亚马逊AWS官方博客
使用 Apache Flink 在 Amazon EMR 上构建统一数据湖
为了建立数据驱动型企业,在数据目录中实现企业数据资产的大众化非常重要。利用统一的数据目录,您可以快速搜索数据集,并确定数据架构、数据格式和位置。AWS Glue Data Catalog 提供了一个统一的存储库,让不同的系统能够存储和查找元数据,以跟踪数据孤岛中的数据。
Apache Flink 是一个应用广泛的数据处理引擎,适用于可扩展的流式处理 ETL、分析和事件驱动型应用程序。该应用程序提供具备容错能力的精确时间和状态管理。Flink 可以使用统一的 API 或应用程序处理有界流(批处理)和无界流(流式处理)。在使用 Apache Flink 处理数据后,下游应用程序可以使用统一的数据目录访问精心整理的数据。有了统一的元数据,数据处理和数据消耗应用程序都可以使用相同的元数据访问表。
这篇文章向您展示了如何将 Amazon EMR 中的 Apache Flink 与 AWS Glue Data Catalog 集成,以便您可以实时提取流数据,并近乎实时地访问数据进行业务分析。
Apache Flink 连接器和目录架构
Apache Flink 使用连接器和目录,与数据和元数据进行交互。下图显示了用于读取/写入数据的 Apache Flink 连接器以及用于读取/写入元数据的目录架构。
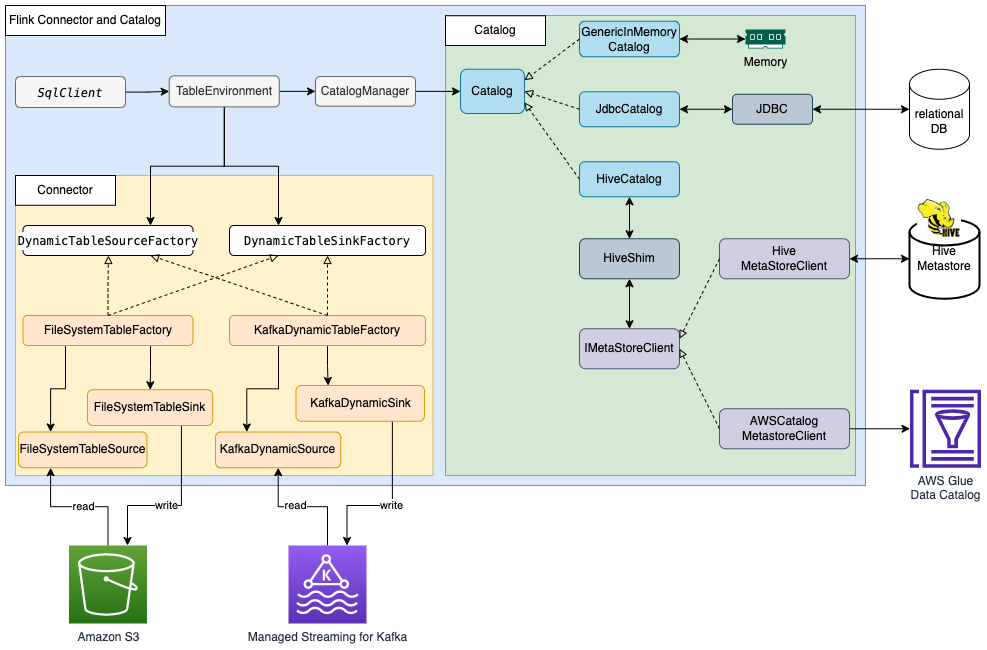
为了读取/写入数据,Flink 提供了用于读取操作的 DynamicTableSourceFactory 接口以及用于写入操作的 DynamicTableSinkFactory 接口。另有一个 Flink 连接器实施两个接口,用于访问不同存储中的数据。例如,Flink FileSystem 连接器提供了 FileSystemTableFactory,用于在 Hadoop Distributed File System(HDFS)或 Amazon Simple Storage Service(Amazon S3)中读取/写入数据;Flink HBase 连接器提供了 HBase2DynamicTableFactory,用于在 HBase 中读取/写入数据;而 Flink Kafka 连接器提供了 KafkaDynamicTableFactory,用于在 Kafka 中读取/写入数据。您可以参考表和 SQL 连接器,了解更多信息。
对于元数据的读取/写入,Flink 提供了目录接口。Flink 有三种内置的目录实施。GenericInMemoryCatalog 将目录数据存储在内存中。JdbcCatalog 将目录数据存储在 JDBC 支持的关系数据库中。截至目前,JDBC 目录支持 MySQL 和 PostgreSQL 数据库。HiveCatalog 将目录数据存储在 Hive Metastore 中。HiveCatalog 使用 HiveShim 来提供不同的 Hive 版本兼容性。我们可以配置不同的 Metastore 客户端,以使用 Hive Metastore 或 AWS Glue Data Catalog。在这篇文章中,我们将 Amazon EMR 属性 hive.metastore.client.factory.class 配置为 com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory(请参阅使用 AWS Glue Data Catalog 作为 Hive 的 Metastore),这样我们就可以使用 AWS Glue Data Catalog 来存储 Flink 目录数据。有关更多信息,请参阅目录。
大多数 Flink 内置连接器(例如 Kafka、Amazon Kinesis、Amazon DynamoDB、Elasticsearch 或 FileSystem)都可以使用 Flink HiveCatalog,将元数据存储在 AWS Glue Data Catalog 中。然而,一些连接器实施(如 Apache Iceberg)有单独的目录管理机制。Iceberg 中的 FlinkCatalog 实施了 Flink 中的目录接口。Iceberg 中的 FlinkCatalog 对自己的目录实施提供了封装机制。下图显示了 Apache Flink、Iceberg 连接器和目录之间的关系。有关更多信息,请参阅创建目录和使用目录以及目录。
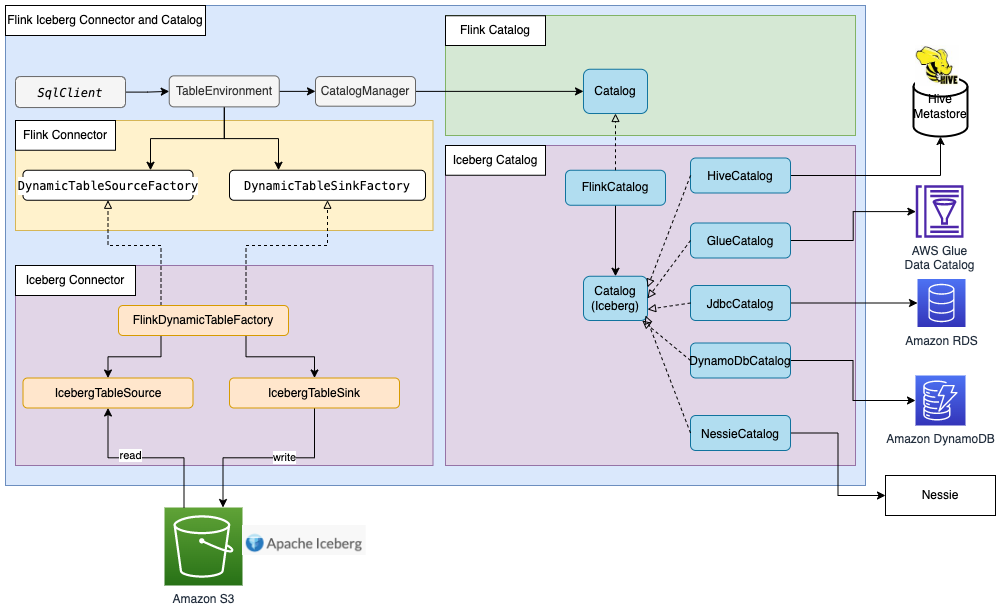
Apache Hudi 也有自己的目录管理功能。HoodieCatalog 和 HoodieHiveCatalog 都在 Flink 中实施了目录接口。HoodieCatalog 将元数据存储在诸如 HDFS 这样的文件系统中。HoodieHiveCatalog 将元数据存储在 Hive Metastore 或 AWS Glue Data Catalog 中,具体取决于您是否将 hive.metastore.client.factory.class 配置为使用 com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory。下图显示了 Apache Flink、Hudi 连接器和目录之间的关系。有关更多信息,请参阅创建目录。

由于 Iceberg 和 Hudi 有不同的目录管理机制,我们在这篇文章中展示了 Flink 与 AWS Glue Data Catalog 集成的三种场景:
- 使用 Glue Data Catalog 中的元数据,在 Flink 中读取/写入 Iceberg 表
- 使用 Glue Data Catalog 中的元数据,在 Flink 中读取/写入 Hudi 表
- 使用 Glue Data Catalog 中的元数据,在 Flink 中读取/写入其他存储格式
解决方案概览
下图显示了本文章中描述的解决方案的整体架构。
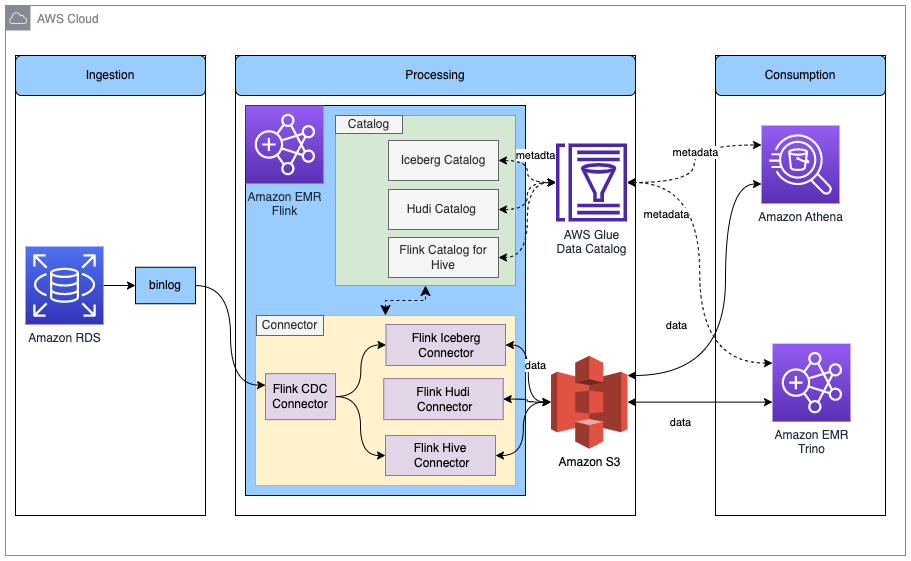
在此解决方案中,我们启用 Amazon RDS for MySQL binlog 来实时提取事务更改。Amazon EMR Flink CDC 连接器读取 binlog 数据并处理数据。经过转换的数据可以存储在 Amazon S3 中。我们使用 AWS Glue Data Catalog 来存储元数据,例如表架构和表位置。Amazon Athena 或 Amazon EMR Trino 等下游数据使用者应用程序访问数据,以便用于业务分析。
下面是设置此解决方案的大致步骤:
- 为 Amazon RDS for MySQL 启用
binlog并初始化数据库。 - 使用 AWS Glue Data Catalog 创建 EMR 集群。
- 在 Amazon EMR 中使用 Apache Flink CDC 提取更改数据捕获(CDC, Change Data Capture)数据。
- 将处理后的数据存储在 Amazon S3 中,并将元数据存储在 AWS Glue Data Catalog 中。
- 确认所有表元数据都存储在 AWS Glue Data Catalog 中。
- 通过 Athena 或 Amazon EMR Trino 使用数据进行业务分析。
- 更新和删除 Amazon RDS for MySQL 中的源记录,并验证数据湖表中是否发生相应更改。
先决条件
这篇文章使用具有以下服务权限的 AWS Identity and Access Management(IAM)角色:
- Amazon RDS for MySQL (5.7.40)
- Amazon EMR (6.9.0)
- Amazon Athena
- AWS Glue Data Catalog
- Amazon S3
为 Amazon RDS for MySQL 启用 binlog 并初始化数据库
要在 Amazon RDS for MySQL 中启用 CDC,我们需要为 Amazon RDS for MySQL 配置二进制日志记录。有关更多信息,请参阅配置 MySQL 二进制日志记录。我们还在 MySQL 中创建数据库 salesdb,并创建 customer、order 表和其他表,以便设置数据来源。
- 在 Amazon RDS 控制台上,在导航窗格中选择 Parameter groups(参数组)。
- 为 MySQL 创建一个新的参数组。
- 编辑您刚刚创建的参数组,设置
binlog_format=ROW。
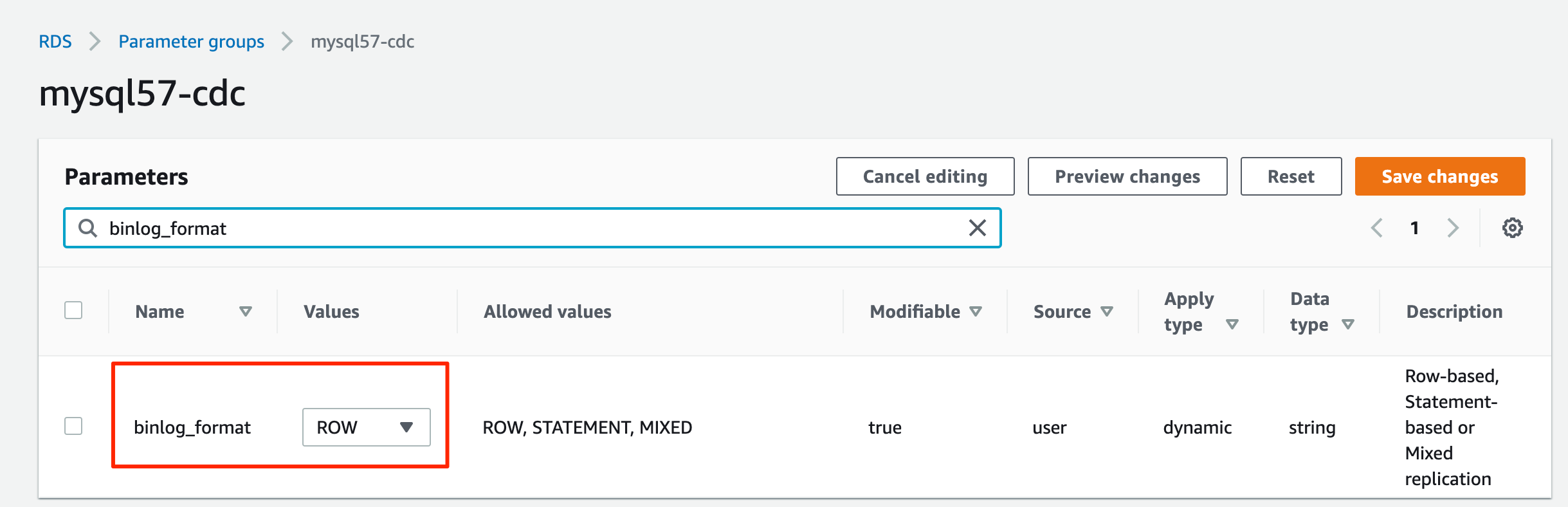
- 编辑您刚刚创建的参数组,设置
binlog_row_image=full。
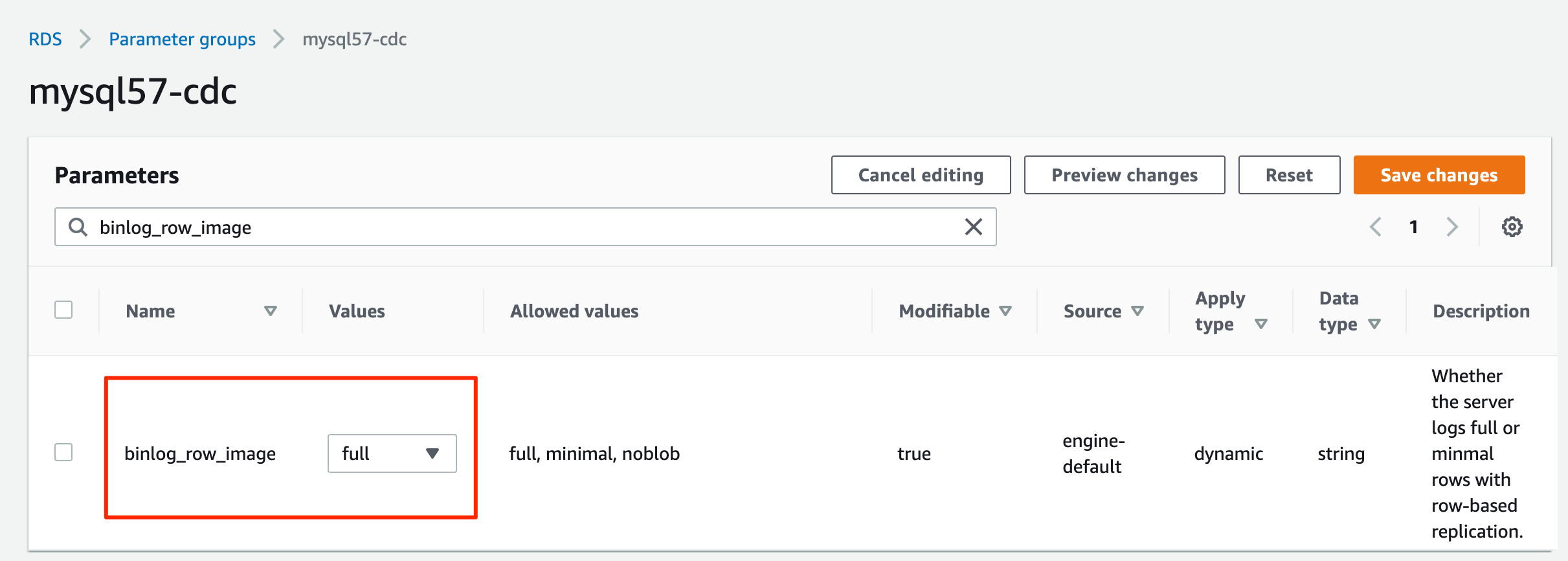
- 使用参数组创建 RDS for MySQL 数据库实例。
- 记下
hostname、username和password的值,我们稍后会使用这些值。 - 运行以下命令,从 Amazon S3 下载 MySQL 数据库初始化脚本:
- 连接到 RDS for MySQL 数据库并运行
