特征,包括踢球手的所处区域、其在当前锦标赛乃至整个职业生涯中的平均成功率等。如果数据库中不存在此球员,则模型会使用平均表现作为预设。该函数在完成所有数值组合之后,即可对数据进行标准化并将结果发送至Amazon SageMaker模型端点进行预测。
该模型执行预测,并将预测到的概率返回至Lambda函数。此函数解析返回的值,再将结果发送回API Gateway。API Gateway响应输出结果,整个端到端进程的延迟不足1秒。
以下截屏所示,为API的示例输入与输出。RESTful API还会输出特定位置及区域中所有球员的平均成功率,借此比较球员表现及整体平均水平。

关于创建RESTful API的具体操作说明,请参阅使用Amazon API Gateway与AWS Lambda调用Amazon SageMaker模型端点。
将设计原则引入体育分析
为了创建第一套延迟在毫秒级别的实时锦标赛预测模型,机器学习解决方案实验室采取逆向工程方式,借此确定如何尽可能节约时间及资源。该团队在Amazon SageMaker环境中的端到端notebook上不断探索,希望在这套统一的平台上尝试数据访问、原始数据解析、数据预处理及可视化、特征工程、模型训练与评估以及模型部署。以此为基础,整个建模流程的自动化程度得到显著提升。
此外,机器学习解决方案实验室团队还使用新生成的数据更新模型,借此实现模型的持续迭代。这种方式极大提升了建模工作的计算效率与时间效率。
在后续计划中,Stats Perform AI团队决定深入研究英式橄榄球分析的发展方向,尝试使用这项技术解析阵容、战术讨论,并使用细粒度且具备时空连续性的比赛数据。凭借新的特征表示与潜在因子建模(二者已经在Stats Perform的Edge比赛分析与球员招募产品中得到有效应用),相信英式橄榄球运动将会迎来更广阔的创新空间。
总结
Stats Perform与AWS共同为2020年健力士六国英式橄榄球锦标赛带来第一套实时预测模型。此模型能够在球场上的任意位置做出罚球或端区突破的成功概率。他们使用Amazon SageMaker构建、训练并部署机器学习模型,并将变量分为三大主要类别:基于位置的特征、球员表现特征以及比赛情境特征。Amazon SageMaker端点能够以亚秒级延迟提供的预测结果,成功帮助主办方在比赛的现场直播当中为数百万球迷提供实时指标。
大家可以在AWS Labs GitHub repo上找到完整的端到端示例,借此创建自定义训练作业、训练最新的对象检测模型并在Amazon SageMaker上进行模型部署。要了解关于机器学习解决方案实验室的更多信息,请参阅 Amazon机器学习解决方案实验室。