亚马逊AWS官方博客
Cynamics 如何使用 AWS 构建大规模、近乎实时的流式传输 AI 推理系统
Cynamics 面临的问题
在此过程的早期阶段,随着客户群的增长,我们需要通过我们独特的 AI 算法无缝地支持规模和网络吞吐量的增长。我们面临着几个不同的挑战:
- 我们如何对流式传输到 AI 推理系统的客户传入数据进行近实时分析,以便预测威胁和攻击?
- 我们如何才能无缝地自动扩展我们的解决方案,使其具有成本效益,同时又不影响平台摄入速度?
- 由于我们的许多客户来自公共部门,我们如何在同时支持 AWS 商业和政府环境(GovCloud)的同时做到这一点?
这篇文章展示了我们如何使用 AWS 托管服务(尤其是 Amazon Kinesis Data Streams 和 Amazon EMR)来构建一个近乎实时的流式传输 AI 推理系统,为 AWS 商业和政府环境中的数百个生产客户提供服务。同时实现无缝弹性伸缩。
解决方案概览
下图展示了我们解决方案的架构:

为了提供一种成本高效、高度可用的解决方案,可以随着用户增长而轻松扩展,同时又不影响近乎实时的性能,我们选择了 Amazon EMR。
目前,我们每天处理超过 5000 万条记录,换算成 50 多亿的流量,并且每天还在不断增长。将 Amazon EMR 与 Kinesis Data Streams 结合使用,提供了我们所需的可扩展性,从而只需短短几秒钟就实现了推理。
尽管这项技术对我们来说是新技术,但我们通过查看 AWS 提供的有关扩展、分区和资源管理的最佳实践指南,更大限度地缩短了我们的学习时间。
工作流
我们的工作流包含以下步骤:
- 客户的网络设备将流量样本直接发送到 Cynamics 云。网络流(或连接)是一组具有相同五元组 ID 的数据包:
源 IP 地址、目标 IP 地址、源端口、目标端口和协议。 - 通过 Network Load Balancers 分析这些样本,然后将它们转发到采用 Graviton 的 Amazon Elastic Compute Cloud(Amazon EC2)实例上运行的无状态流量转换器的 Auto Scaling 组。在流量转换器中使用 Graviton 处理器,我们可以将运营成本降低 30% 以上。