salesdb.sql命令以初始化数据库,根据您的 RDS for MySQL 数据库配置提供主机名和用户名:
使用 AWS Glue Data Catalog 创建 EMR 集群
从 Amazon EMR 6.9.0 开始,Flink 表 API/SQL 可以与 AWS Glue Data Catalog 集成。要使用 Flink 与 AWS Glue 的集成,您必须创建 Amazon EMR 6.9.0 或更高版本。
- 为 Amazon EMR Trino 与 Data Catalog 的集成创建文件
iceberg.properties。当表格式为 Iceberg 时,您的文件应包含如下内容:
- 将
iceberg.properties上传到 S3 存储桶,例如DOC-EXAMPLE-BUCKET。
有关如何将 Amazon EMR Trino 与 Iceberg 集成的更多信息,请参阅将 Iceberg 集群与 Trino 结合使用。
- 创建
trino-glue-catalog-setup.sh文件以配置 Trino 与 Data Catalog 的集成。使用trino-glue-catalog-setup.sh作为引导脚本。您的文件应包含以下内容(将DOC-EXAMPLE-BUCKET替换为 S3 存储桶名称):
- 将
trino-glue-catalog-setup.sh上传到 S3 存储桶(DOC-EXAMPLE-BUCKET)。
要运行引导脚本,请参阅创建引导操作以安装其它软件。
- 创建
flink-glue-catalog-setup.sh文件,以配置 Flink 与 Data Catalog 的集成。 - 使用脚本运行器,将
flink-glue-catalog-setup.sh脚本作为步骤函数运行。
您的文件应包含以下内容(此处的 JAR 文件名使用 Amazon EMR 6.9.0;更高版本的 JAR 名称可能会有所不同,因此请务必根据 Amazon EMR 版本进行更新)。
请注意,此处我们使用 Amazon EMR 步骤而不是引导程序来运行此脚本。在预置 Amazon EMR Flink 后,将运行 Amazon EMR 步骤脚本。
- 将
flink-glue-catalog-setup.sh上传到 S3 存储桶(DOC-EXAMPLE-BUCKET)。
有关如何配置 Flink 和 Hive Metastore 的更多信息,请参阅在 Amazon EMR 中将 Flink 配置为 Hive Metastore。有关运行 Amazon EMR 步骤脚本的更多详细信息,请参阅在 Amazon EMR 集群上运行命令和脚本。
- 使用 Hive、Flink 和 Trino 应用程序创建 EMR 6.9.0 集群。
您可以使用 AWS 命令行界面(AWS CLI)或 AWS 管理控制台创建 EMR 集群。有关说明,请参阅相应的小节。
使用 AWS CLI 创建 EMR 集群
要使用 AWS CLI,请完成以下步骤:
- 创建
emr-flink-trino-glue.json文件,以将 Amazon EMR 配置为使用 Data Catalog。您的文件应包含以下内容:
- 运行以下命令创建 EMR 集群。提供您的本地
emr-flink-trino-glue.json父文件夹路径、S3 存储桶、EMR 集群区域、EC2 密钥名称和存储 EMR 日志的 S3 存储桶。
在控制台上创建 EMR 集群
要使用控制台,请完成以下步骤:
- 在 Amazon EMR 控制台上,创建 EMR 集群,然后在 AWS Glue Data Catalog 设置中选择 Use for Hive table metadata(用于 Hive 表元数据)。
- 使用以下代码添加配置设置:

- 在 Steps(步骤)部分中,添加一个名为 Custom JAR(自定义 JAR)的步骤。
- 将 JAR location(JAR 位置)设置为
s3://<region>.elasticmapreduce/libs/script-runner/script-runner.jar,其中 <region> 是 EMR 集群所在的区域。 - 将 Arguments(参数)设置为您之前上传的 S3 路径。

- 在 Bootstrap Actions(引导操作)部分中,选择 Custom Action(自定义操作)。
- 将 Script location(脚本位置)设置为您上传的 S3 路径。

- 继续执行后续步骤以完成 EMR 集群的创建。
在 Amazon EMR 中使用 Apache Flink CDC 提取 CDC 数据
Flink CDC 连接器支持读取数据库快照,并捕获配置的表中的更新。我们已经通过下载 flink-sql-connector-mysql-cdc-2.2.1.jar 并在创建 EMR 集群时将其放入 Flink 库,部署了适用于 MySQL 的 Flink CDC 连接器。Flink CDC 连接器可以使用 Flink Hive 目录将 Flink CDC 表架构存储到 Hive Metastore 或 AWS Glue Data Catalog 中。在这篇文章中,我们使用 Data Catalog 来存储我们的 Flink CDC 表。
完成以下步骤,使用 Flink CDC 提取 RDS for MySQL 数据库和表,并将元数据存储在 Data Catalog 中:
- 通过 SSH 连接到 EMR 主节点。
- 通过运行以下命令在 YARN 会话上启动 Flink,提供您的 S3 存储桶名称:
- 运行以下命令来启动 Flink SQL 客户端 CLI:
- 通过将目录类型指定为
hive并提供您的 S3 存储桶名称,创建 Flink Hive 目录:
因为我们使用 AWS Glue Data Catalog 配置 EMR Hive 目录,所以在 Flink Hive 目录中创建的所有数据库和表都存储在 Data Catalog 中。
- 创建 Flink CDC 表,提供您先前创建的 RDS for MySQL 实例的主机名、用户名和密码。
请注意,由于 RDS for MySQL 的用户名和密码将作为表属性存储在 Data Catalog 中,因此您应启用使用 AWS Lake Formation 的 AWS Glue 数据库/表授权,以便保护您的敏感数据。
- 查询您刚刚创建的表:
您会得到一个查询结果,如下面的屏幕截图所示。

将处理后的数据存储在 Amazon S3 中,并将元数据存储在 Data Catalog 中
当我们在 Amazon RDS for MySQL 中提取关系数据库数据时,原始数据可能会发生更新或被删除。为了支持数据更新和删除,我们可以选择诸如 Apache Iceberg 或 Apache Hudi 这样的数据湖技术来存储处理后的数据。正如我们之前提到的,Iceberg 和 Hudi 有不同的目录管理机制。我们展示了两种使用 Flink 读取/写入在 AWS Glue Data Catalog 中包含元数据的 Iceberg 和 Hudi 表的场景。
对于非 Iceberg 和非 Hudi,我们使用 FileSystem Parquet 文件来显示 Flink 内置连接器是如何使用 Data Catalog 的。
使用 Glue Data Catalog 中的元数据,在 Flink 中读取/写入 Iceberg 表
下图显示了此配置的架构。

- 通过将
catalog-impl指定为org.apache.iceberg.aws.glue.GlueCatalog,使用 Data Catalog 创建 Flink Iceberg 目录。
有关 Iceberg 的 Flink 和 Data Catalog 集成的更多信息,请参阅 Glue 目录。
- 在 Flink SQL 客户端 CLI 中,运行以下命令,提供您的 S3 存储桶名称:
- 创建一个 Iceberg 表来存储处理后的数据:
- 将处理后的数据插入到 Iceberg 中:
使用 Glue Data Catalog 中的元数据,在 Flink 中读取/写入 Hudi 表
下图显示了此配置的架构。
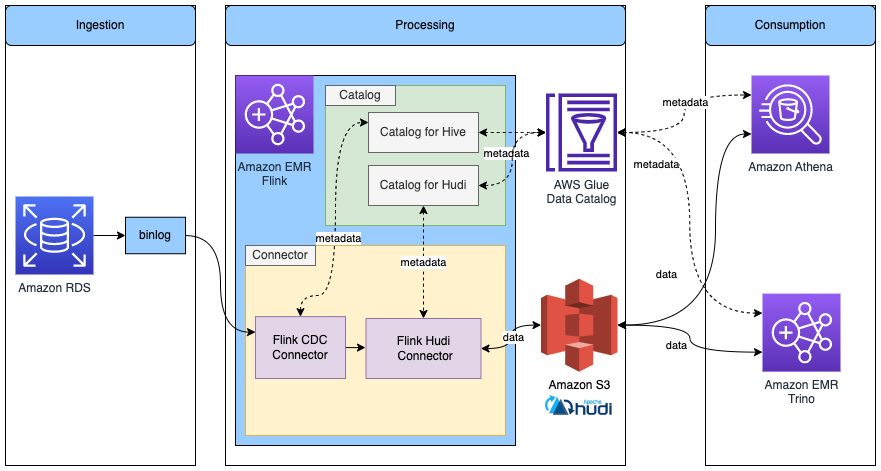
请完成以下步骤:
- 通过将
mode指定为hms,为 Hudi 创建一个使用 Hive 目录的目录。
因为我们在创建 EMR 集群时已经将 Amazon EMR 配置为使用 Data Catalog,所以此 Hudi Hive 目录在后台使用 Data Catalog。有关 Hudi 的 Flink 和 Data Catalog 集成的更多信息,请参阅创建目录。
- 在 Flink SQL 客户端 CLI 中,运行以下命令,提供您的 S3 存储桶名称:
- 使用 Data Catalog 创建 Hudi 表,并提供您的 S3 存储桶名称:
- 将处理后的数据插入到 Hudi 中:
使用 Glue Data Catalog 中的元数据,在 Flink 中读取/写入其他存储格式
下图显示了此配置的架构。
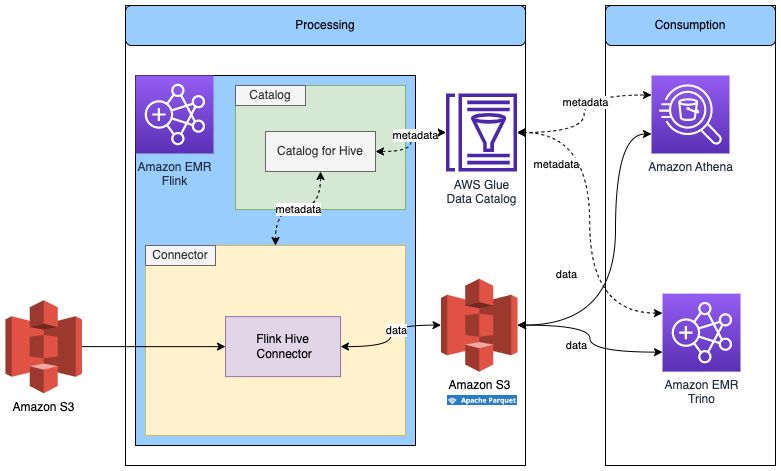
我们已经在上一步中创建了 Flink Hive 目录,因此我们将重用该目录。
- 在 Flink SQL 客户端 CLI 中,运行以下命令:
我们将 SQL 方言更改为 Hive,以使用 Hive 语法创建一个表。
- 使用以下 SQL 创建一个表,并提供您的 S3 存储桶名称:
由于 Parquet 文件不支持更新的行,因此我们无法使用来自 CDC 数据的数据。不过,我们可以使用来自 Iceberg 或 Hudi 的数据。
- 使用以下代码查询 Iceberg 表并将数据插入到 Parquet 表中:
确认所有表元数据都存储在 Data Catalog 中
您可以导航到 AWS Glue 控制台,以确认所有表都存储在 Data Catalog 中。
- 在 AWS Glue 控制台上,选择导航窗格中的 Databases(数据库)以列出我们创建的所有数据库。

- 打开一个数据库,并验证所有表是否都在该数据库中。

通过 Athena 或 Amazon EMR Trino 使用数据进行业务分析
您可以使用 Athena 或 Amazon EMR Trino 来访问结果数据。
使用 Athena 查询数据
要使用 Athena 访问数据,请完成以下步骤:
- 打开 Athena 查询编辑器。
- 为 Database(数据库)选择
flink_glue_iceberg_db。
您应该会看到列出的 customer_summary 表。
- 运行以下 SQL 脚本来查询 Iceberg 结果表:
查询结果将类似以下屏幕截图所示。
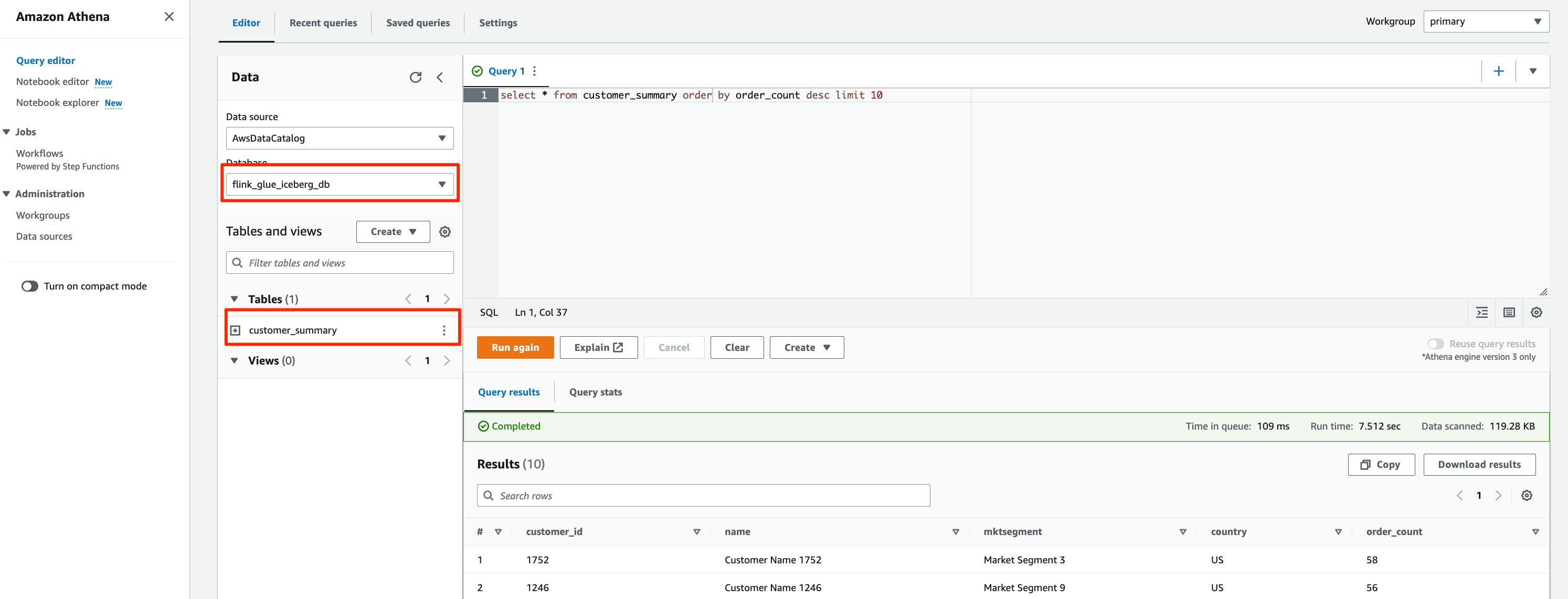
- 对于 Hudi 表,将 Database(数据库)更改为
flink_glue_hudi_db,然后运行相同的 SQL 查询。

- 对于 Parquet 表,将 Database(数据库)更改为
flink_hive_parquet_db,然后运行相同的 SQL 查询。

使用 Amazon EMR Trino 查询数据
要使用 Amazon EMR Trino 访问 Iceberg,请通过 SSH 连接到 EMR 主节点。
- 运行以下命令以启动 Trino CLI:
Amazon EMR Trino 现在可以查询 AWS Glue Data Catalog 中的表。
- 运行以下命令来查询结果表:
查询结果类似于以下屏幕截图。

- 退出 Trino CLI。
- 使用
hivecatalog 启动 Trino CLI 以查询 Hudi 表:
- 运行以下命令来查询 Hudi 表:
更新和删除 Amazon RDS for MySQL 中的源记录,并验证数据湖表中是否发生相应更改
我们可以在 RDS for MySQL 数据库中更新和删除一些记录,然后验证更改是否反映在 Iceberg 和 Hudi 表中。
- 连接到 RDS for MySQL 数据库并运行以下 SQL:
- 使用 Athena 或 Amazon EMR Trino 查询
customer_summary表。
更新和删除的记录反映在 Iceberg 和 Hudi 表中。

清理
完成本练习后,请完成以下步骤以删除您的资源并停止产生费用:
- 删除 RDS for MySQL 数据库。
- 删除 EMR 集群。
- 删除在 Data Catalog 中创建的数据库和表。
- 删除 Amazon S3 中的文件。
小结
这篇文章向您展示了如何将 Amazon EMR 中的 Apache Flink 与 AWS Glue Data Catalog 集成。您可以使用 Flink SQL 连接器在不同的存储区读取/写入数据,例如 Kafka、CDC、HBase、Amazon S3、Iceberg 或 Hudi。您也可以将元数据存储在 Data Catalog 中。Flink 表 API 具有相同的连接器和目录实施机制。在单个会话中,我们可以使用多个指向不同类型的目录实例(如 IcebergCatalog 和 HiveCatalog),然后在查询中互换使用它们。您也可以使用 Flink 表 API 编写代码,开发集成 Flink 与 Data Catalog 的相同解决方案。
在我们的解决方案中,我们直接通过 Flink CDC 使用了 RDS for MySQL 二进制日志。您也可以使用 Amazon MSK Connect 通过 MySQL Debezim 使用二进制日志,并将数据存储在 Amazon Managed Streaming for Apache Kafka(Amazon MSK)中。有关更多信息,请参阅使用 Amazon MSK Connect、Apache Flink 和 Apache Hudi 创建低延迟的源到数据湖管道。
借助 Amazon EMR Flink 统一的批处理和流式数据处理功能,您可以通过一个计算引擎提取和处理数据。通过将 Apache Iceberg 和 Hudi 集成到 Amazon EMR 中,您可以构建一个可演变且可扩展的数据湖。通过 AWS Glue Data Catalog,您可以统一管理所有企业数据目录并轻松使用数据。
按照这篇文章中的步骤,使用 Amazon EMR Flink 和 AWS Glue Data Catalog 构建统一的批处理和流处理解决方案。如果您有任何疑问,请发表评论。
关于作者
 Jianwei Li 是 TAM 的高级分析专家。他为 AWS Enterprise Support 客户提供设计和构建现代数据平台的顾问服务。
Jianwei Li 是 TAM 的高级分析专家。他为 AWS Enterprise Support 客户提供设计和构建现代数据平台的顾问服务。

Samrat Deb 是 Amazon EMR 的软件开发工程师。闲暇时,他喜欢探索新的地方、不同的文化和美食。

Prabhu Josephraj 是 Amazon EMR 的高级软件开发工程师。他专注于领导团队在 Apache Hadoop 和 Apache Flink 中构建解决方案。闲暇时,Prabhu 喜欢与家人共度时光。