亚马逊AWS官方博客
借助 Lambda,结合使用 DynamoDB 和 Amazon Elasticsearch | AWS 初创公司博客
客座文章作者:Michael Garski,Fender Digital 平台工程总监

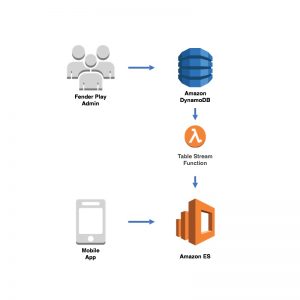
在 Fender Digital,我们于 2016 年年中开始使用 Lambda,并在 2017 年 1 月全面为所有新服务采用了这种语言。在迁移到 Lambda 的同时,我们也希望停止使用 RDBMS,除非我们确实需要关系型数据存储,而事实也证明,我们的大多数用例并非必须使用关系型数据存储。DynamoDB 采用基于用量的成本模式,是数据存储的理想之选;但它的不足之处在于不支持全文查询。Amazon Elasticsearch 提供了我们需要的搜索功能,但此前我们并不习惯在主要数据存储中使用这种语言。由于这两种选项都不能满足我们的需求,因此我们的工程团队提出了一种方法,该方法同时使用 DynamoDB 和 Elasticsearch,通过使用由 DynamoDB Stream 事件在表上调用的 Lambda 函数使集群保持最新状态。通过这种方式,我们可以根据流事件中的数据确定何时需要在集群中添加、删除或更新项目。
DynamoDB 和 AWS Elasticsearch 服务的这种组合非常适合我们的 Fender Play 课程内容,能够很好地支持包含教学内容的曲目的全文查询。在 Fender Play 管理员创建课程内容时,会将其写入 DynamoDB,使用新项目触发流事件,而新项目会将其插入到 Elasticsearch 集群之中,允许用户查询他们所查找的课程内容。
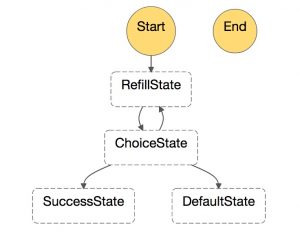
 我们不使用 Elasticsearch 作为主要数据存储的原因在于,除了集群快照以外,我们没有来自事实来源的灾难恢复解决方案。我们使用 Elasticsearch 的每项基于 Lambda 的服务都有一个 Lambda 函数,可以通过执行 DynamoDB 表扫描来重新填充索引。对于大型表,重新填充操作必然会超过 Lambda 调用的五分钟时间限制,因此我们使用 AWS Step Functions 执行重新填充过程。调用 Step Function 时,它会调用以一个空白 JSON 文档作为输入的重新填充函数。在调用过程中,重新填充函数内的扫描进程会跟踪时间,在扫描停止的四分钟后,任何剩余的项目都会刷入集群之中,扫描中最后一个评估的关键字会返回给状态机。状态机进入选择状态,并在这种状态下检查重新填充函数的返回值。如果返回值包含最后一个评估的关键字,则状态机使用最后一个评估的关键字调用重新填充函数,以便从上次停止的位置处继续扫描。这样,只要最后一个评估的关键字返回到状态机,系统就会继续调用重新填充函数。在重新填充函数完成扫描时,它会将一个空白的 JSON 文档返回到状态机,表示集群重新填充完成。
我们不使用 Elasticsearch 作为主要数据存储的原因在于,除了集群快照以外,我们没有来自事实来源的灾难恢复解决方案。我们使用 Elasticsearch 的每项基于 Lambda 的服务都有一个 Lambda 函数,可以通过执行 DynamoDB 表扫描来重新填充索引。对于大型表,重新填充操作必然会超过 Lambda 调用的五分钟时间限制,因此我们使用 AWS Step Functions 执行重新填充过程。调用 Step Function 时,它会调用以一个空白 JSON 文档作为输入的重新填充函数。在调用过程中,重新填充函数内的扫描进程会跟踪时间,在扫描停止的四分钟后,任何剩余的项目都会刷入集群之中,扫描中最后一个评估的关键字会返回给状态机。状态机进入选择状态,并在这种状态下检查重新填充函数的返回值。如果返回值包含最后一个评估的关键字,则状态机使用最后一个评估的关键字调用重新填充函数,以便从上次停止的位置处继续扫描。这样,只要最后一个评估的关键字返回到状态机,系统就会继续调用重新填充函数。在重新填充函数完成扫描时,它会将一个空白的 JSON 文档返回到状态机,表示集群重新填充完成。
今年,随着我们继续扩展对 Lambda 的应用,我们制定了宏大的目标。我们会将基于 EC2 的服务迁移到 Lambda,在多个区域进行这样的设置,以便根据用户位置提供更迅捷的响应,并在某个区域不可用时提高应用程序的恢复能力。我们将使用 Route 53 的地理位置路由功能,根据用户所在的位置将 API 流量定向到特定区域。我们的服务将以“主动-主动”配置模式部署到多个区域,在区域之间实现近乎实时的数据复制。我们的初步计划是通过表流实现我们自己的跨区域 DynamoDB 表复制。但是,在 re:Invent 2017 大会上公布全局表之后,跨区域表同步现已成为 DynamoDB 的一项功能。我们部署应用程序的每个区域都有自己的 DynamoDB 表和 Elasticsearch 集群,在表中的项目发生修改时,表流会调用 Lambda 函数,让集群与表保持同步。通过这种方式,我们就能确保所有区域中的 Elasticsearch 集群几乎实时地保持更新,这样即便某个受支持的区域发生服务中断,用户体验也丝毫不会受到影响。
本篇作者