- 这些流转换为 Cynamics 数据格式,并加入来自 Cynamics 数据库和内部来源的附加信息,例如 IP 分辨率、情报和声誉。
下图显示了单台流量转换器在一周内的网络规模。第一张图显示了单台流量转换器的传入网络数据包。
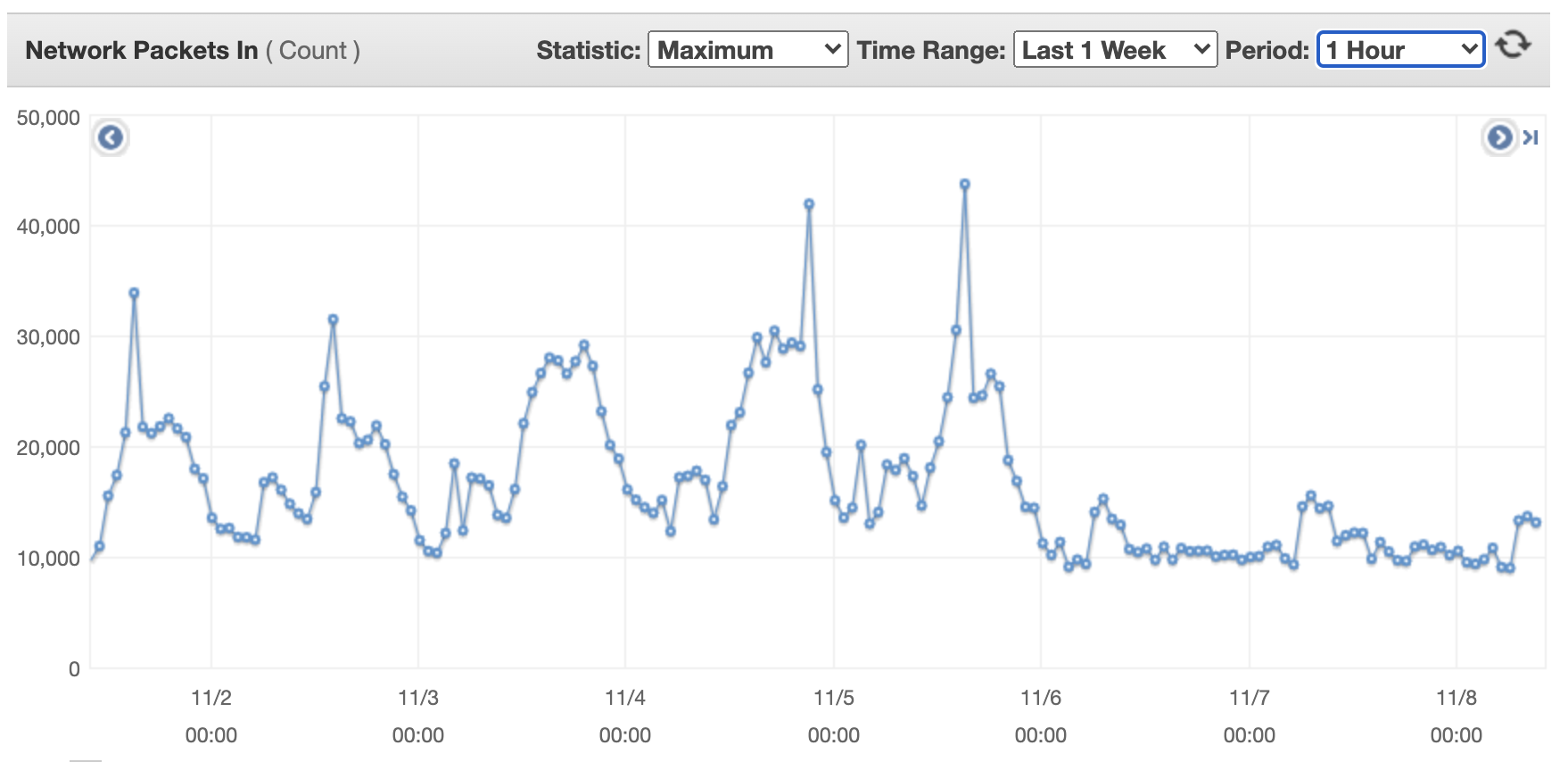
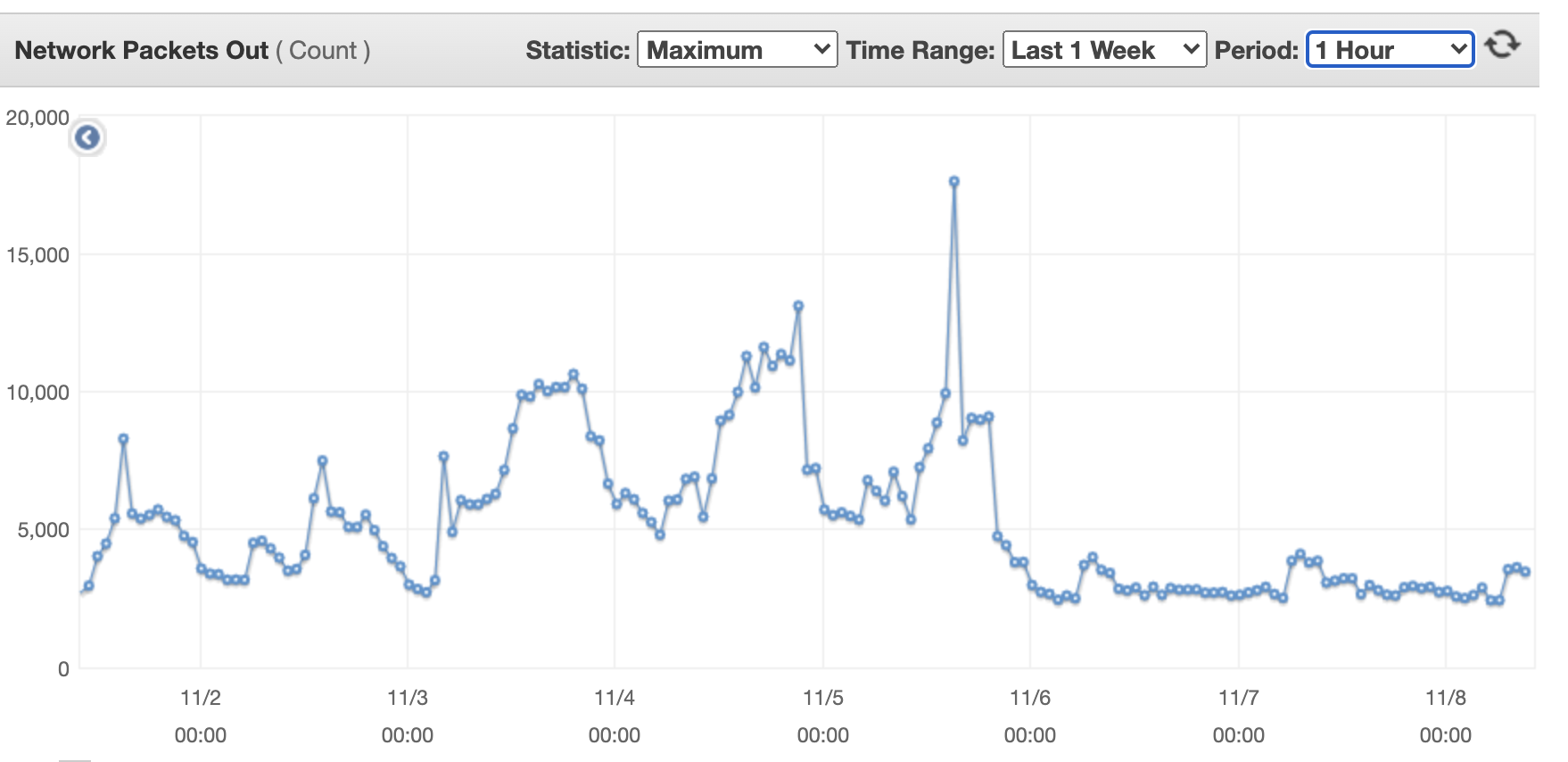
下图显示了单台流量转换器的传出网络数据包。
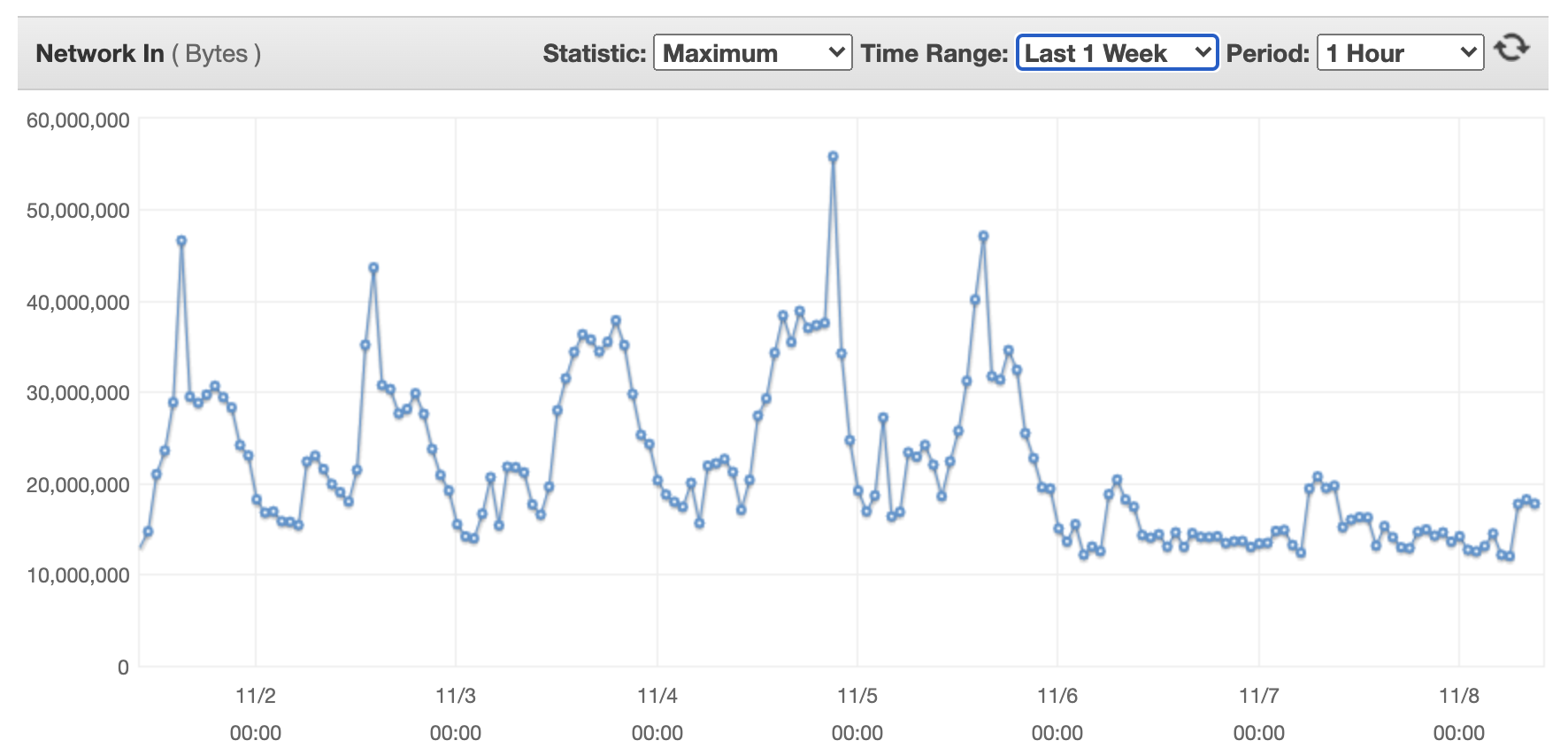
下图显示了单台流量转换器的传入网络字节。
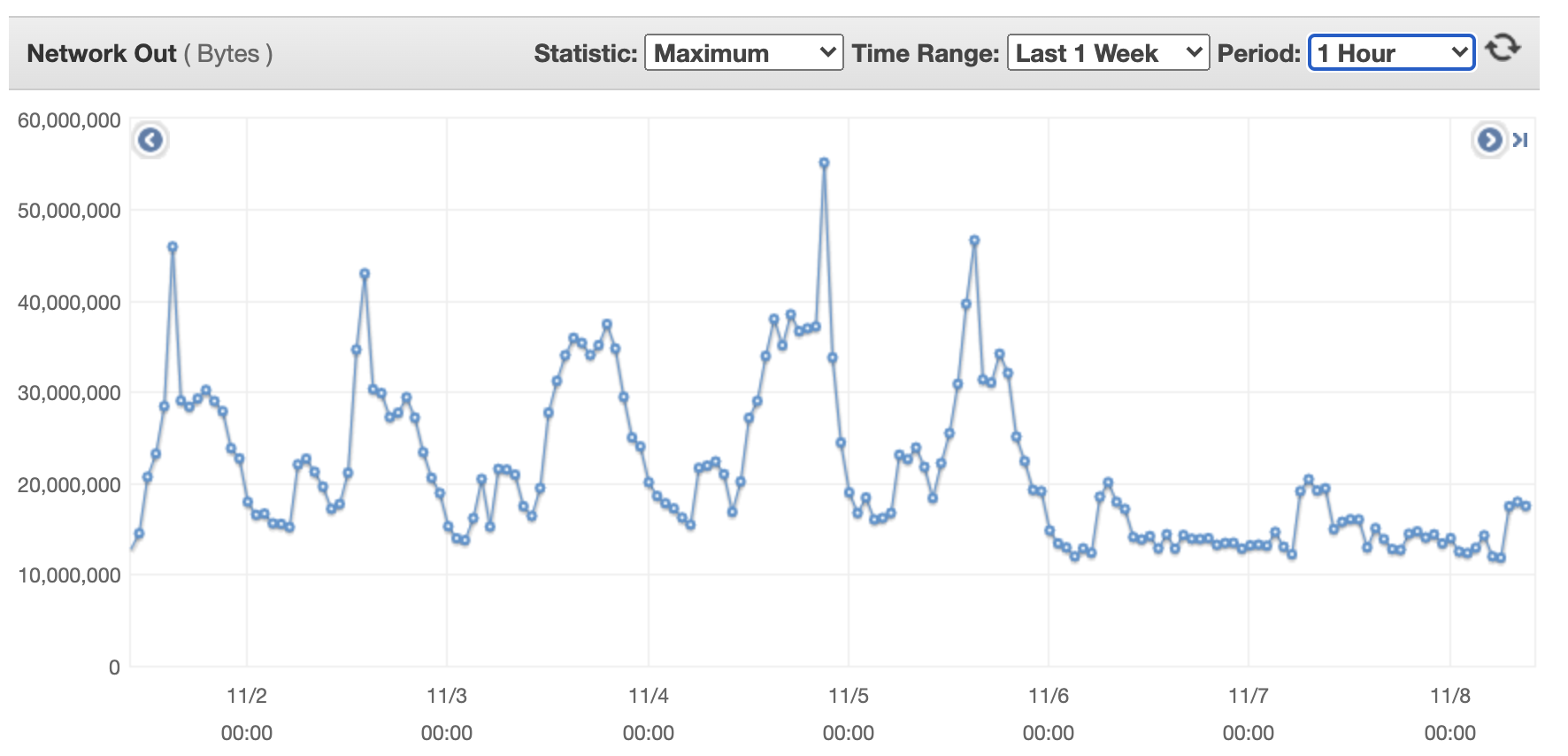
下图显示了单台流量转换器的传出网络字节。
- 使用 Kinesis Data Streams 将这些流发送到实时分析引擎。
- 基于 Amazon EMR 的实时引擎使用 Yarn/Spark 在几秒钟内批量消耗记录。每个客户端的采样速率根据其吞吐量动态调整,以确保所有客户端的传入数据速率都是固定的。我们使用带有自定义策略的 Amazon EMR 托管式扩缩实现了这一目标(适用于 Amazon EMR 5.30.1 及更高版本),该策略让我们可以根据 Amazon CloudWatch 指标扩展或缩减 EMR 节点,并使用两种不同的扩展和缩减规则。我们创建的指标基于 Amazon EMR 运行时间,因为我们的实时 AI 威胁检测以几秒钟的滑动窗口间隔运行。
- 扩展策略会跟踪 10 分钟内的平均运行时间,如果超过所需时间间隔的 95%,则扩展 EMR 节点。这使我们能够防止处理延迟。
- 同样,缩减策略使用相同的指标,但衡量 30 分钟内的平均值,并相应地扩缩集群。这使我们能够优化集群成本并减少非工作时间的 EMR 节点数量。
- 为了优化和无缝扩展我们的 AI 推理调用,这些调用通过 ALB 和另一个 Auto Scaling 服务器组(AI 模型服务)提供。
- 我们将 Amazon DynamoDB 用作快速且高度可用的状态表。
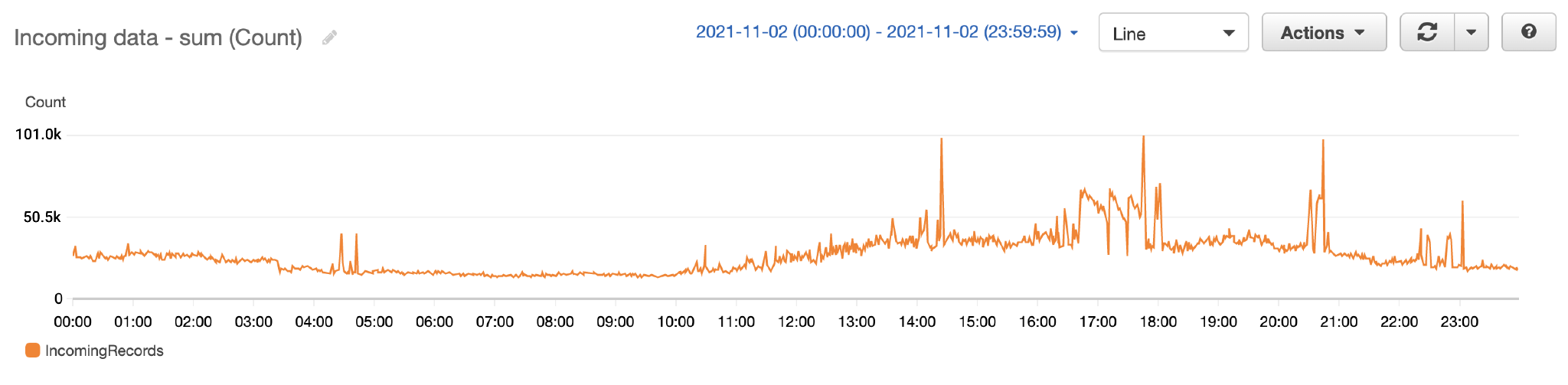
下图显示了 Kinesis 数据流在一天内处理的记录数。

下图显示了 Kinesis 数据流每分钟的记录速率。
AI 预测和威胁检测会发送到持续处理和警报中,并保存在 Amazon DocumentDB(与 MongoDB 兼容)中。
结论
通过本文中描述的方法,Cynamics 一直以无缝且可自动扩展的方式为不断增长的客户群提供基于其独特 AI 算法的近实时分析,从而实现威胁预测。自首次实施该解决方案以来,我们设法轻松和线性地扩展我们的架构,并通过在流量转换器中过渡到基于 Graviton 的处理器来进一步优化我们的成本,从而降低了 30% 以上的流量转换器成本。
我们正在考虑以下后续步骤:
-
- 使用 Amazon SageMaker Studio 管道的自动机器学习生命周期,包括以下步骤:
- 发运预先训练的 AI 模型。
- 使用 Amazon SageMaker 端点而不是现有的 AI 模型服务进行推断
- 在 Amazon SageMaker Debugger 中监控整个流。
- 通过将 EMR 实例也移至基于 Graviton 的实例来进一步降低成本,这样应该能额外缩减 20% 的成本
- 使用 Amazon SageMaker Studio 管道的自动机器学习生命周期,包括以下步骤: