亚马逊AWS官方博客
开发者指南:当 Amazon EFS 遇上 Amazon ECS 与 AWS Fargate——第一部分
Original URL: https://amazonaws-china.com/cn/blogs/containers/developers-guide-to-using-amazon-efs-with-amazon-ecs-and-aws-fargate-part-1/
最近,我们在Amazon Elastic Container Service(ECS)与Amazon Elastic File System(EFS)之间刚刚实现了原生集成。Amazon ECS是一项全托管形式的容器编排服务,专门针对云环境所打造,且能够与其他AWS服务集成。ECS支持用户在Amazon EC2与AWS Fargate之上部署容器(打包在各「任务」当中)。Amazon EFS则是一套全托管型弹性共享文件系统,可供其他AWS服务(例如ECS或EC2实例)使用。Amazon EFS能够以透明方式实现文件系统的扩展、数据的复制以及跨可用区可用性,同时支持多个存储层,能够轻松满足大多数工作负载提出的实际需求。
这种集成能力适用于所有使用EC2实例或者Fargate的 ECS 客户。最近,我们通过Fargate的1.4版本全面启用了这项集成功能。
在开始本文之前,需要强调几点:此集成是面向特定编排工具的,因为这是 Amazon ECS 任务级别的配置,适用于 EC2 上的 ECS 或 Fargate 上的 ECS。Amazon EKS在EFS上采用的是完全不同的集成机制。对于EC2上的EKS,大家可以参考EKS说明文档中的相关说明链接。对于Fargate上的EKS,您可以参考本GitHub路线图条目,因为截至本文撰写之时,这项集成功能仍在开发当中。
如果您不太熟悉ECS、EC2以及Fargate之间的关系,我们建议您首先阅读本篇博文,明确完成本次演练所需要的基础知识。
我们相信这种集成能力将给客户带来巨大的价值与深远影响。为了充分帮助大家掌握集成相关知识,我们撰写了三篇系列博文,全面涵盖集成体系中的各个角度。对于希望探索这一领域并实现集成的ECS客户们来说,这三篇文章将通过理论与范围、技术、操作方法示例三个部分引导大家完成学习:
- 第一部分:(本文)概述对EFS支持的需求、集成机制的技术基础与范围,以及能够由此实现的客户用例。
- 第二部分:深入探讨EFS安全机制如何在基于ECS及Fargate的容器部署中起效,同时涉及在各区域中部署ECS及EFS时需要遵循的最佳实践以及高级注意事项。
- 第三部分:展示如何在使用EFS的ECS任务上部署容器化应用程序的一个示例,包括其中的可重用代码及命令。
我们闲言少叙,马上进入第一部分。
容器理念之争:无状态和有状态
目前,业界对于容器技术的有状态与无状态选择问题仍然存在诸多争议。首先澄清一点,所有容器都天然为无状态形式,container storage(容器存储)在历史上一直被认为是临时的,且始终仅与容器自身的生命周期相关。这有点像是EC2实例存储的运作方式——“状态”必须始终被存储在容器之外。因此,支持无状态容器的阵营呼吁使用完全解耦的外部服务来存储容器的状态与数据。各项服务之间的通信,则通过典型的服务到服务模式中的API调用操作来实现。具体来讲,我们可以在容器当中调用Amazon S3、Amazon DynamoDB以及Amazon Aurora等各类服务。
但是,情况正在起变化。在容器运行时当中管理存储时,我们已经迎来一系列坚实的技术进步,超越原始的临时容器存储也不再只是梦想。如今,我们可以使用volume storage(卷存储)中的有状态存储概念。这是一种紧密耦合的架构,其中容器与存储之间的通信不是以服务到服务形式存在,而通过通用存储协议直接实现。例如,我们可以挂载并附加与容器生命周期相分离的网络存储卷。ECS与EFS之间的集成,引入了可用于容器的全托管弹性文件系统。这套文件系统可被视为一种“无服务器存储”方案,使容器可以用一种更加云原生的方式保存各类状态。
需要明确的是,有状态容器与访问外部服务的需求之间并非相互排斥的关系。换句话说,我们既可以使用有状态容器,也可以继续使用服务到服务模式实现对外部服务的调用。
出于便捷性需求、架构或者其他传统原因的考虑,我们的容器可能需要保证本地持久性(通过卷存储实现)。例如,假定我们拥有一款遗留的独立Web应用程序,其配置参数需要被保存在名为/data/server.json的文件当中。我们可以将EFS与ECS集成起来满足上述需求,提供跨可用区的数据强一致性,从而轻松、透明地实现多可用区部署。
但是,有些有状态容器可能需要与外部服务通信。例如,如果我们想要建立一个可扩展且具备高可用性的WordPress网站。那么在该站点中,运行WordPress的容器必须能够在各横向扩展出来的WordPress容器之间实现持久Web内容的轻松共享(可以通过卷存储机制实现),并保证各容器有权访问后端Aurora数据库。
现在,我们可以使用核心架构模式(其中包含一整套简便的有状态容器创建方法)满足所有实际需求。在本系列博文中,我们将重点介绍如何使用Amazon EFS作为卷存储实现方案;但请注意,大家也可以使用其他方案(例如EC2实例存储或者EC2 EBS)为容器提供卷存储资源。
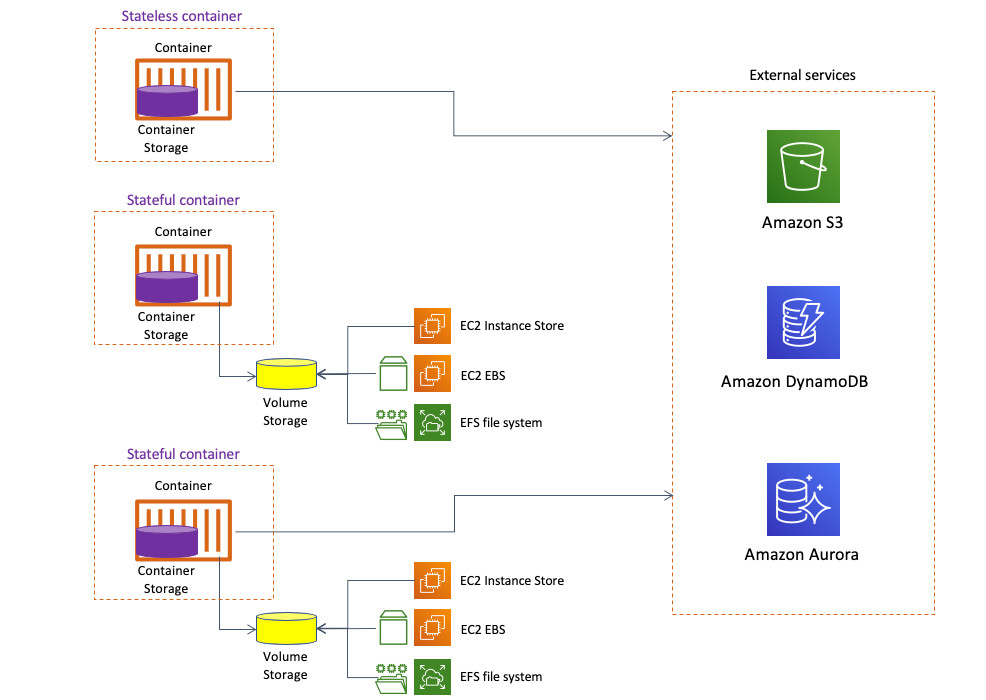
当然,最终解决方案的性能、冗余性、可用性以及灵活性级别也将由您所选择的卷存储实现方案所决定。例如:
- 使用由EC2实例提供的存储卷,会将容器与该EC2实例绑定起来。
- 使用EC2 EBS磁盘提供的存储卷,会将容器与特定可用区绑定起来。
- 如果使用EFS文件系统提供的存储卷,我们可以实现容器的跨可用区运行。
有趣的是,这些关于有状态与无状态的讨论绝非新生事物,各类模式也早有雏形。十多年以来,我们一直在观察讨论的方向与模式变化。在AWS于2006年刚刚推出EC2时,其还仅仅支持临时存储机制。后来根据客户的反馈与实际需求,我们增加了EBS支持选项,从而解锁了众多单靠本地临时存储根本无法实现的用例。
另外,客户需求是反映一个特定功能是否有用的指标,对于本博文中谈到的功能,我们已经在公共路线图上对相关功能请求做出上千项回应,尽可能满足用户给出的合理反馈意见。
集成选项的意义
在接下来的讨论当中,所涉及的全部内容都假定相关应用程序需要配合持久存储机制。无论其是否需要按照服务到服务模式与其他后端服务进行通信,持久存储都将作为一项默认前提。
在引入持久存储功能之前,客户可以选择在支持ECS任务运行的同一虚拟机之内使用本地文件系统(即container storage,容器存储)。本地文件系统对于运行在EC2或Fargate上的ECS任务都适用。这种设置方式的局限在于,任务所使用的文件系统将与对应的EC2实例或运行 Fargate fleet的专用虚拟机相绑定。这也意味着客户存储的数据将与其当时使用的基础设施相绑定。如果该EC2实例被迫停止并需要在另一EC2实例上重新启动任务,则相关数据将随之消失。同样的,如果Fargate任务经历停止与重新启动,数据也不再可用:

为了在计算结构(EC2或Fargate)与存储之间实现更强大的灵活性与独立性,部分客户会在配置当中将计算平台与外部存储映射起来,保证任务使用的为外部存储资源。如此一来,他们就能够将任务与存储进行解耦,借此实现更高的灵活性(通过volume storage实现)。我们在另一篇文章中提供示例,说明如何配置基础架构以实现这一目标。此外,文中还包含其他示例,介绍如何将EFS用作ECS任务的外部存储服务。
以上提到的方案都能够在计算与存储之间实现资源独立性,但却都称不上最佳实践,具体原因有以下两点:
- 它们只适用于配合EC2启动类型的ECS,而无法与Fargate正常协作。上述方案要求我们通过配置数据平面以执行某些操作(例如在实例层级安装驱动程序并挂载外部存储等)。在使用Fargate时,由于无法访问底层基础设施,因此无法完成这些操作。
- 这些机制会导致客户承担众多繁重且无业务意义的基础设施配置工作。要让各ECS任务以透明方式使用经过解耦的存储机制,需要完成多项配置操作。虽然难度在可接受的范围,但却无法带来任何直接业务价值。
下图所示,为AWS推出ECS与EFS集成选项之前,基础架构的简单表示:

而在集成功能上线之后,EC2与AWS Fargate的使用体验都将得到显著简化。
解决方案
在深入探讨集成本身及其实现的更多细节之前,我们首先需要对这项功能的作用范围进行定义。通过集成,我们现在可以在ECS任务当中挂载EFS文件系统端点。ECS任务可运行在EC2实例或者Fargate之上,具体取决于您选择使用的启动类型。无论选择哪种方式,我们的ECS on EC2任务或者ECS on Fargate任务都能够以透明方式原生映射至EFS文件系统端点,这就大大减少了基础设施的配置负担。关于更多细节,我们将稍后具体讨论。
假设EFS文件系统已经存在,那么用户无需额外对基础设施层级(EC2或Fargate)进行配置。新的集成功能只需要在任务定义中使用EFSVolumeConfiguration指令,即可直接将ECS任务与Amazon EFS匹配起来。
下图所示,为这种集成方式的简单表示:
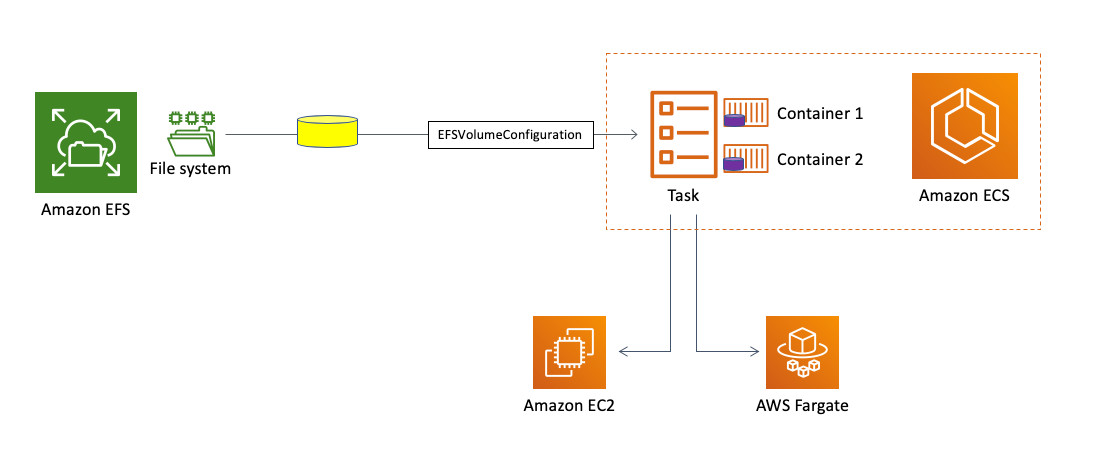
ECS说明文档中的相关教程将指导大家了解集成功能的具体工作方式。其中阐述了如何创建EFS存储卷,并使用上述的EFSVolumeConfiguration指令将其与各ECS任务映射起来。
将Amazon ECS与Amazon EFS相集成,所能实现的全新用例
根据客户的反馈,集成功能的实现帮助他们实现了诸多以往只能设想、却难以落地的实际用例。集成功能对于Fargate的意义更为重大,一举解决了其无法映射至外部存储卷的天然局限。由此衍生的用例主要分为两大类:
- 有状态任务,负责运行那些要求文件系统持久性的工作负载。
- 多项任务同时访问同一共享文件系统以进行并行计算的用例。
有状态任务,负责运行那些要求文件系统持久性的工作负载
容器可以说是运行横向扩展型轻量化无状态工作负载的理想工具。但在另一方面,客户有时也希望在Fargate上运行一组工作负载,并通过某种方式实现存储持久性。另有不少客户希望能够在迁移至Fargate的应用程序上实现长期持久存储。
考虑到这一点,假设我们需要支持这样一款已有的独立应用程序,其需要将配置文件保存在/server/config.json,以及保存少量数据到 /data目录当中。这款应用程序甚至可能无法支持任何集群类技术,且要求在单一实例重新启动之后,继续依靠保存在原始位置的/server/config.json以及/data等目录实现继续运行。
在下面描述的场景当中,运行该应用程序的Fargate任务会将相关数据(/server/config.json以及/data)存储在Amazon EFS之上。假设此任务将作为ECS服务的一部分运行,如果该任务由于某些意外原因而停止,则ECS将重新启动该任务(可能在其他可用区内重启),并重新连接至同一远程文件系统。最后,应用程序在新的位置上继续处理业务请求:

客户提出的一项现实要求,是希望让应用程序访问文件系统上的某组数据,而该文件系统又无需始终开启。我们可以设想这样一款应用程序,其每周只需要运行两次,专门负责处理网络上共享的数据。在我们发布的这项集成之前,只能选择一直不间断的运行Fargate任务,保证所有数据都驻留在临时容器存储当中——但这将带来巨大的风险,一旦应用程序发生故障并触发任务重启,所有本地数据都将丢失。而且从成本角度来看,为这样一项仅在30%的时段内处理数据的任务承担长期运行费用,也显然不符合运营原则。使用ECS与EFS的集成,我们可以将数据与任务生命周期进行解耦,从而降低数据丢失风险并优化运营成本。
多项任务同时访问同一共享文件系统以进行并行计算的用例
集成功能带来的另一种有趣用例,是为运行在EC2实例或Fargate上的大量ECS任务建立起统一的共享文件系统,借此实现并发访问。相关教程中的示例以Web服务器农场的角度介绍了这一用例(其中需要交付的HTML内容被集中起来,并以只读方式挂载在各任务中)。整个结构与创建高可用性、可扩展WordPress前端的设置方式类似。但我们不妨设想其他高级场景,例如在S3上托管有一套大型数据集,而各项任务则需要根据数据集内容进行操作并采取行动。机器学习训练与推理用例就是其中的典型代表,非常适合这种共享文件系统模式。在我们发布这项集成之前,各项任务都需要从S3中拉取数据,并将对应数据保存在任务中本地的可用临时存储中(如果可行)。现在,通过这项集成,我们可以让任意一个任务从 S3 上拉取数据并放置在EFS之上,以供其他所有任务随时访问。已经有不少用户对这类用例表示赞赏与期待。
下图所示,为整个流程的简单表示形式:
总结
本文为系列博文中的第一篇。到这里,我们已经讨论了此次集成功能的诉求、适用范围与用例。现在,大家可以转向第二部分,下一篇文章将深入探讨Amazon EFS的工作方式,以及我们要如何以EFS、ECS以及Fargate为基础构建起具有区域弹性的部署体系。