亚马逊AWS官方博客
使用 Amazon SageMaker 与 Amazon ES 构建一款视觉搜索应用程序
有时候,我们可能很难找到合适的词汇来描述自己想要寻找的东西。正如俗语所言,“一图抵千言。”一般来说,展示真实示例或者图像,对于目标的表达效果确实要比纯文字描述好上不少。这一点,在使用搜索引擎查找所需内容时显得尤其突出。
在本文中,我们将在一个小时的演练中从零开始构建一款视觉图像搜索应用程序,其中包含用于提供视觉搜索结果的全栈Web应用程序。
视觉搜索能够提高客户在零售业务与电子商务中的参与度,这种功能对于时尚及家庭装饰零售商而言尤其重要。视觉搜索允许零售商向购物者推荐与主题或特定造型相关的商品,这是传统纯文本查询所无法做到的。根据Gartner公司的报告,“到2021年,重新设计网站以支持视觉及语音搜索的早期采用者品牌,将推动数字商务收入增长30%。”
视觉搜索的高级示例
Amazon SageMaker是一项全托管服务,可为每位开发人员及数据科学家提供快速构建、训练以及部署机器学习(ML)模型的能力。Amazon Elasticsearch Service (Amazon ES)同样为全托管服务,可帮助您轻松以符合成本效益的方式大规模部署、保护并运行Elasticsearch。Amazon ES还提供k最近邻(KNN)搜索,能够在相似性用例中增强搜索能力,适用范围涵盖产品推荐、欺诈检测以及图像、视频与语义文档检索。KNN使用轻量化且效率极高的非度量空间库(NMSLIB)构建而成,可在数千个维度上对数十亿个文档进行大规模、低延迟最近邻搜索,且实现难度与常规Elasticsearch查询完全一致。
下图所示,为这套视觉搜索架构的基本形式。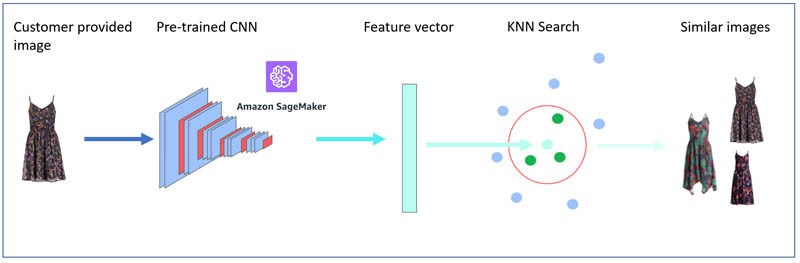
解决方案概述
视觉搜索架构的实现分为两个阶段:
- 通过示例图像数据集在Amazon ES上构建参考KNN索引。
- 向Amazon SageMaker端点提交一份新图像,并由Amazon ES返回相似图像。
创建KNN推理索引
在此步骤中,托管在Amazon SageMaker当中、且经过预先训练的Resnet50模型将从每幅图像中提取2048个特征向量。每个向量都被存储在Amazon ES域的KNN索引当中。在本用例中,我们将使用来自FEIDEGGER的图像——FEIDEGGER是一套Zalando研究数据集,其中包含8732张高分辨率时尚图像。以下截屏所示,为KNN索引的创建工作流程。

整个流程包含以下操作步骤:
- 用户与Amazon SageMaker noteoobk实例上的Jupyter notebook进行交互。
- 从Keras处下载经过预先训练的Resnet50深层神经网络,删除最后一个分类器层,并对新的模型工件进行序列化,而后存储在Amazon Simple Storage Service (Amazon S3)当中。该模型负责在Amazon SageMaker实时端点上启动TensorFlow Serving API。
- 将时尚图像推送至端点,端点通过神经网络运行图像以提取其中的特征(或称嵌入)。
- Notebook代码将图像嵌入写入至Amazon ES域中的KNN索引。
通过查询图像进行视觉搜索
在此步骤中,我们提供来自应用程序的查询图像,该图像通过Amazon SageMaker托管模型进行传递,并在期间提取2048项特征。您可以使用这些特征来查询Amazon ES中的KNN索引。Amazon ES的KNN将帮助您在向量空间中搜索各点,并根据欧几里德距离或余弦相似度(默认值为欧几里德距离)找到这些点的“最近邻”。在找到给定图像的最近邻向量(例如k=3最近邻)时,它会将与之关联的Amazon S3图像返回至应用程序。下图所示,为视觉搜索全栈应用程序的基本架构。

整个流程包含以下操作步骤:
- 终端用户通过自己的浏览器或移动设备访问Web应用程序。
- 用户上传的图像以base64编码字符串的形式被发送至Amazon API Gateway 与 AWS Lambda,并在Lambda函数中重新编码为字节形式。
- 在该函数中,公开可读的图像URL以字符串形式传递,并可下载为字节形式。
- 各字节作为载荷被发送至Amazon SageMaker实时端点,而后由模型返回图像嵌入的向量。
- 该函数将搜索查询中的图像嵌入向量传递至Amazon ES域内索引中的k近邻,而后返回一份包含k相似图像及其对应Amazon S3 URI的列表。
- 该函数生成经过预签名的Amazon S3 URL并返回至客户端Web应用程序,此URL用于在浏览器中显示相似图像。
相关AWS服务
要构建这样一款端到端应用程序,大家需要使用以下AWS服务:
- AWS Amplify – AWS Amplify 是一套面向前端与移动开发人员的JavaScript库,用于构建云应用程序。关于更多详细信息,请参阅GitHub repo。
- Amazon API Gateway – 一项全托管服务,用于以任意规模创建、发布、维护、监控以及保护API。
- AWS CloudFormation – AWS CloudFormation 为开发人员及企业提供一种简便易行的方法,借此创建各AWS与相关第三方资源的集合,并以有序且可预测的方式进行配置。
- Amazon ES – 一项托管服务,能够帮助用户以任意规模轻松部署、运营以及扩展Elasticsearch集群。
- AWS IAM – AWS身份与访问管理(AWS Identity and Access Management,简称IAM) 帮助用户安全地管理指向各AWS服务与资源的访问操作。
- AWS Lambda – 一套事件驱动型、无服务器计算平台,可运行代码以响应事件,并自动管理代码所需的各项计算资源。
- Amazon SageMaker – 一套全托管端到端机器学习平台,用于以任意规模构建、训练、调优以及部署机器学习模型。
- AWS SAM– AWS Serverless Application Model (AWS SAM)是一套开源框架,用于构建无服务器应用程序。
- Amazon S3 – 一项对象存储服务,可提供具备极高持久性、可用性、成本极低且可无限扩展的数据存储基础设施。
先决条件
在本次演练中,您需要准备一个具有适当IAM权限的AWS账户,用于启动CloudFormation模板。
部署您的解决方案
在解决方案的部署方面,我们需要使用CloudFormation栈。请准备栈创建所涉及的一切必要资源,具体包括:
- 一个Amazon SageMaker notebook实例,用于在Jupyter notebook中运行Python代码。
- 一个与该notebook实例相关联的IAM角色。
- 一个Amazon ES域,用于将图像嵌入向量存储在KNN索引内并进行检索。
- 两个S3存储桶:其一用于存储源时尚图像,其二用于托管静态网站。
在Jupyter notebook中,我们还需要部署以下几项:
- Amazon SageMaker端点,用于实时获取图像特征向量与嵌入。
- 一套AWS SAM模板,用于通过API Gateway与Lambda建立一套无服务器后端。
- 一个托管在S3存储桶上的静态前端网站,用于呈现端到端机器学习应用程序的使用界面。前端代码使用ReactJS与Amplify JavaScript库。
首先,请完成以下操作步骤:
- 使用您的IAM用户名与密码登录至Amazon管理控制台。
- 选择Launch Stack并在新选项卡中将其打开:

- 在Quick create stack 页面中,勾选复选框以确认创建IAM资源。
- 选择Create stack。

- 等待栈执行完成。

大家可以在Events选项卡中的栈创建进度中查看各种事件。栈创建完成之后,您将看到状态转为CREATE_COMPLETE。
在CloudFormation模板创建完成后,您可以在Resources选项卡中看到所有资源。
- 在Outputs选项卡中,选择SageMakerNotebookURL值。
此超链接将在您的Amazon SageMaker notebook实例上打开Jupyter notebook,供您用于完成选项卡中的其余部分。

这时,您应该已经处于Jupyter notebook的登录页面中。
- 选择visual-image-search.ipynb。


在Amazon ES上构建KNN索引
在此步骤中,我们应该在notebook开头的Visual image search标题位置。遵循notebook中的步骤并按次序运行各单元。
这里,我们使用托管在Amazon SageMaker端点上的预训练Resnet50模型生成图像特征向量(嵌入)。嵌入将被保存在CloudFormation栈所创建的Amazon ES域中。关于更多详细信息,请参阅notebook中的markdown单元。
找到notebook当中的 Deploying a full-stack visual search application单元。
该notebook中包含多个重要单元。
要加载预训练ResNet50模型,同时剔除最终CNN分类器层,请使用以下代码(此模型仅作为图像特征提取器使用):
我们将模型另存为TensorFlow SavedModel格式,其中包含完整的TensorFlow程序,包括权重与计算。详见以下代码:
将模型工件(model.tar.gz)上传至Amazon S3,具体代码如下:
您可以使用Amazon SageMaker Python SDK将模型部署至基于Amazon SageMaker TensorFlow Serving的服务器当中。此服务器负责提供TensorFlow Serving REST API中的一套超集,详见以下代码:
使用以下代码从Amazon SageMaker端点处提取参考图像特征:
使用以下代码定义Amazon ES KNN索引映射:
使用以下代码将图像特征向量与关联的Amazon S3图像URI导入至Amazon ES KNN索引:
构建一款全栈视觉搜索应用程序
现在,我们已经拥有了一个能够正常工作的Amazon SageMaker端点,并可以在Amazon ES上提取图像特征与KNN索引,接下来应该构建一款实际可用的全栈ML支持型Web应用程序了。我们使用AWS SAM模板通过API Gateway与Lambda部署无服务器REST API。该REST API负责接收新图像、生成嵌入,并将得到的相似图像返回至客户端。接下来,我们将与新REST API交互的前端网站上传至Amazon S3。前端代码使用Amplify与我们的REST API相集成。
- 在以下单元中,预填充一套CloudFormation模板。此模板负责为全栈应用程序创建API Gateway与Lambda等必要资源:
以下截屏所示,为预生成的CloudFormation模板链接。
- 选择该链接。
这时我们会跳转至 Quick create stack页面。
- 选择复选框以确认创建IAM资源、各IAM资源自定义名称以及
CAPABILITY_AUTO_EXPAND。 - 选择Create stack。


栈创建完成之后,我们会看到状态转为CREATE_COMPLETE。您可以在Resources选项卡中查看CloudFormation模板创建完成的全部资源。
- 在栈创建完成之后,继续按后续单元执行。
以下单元显示,我们的全栈应用程序(包括前端与后端代码)已经成功部署:
以下截屏所示,为URL的输出结果。
- 选择该链接。
这时我们将跳转至应用程序页面,并可以在这里上传服饰图像服饰URL链接,借此获取相似服饰推荐。
- 在完成对视觉搜索应用程序的测试与试验之后,请运行notebook下方的最后两个单元:
这些单元会终止您的Amazon SageMaker端点并清空S3存储桶,为资源清理步骤做好准备。
资源清理
要删除其余AWS资源,请转至AWS CloudFormation控制台并删除其中的vis-search-api 与 vis-search栈。
总结
在本文中,我们介绍了如何使用Amazon SageMaker与Amazon ES KNN索引创建基于机器学习的视觉搜索应用程序。我们还使用到在ImageNet数据集上经过预训练的ResNet50模型。当然,大家也可以使用其他预训练模型,例如VGG、Inception以及MobileNet等,并使用自己的数据集进行调优。
对于大部分深度学习类用例,我们建议您使用GPU实例。在GPU实例上训练新模型,将带来远超CPU实例的训练速度。如果您拥有多个GPU实例,或者需要在多个GPU实例之间使用分布式训练,则可以进行次线性扩展。本用例中仅使用CPU实例,因此您可以在AWS Free Tier中通过免费资源完成演练。
关于本文所使用代码示例的更多详细信息,请参阅GitHub repo。关于Amazon ES的更多详细信息,请参考以下扩展资源: