多年来,数据仓库以及在数据仓库平台上执行的分析的重要性在稳步提升,许多企业开始依赖这些系统,完成短期运营决策和长期战略规划等关键业务任务。传统上,数据仓库按照批处理周期刷新,例如每月、每周或每天,以便企业从中获得各种洞察。
许多企业都意识到,近实时的数据摄取与高级分析相结合开辟了新的机遇。例如,金融机构可以通过在近实时模式而非批处理模式下运行异常检测程序,用于预测信用卡交易是否存在欺诈。
在这篇文章中,我们展示了 Amazon Redshift 如何通过一个平台来提供串流摄取和机器学习(ML)预测。
Amazon Redshift 是一个快速、可扩展、安全的完全托管式云数据仓库,使用标准 SQL 提供对所有数据简化且经济高效的分析。
利用 Amazon Redshift ML,数据分析师和数据库开发人员能够在 Amazon Redshift 数据仓库中,使用熟悉的 SQL 命令轻松地创建、训练和应用机器学习模型。
我们非常高兴地推出了适用于 Amazon Kinesis Data Streams 的 Amazon Redshift Streaming Ingestion 以及 Amazon Managed Streaming for Apache Kafka(Amazon MSK),您可以利用这些服务直接从 Kinesis 数据流或 Kafka 主题摄取数据,而无需在 Amazon Simple Storage Service(Amazon S3)中暂存数据。Amazon Redshift Streaming Ingestion 可在将数百 MB 的数据摄取到数据仓库时,实现秒级别的低延迟。
这篇文章演示如何使用 Amazon Redshift Streaming Ingestion 和 Redshift ML 功能以及您熟悉的 SQL 语言,构建近实时的机器学习预测。
解决方案概览
按照本文中概述的步骤操作,您将能够在 Amazon Elastic Compute Cloud(Amazon EC2)实例上设置产生器流式应用程序,该应用程序模拟信用卡交易并将数据实时推送到 Kinesis Data Streams。您在 Amazon Redshift 上设置 Amazon Redshift Streaming Ingestion 实体化视图,在其中接收流数据。您可以训练和构建 Redshift ML 模型,根据流数据生成实时推理。
下图展示了架构和处理流。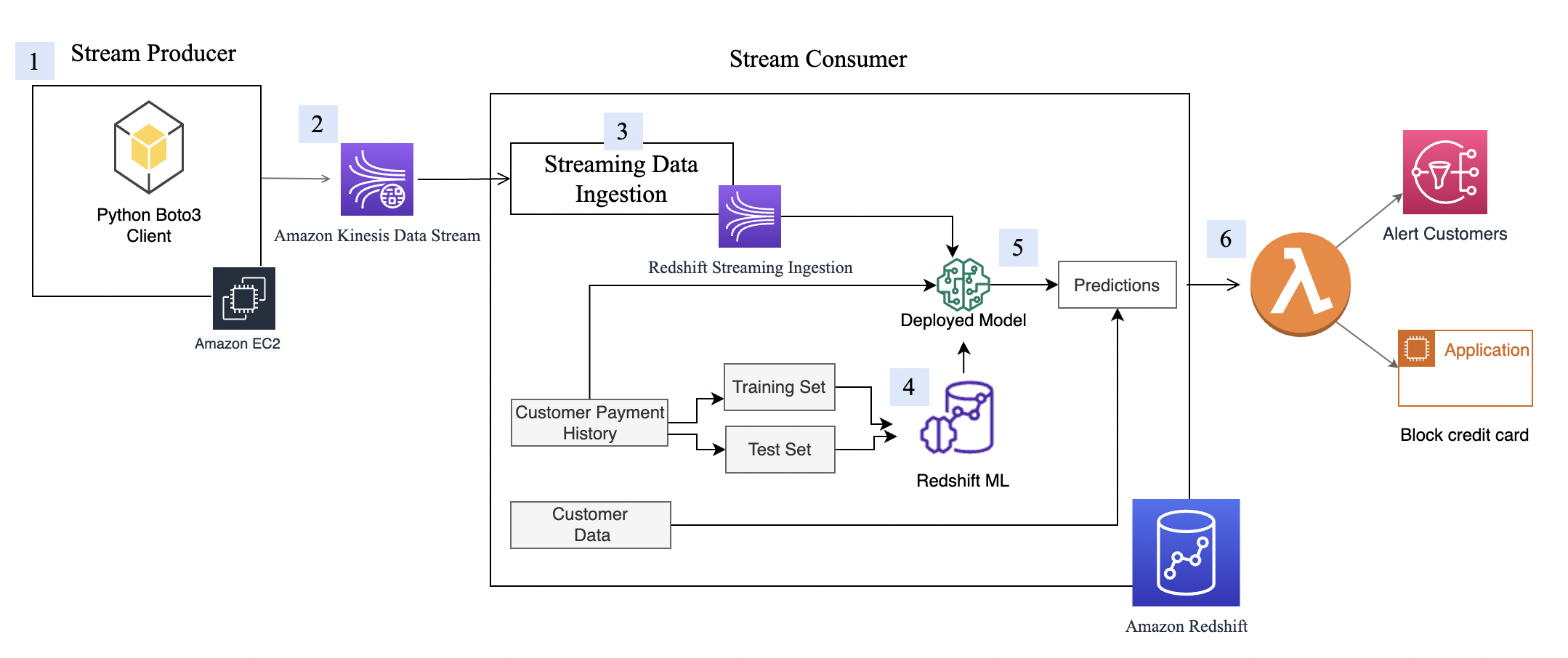
分步过程如下所示:
- EC2 实例模拟信用卡交易应用程序,该应用程序将信用卡交易插入到 Kinesis 数据流中。
- 数据流存储传入的信用卡交易数据。
- Amazon Redshift Streaming Ingestion 实体化视图在数据流之上创建,可自动将流数据摄取到 Amazon Redshift 中。
- 您可以使用 Redshift ML 构建、训练和部署机器学习模型。Redshift ML 模型的训练使用历史事务数据训练进行。
- 您可以转换流数据并生成机器学习预测。
- 您可以提醒客户或更新应用程序以防范风险。
本演练使用信用卡交易流数据。信用卡交易数据是虚构的,是使用模拟器生成的。客户数据集也是虚构的,使用一些随机数据函数生成。
先决条件
- 创建一个 Amazon Redshift 集群
- 将集群配置为使用 Redshift ML。
- 创建 AWS Identity and Access Management(IAM)用户。
- 更新附加到 Redshift 集群的 IAM 角色,使其包含访问 Kinesis 数据流的权限。有关所需策略的更多信息,请参阅开始使用串流摄取。
- 创建 m5.4xlarge EC2 实例。我们使用 m5.4xlarge 实例测试了产生器应用程序,不过您也可以随意使用其他实例类型。创建实例时,使用 amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 AMI。
- 要确保 Python3 安装在 EC2 实例中,请运行以下命令来验证您的 Python 版本(请注意,数据提取脚本仅适用于 Python 3):
- 安装以下依赖项软件包来运行模拟器程序:
sudo yum install python3-pip
pip3 install numpy
pip3 install pandas
pip3 install matplotlib
pip3 install seaborn
pip3 install boto3
- 使用变量配置 Amazon EC2,例如为以上步骤 3 中创建的 IAM 用户生成的 AWS 凭证。以下屏幕截图显示了使用 aws configure 的示例。
设置 Kinesis Data Streams
Amazon Kinesis Data Streams 是一种可大规模扩展且持久的实时数据流服务。它可以持续从数十万个来源每秒捕获 GB 级数据,例如网站点击流、数据库事件流、金融交易、社交媒体源、IT 日志和位置跟踪事件。收集的数据可在数毫秒内提供,用于实现实时分析使用场景,例如实时控制面板、实时异常检测、动态定价等。我们之所以使用 Kinesis Data Streams,是因为它是一种无服务器解决方案,可以根据使用情况进行扩展。
创建 Kinesis 数据流
首先,您需要创建 Kinesis 数据流来接收流数据:
- 在 Amazon Kinesis 控制台的导航窗格中,选择 Data streams(数据流)。
- 选择 Create data stream(创建数据流)。
- 对于 Data stream name(数据流名称),输入
cust-payment-txn-stream。
- 对于 Capacity mode(容量模式),选择 On-demand(按需)。

- 对于其余选项,请选择默认选项并按照提示完成设置。
- 捕获所创建数据流的 ARN,以便在下一部分中定义 IAM policy 时使用。

设置权限
要使流应用程序写入 Kinesis Data Streams,应用程序需要有 Kinesis 的访问权限。您可以使用以下策略语句,向您在下一部分中设置的模拟器进程授予数据流的访问权限。使用您在上一步中保存的数据流的 ARN。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt123",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:PutRecord",
"kinesis:PutRecords",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards",
"kinesis:DescribeStreamSummary"
],
"Resource": [
"arn:aws:kinesis:us-west-2:xxxxxxxxxxxx:stream/cust-payment-txn-stream"
]
}
]
}
配置流产生器
在使用 Amazon Redshift 中的流数据之前,我们需要一个将数据写入 Kinesis 数据流的流数据来源。这篇文章使用自定义的数据生成器和适用于 Python 的 AWS SDK(Boto3),将数据发布到数据流。有关设置说明,请参阅 Producer Simulator(产生器模拟器)。此模拟器进程将流数据发布到在上一步中创建的数据流(cust-payment-txn-stream)。
配置流使用器
此部分讨论配置流使用器(Amazon Redshift Streaming Ingestion 视图)的相关内容。
Amazon Redshift Streaming Ingestion 将来自 Kinesis Data Streams 的流数据,低延迟、高速地摄取到 Amazon Redshift 实体化视图中。您可以将您的 Amazon Redshift 集群配置为启用串流摄取,并使用 SQL 语句创建具有自动刷新的实体化视图,如在 Amazon Redshift 中创建实体化视图中所述。自动实体化视图刷新进程以每秒数百 MB 数据的速度,将流数据从 Kinesis Data Streams 摄取到 Amazon Redshift 中。这实现了对快速刷新的外部数据的高速访问。
创建实体化视图后,您可以使用 SQL 访问数据流中的数据,并通过直接在数据流之上创建实体化视图来简化数据管道。
完成以下步骤以配置 Amazon Redshift 流实体化视图:
- 在 IAM 控制台上,在左侧导航窗格中选择 Policies(策略)。
- 选择 Create policy(创建策略)。
- 创建一个名为
KinesisStreamPolicy 的新 IAM policy。 有关流策略的定义,请参阅开始使用串流摄取。
- 在导航窗格中,选择 Roles(角色)。
- 选择 Create Role(创建角色)。
- 选择 AWS Service(AWS 服务),然后选择 Redshift and Redshift customizable(Redshift 和 Redshift 可定制设置)。
- 创建一个名为
redshift-streaming-role 的新角色并附加策略 KinesisStreamPolicy。
- 创建外部架构以映射到 Kinesis Data Streams:
CREATE EXTERNAL SCHEMA custpaytxn
FROM KINESIS IAM_ROLE 'arn:aws:iam::386xxxxxxxxx:role/redshift-streaming-role';
现在,您可以创建实体化视图来使用流数据。您可以使用 SUPER 数据类型,以 JSON 格式按原样存储负载,也可以使用 Amazon Redshift JSON 函数将 JSON 数据解析为单个列。在这篇文章中,我们使用第二种方法,因为已经明确定义了架构。
- 创建串流摄取实体化视图
cust_payment_tx_stream。通过在以下代码中指定 AUTO REFRESH YES,您可以启用串流摄取视图的自动刷新,从而避免构建数据管道来节省时间:
CREATE MATERIALIZED VIEW cust_payment_tx_stream
AUTO REFRESH YES
AS
SELECT approximate_arrival_timestamp ,
partition_key,
shard_id,
sequence_number,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'TRANSACTION_ID')::bigint as TRANSACTION_ID,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'TX_DATETIME')::character(50) as TX_DATETIME,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'CUSTOMER_ID')::int as CUSTOMER_ID,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'TERMINAL_ID')::int as TERMINAL_ID,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'TX_AMOUNT')::decimal(18,2) as TX_AMOUNT,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'TX_TIME_SECONDS')::int as TX_TIME_SECONDS,
json_extract_path_text(from_varbyte(kinesis_data, 'utf-8'),'TX_TIME_DAYS')::int as TX_TIME_DAYS
FROM custpaytxn."cust-payment-txn-stream"
Where is_utf8(kinesis_data) AND can_json_parse(kinesis_data);
请注意,json_extract_path_text 的长度限制为 64 KB。此外,from_varbye 会筛选大于 65KB 的记录。
- 刷新数据。
Amazon Redshift 会自动刷新 Amazon Redshift 流实体化视图。这样您就不必担心数据过时。通过实体化视图自动刷新,当流中有数据可用时,数据会自动加载到 Amazon Redshift 中。如果您选择手动执行此操作,请使用以下命令:
REFRESH MATERIALIZED VIEW cust_payment_tx_stream ;
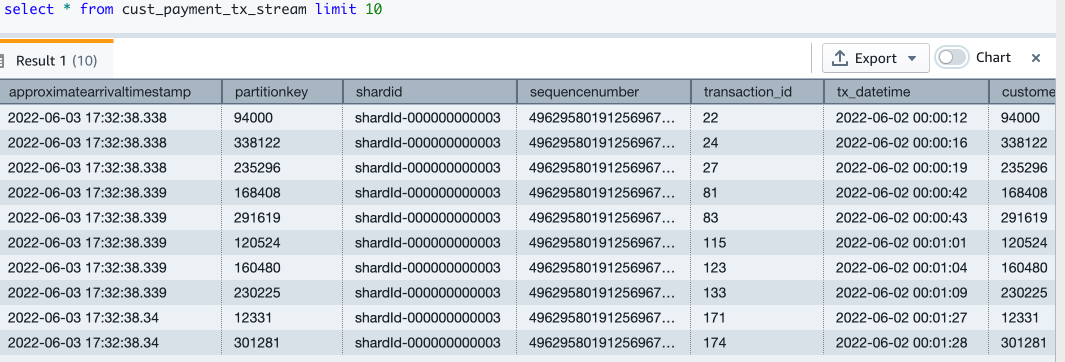
- 现在我们来查询流实体化视图以查看示例数据:
Select * from cust_payment_tx_stream limit 10;
- 我们来看看现在流视图中有多少条记录:
Select count(*) as stream_rec_count from cust_payment_tx_stream;

现在您已完成 Amazon Redshift Streaming Ingestion 视图的设置,该视图会随着传入的信用卡交易数据不断更新。在我的环境中,运行 select count 查询后,可以看到将大约 67000 条记录提取到流视图中。您的数字可能会有所不同。
Redshift ML
使用 Redshift ML,您可以引入预先训练的机器学习模型,也可自行构建一个。有关更多信息,请参阅在 Amazon Redshift 中使用机器学习。
在这篇文章中,我们使用历史数据集训练和构建机器学习模型。数据包含一个 tx_fraud 字段,用于标记历史交易是否为欺诈。我们使用 Redshift Auto ML 构建有监督机器学习模型,该模型从此数据集中学习,并在传入交易流经预测函数运行时进行预测。
在以下部分中,我们将演示如何设置历史数据集和客户数据。
加载历史数据集
历史表的字段比流数据来源的字段多。这些字段包含客户的最近支出和终端风险评分,例如通过转换流数据计算的欺诈交易数量。还有一些类别变量,例如周末交易或夜间交易。
要加载历史数据,请使用 Amazon Redshift 查询编辑器运行命令。
使用以下代码创建交易历史记录表。DDL 也可以在 GitHub 上找到。
CREATE TABLE cust_payment_tx_history
(
TRANSACTION_ID integer,
TX_DATETIME timestamp,
CUSTOMER_ID integer,
TERMINAL_ID integer,
TX_AMOUNT decimal(9,2),
TX_TIME_SECONDS integer,
TX_TIME_DAYS integer,
TX_FRAUD integer,
TX_FRAUD_SCENARIO integer,
TX_DURING_WEEKEND integer,
TX_DURING_NIGHT integer,
CUSTOMER_ID_NB_TX_1DAY_WINDOW decimal(9,2),
CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW decimal(9,2),
CUSTOMER_ID_NB_TX_7DAY_WINDOW decimal(9,2),
CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW decimal(9,2),
CUSTOMER_ID_NB_TX_30DAY_WINDOW decimal(9,2),
CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW decimal(9,2),
TERMINAL_ID_NB_TX_1DAY_WINDOW decimal(9,2),
TERMINAL_ID_RISK_1DAY_WINDOW decimal(9,2),
TERMINAL_ID_NB_TX_7DAY_WINDOW decimal(9,2),
TERMINAL_ID_RISK_7DAY_WINDOW decimal(9,2),
TERMINAL_ID_NB_TX_30DAY_WINDOW decimal(9,2),
TERMINAL_ID_RISK_30DAY_WINDOW decimal(9,2)
);
Copy cust_payment_tx_history
FROM 's3://redshift-demos/redshiftml-reinvent/2022/ant312/credit-card-transactions/credit_card_transactions_transformed_balanced.csv'
iam_role default
ignoreheader 1
csv ;
我们来看看加载了多少笔交易:
select count(1) from cust_payment_tx_history;
查看每月欺诈和非欺诈交易趋势:
SELECT to_char(tx_datetime, 'YYYYMM') as YearMonth,
sum(case when tx_fraud=1 then 1 else 0 end) as fraud_tx,
sum(case when tx_fraud=0 then 1 else 0 end) as non_fraud_tx,
count(*) as total_tx
FROM cust_payment_tx_history
GROUP BY YearMonth;
创建和加载客户数据
现在,我们创建客户表并加载数据,数据中包含了客户的电子邮件和电话号码。以下代码创建表、加载数据并对表进行采样。表 DDL 可在 GitHub 上找到。
CREATE TABLE public."customer_info"(customer_id bigint NOT NULL encode az64,
job_title character varying(500) encode lzo,
email_address character varying(100) encode lzo,
full_name character varying(200) encode lzo,
phone_number character varying(20) encode lzo,
city varchar(50),
state varchar(50)
);
COPY customer_info
FROM 's3://redshift-demos/redshiftml-reinvent/2022/ant312/customer-data/Customer_Data.csv'
IGNOREHEADER 1
IAM_ROLE default CSV;
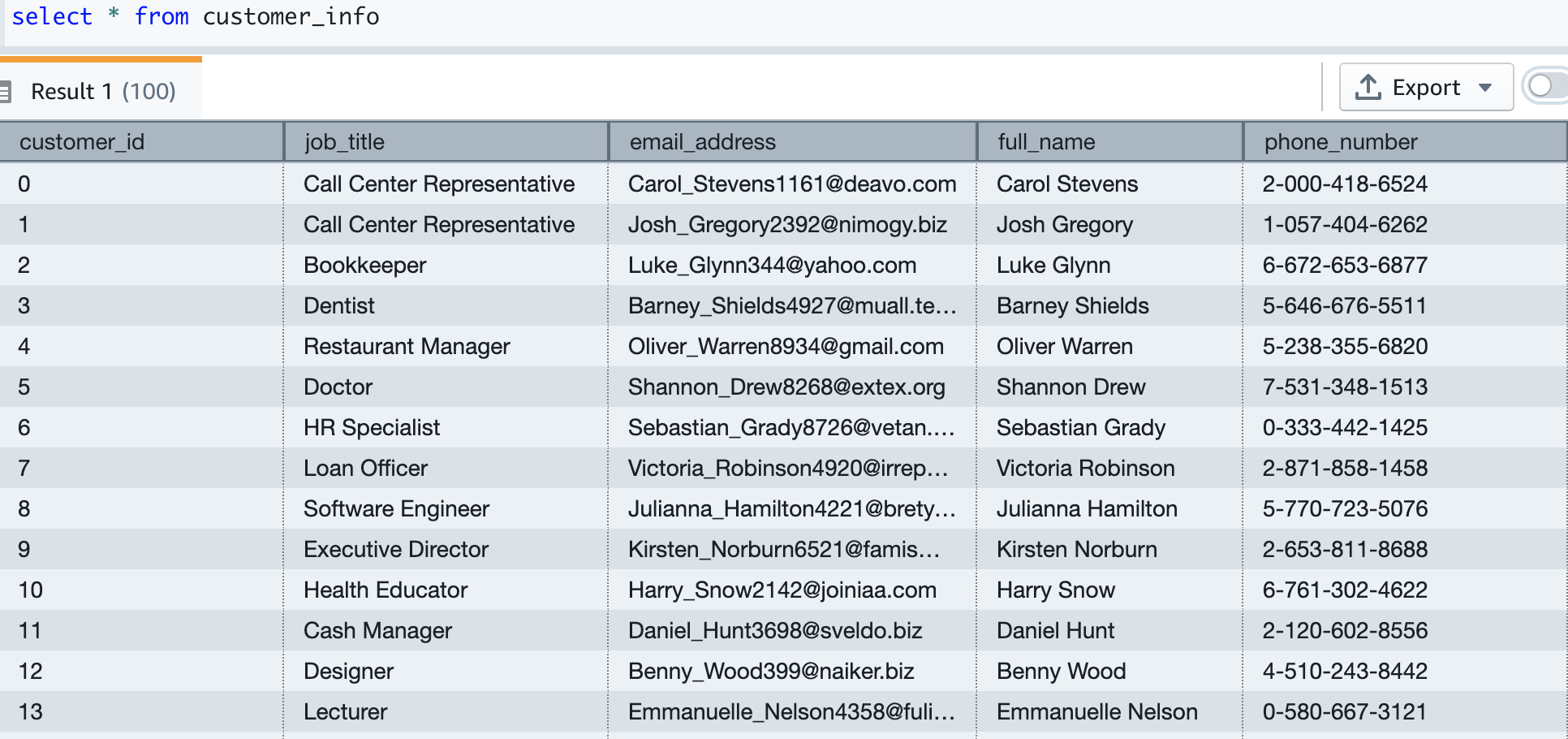
Select count(1) from customer_info;
我们的测试数据有大约 5000 名客户。以下屏幕截图显示了示例客户数据。
构建机器学习模型
我们的历史信用卡交易表有 6 个月的数据,我们现在使用这些数据来训练和测试机器学习模型。
模型获取以下字段作为输入:
TX_DURING_WEEKEND ,
TX_AMOUNT,
TX_DURING_NIGHT ,
CUSTOMER_ID_NB_TX_1DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW ,
CUSTOMER_ID_NB_TX_7DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW ,
CUSTOMER_ID_NB_TX_30DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW ,
TERMINAL_ID_NB_TX_1DAY_WINDOW ,
TERMINAL_ID_RISK_1DAY_WINDOW ,
TERMINAL_ID_NB_TX_7DAY_WINDOW ,
TERMINAL_ID_RISK_7DAY_WINDOW ,
TERMINAL_ID_NB_TX_30DAY_WINDOW ,
TERMINAL_ID_RISK_30DAY_WINDOW
我们得到 tx_fraud 作为输出。
我们将这些数据拆分为训练数据集和测试数据集。从 2022-04-01 到 2022-07-31 的交易作为训练数据集。从 2022-08-01 到 2022-09-30 的交易作为测试数据集。
我们使用熟悉的 SQL CREATE MODEL 语句创建机器学习模型。使用 Redshift ML 命令的基本形式。以下方法使用 Amazon SageMaker Autopilot,它会自动为您执行数据准备、特征工程、模型选择以及训练。提供包含代码的 S3 存储桶的名称。
CREATE MODEL cust_cc_txn_fd
FROM (
SELECT TX_AMOUNT ,
TX_FRAUD ,
TX_DURING_WEEKEND ,
TX_DURING_NIGHT ,
CUSTOMER_ID_NB_TX_1DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW ,
CUSTOMER_ID_NB_TX_7DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW ,
CUSTOMER_ID_NB_TX_30DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW ,
TERMINAL_ID_NB_TX_1DAY_WINDOW ,
TERMINAL_ID_RISK_1DAY_WINDOW ,
TERMINAL_ID_NB_TX_7DAY_WINDOW ,
TERMINAL_ID_RISK_7DAY_WINDOW ,
TERMINAL_ID_NB_TX_30DAY_WINDOW ,
TERMINAL_ID_RISK_30DAY_WINDOW
FROM cust_payment_tx_history
WHERE cast(tx_datetime as date) between '2022-06-01' and '2022-09-30'
) TARGET tx_fraud
FUNCTION fn_customer_cc_fd
IAM_ROLE default
SETTINGS (
S3_BUCKET '<replace this with your s3 bucket name>',
s3_garbage_collect off,
max_runtime 3600
);
我将机器学习模型命名为 Cust_cc_txn_fd,将预测函数命名为 fn_customer_cc_fd。FROM 子句显示历史表 public.cust_payment_tx_history 中的输入列。目标参数设置为 tx_fraud,这是我们尝试预测的目标变量。IAM_Role 设置为默认值,因为集群配置了此角色;否则,您必须提供自己的 Amazon Redshift 集群 IAM 角色 ARN。我将 max_runtime 设置为 3600 秒,这是供 SageMaker 完成处理的时间。Redshift ML 部署在此时间范围内确定的最佳模型。
根据模型的复杂性和数据量,模型可能需要一些时间才能使用。如果您发现模型选择未完成,请增加 max_runtime 的值。您可以将最大值设置为 9999。
CREATE MODEL 命令异步运行,这意味着它在后台运行。您可以使用 SHOW MODEL 命令查看模型的状态。当状态显示为 Ready(就绪)时,这意味着模型已经完成训练和部署。
show model cust_cc_txn_fd;
以下屏幕截图显示了我们的输出。
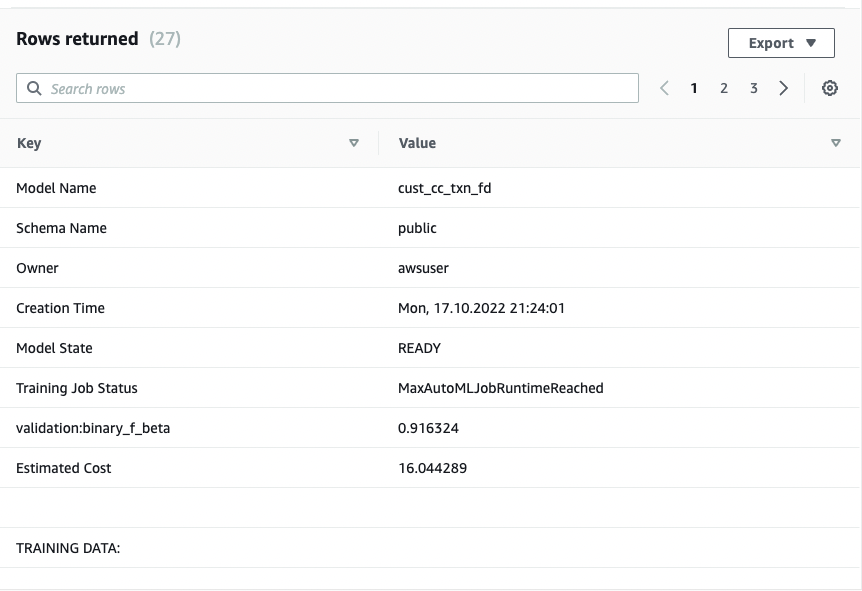
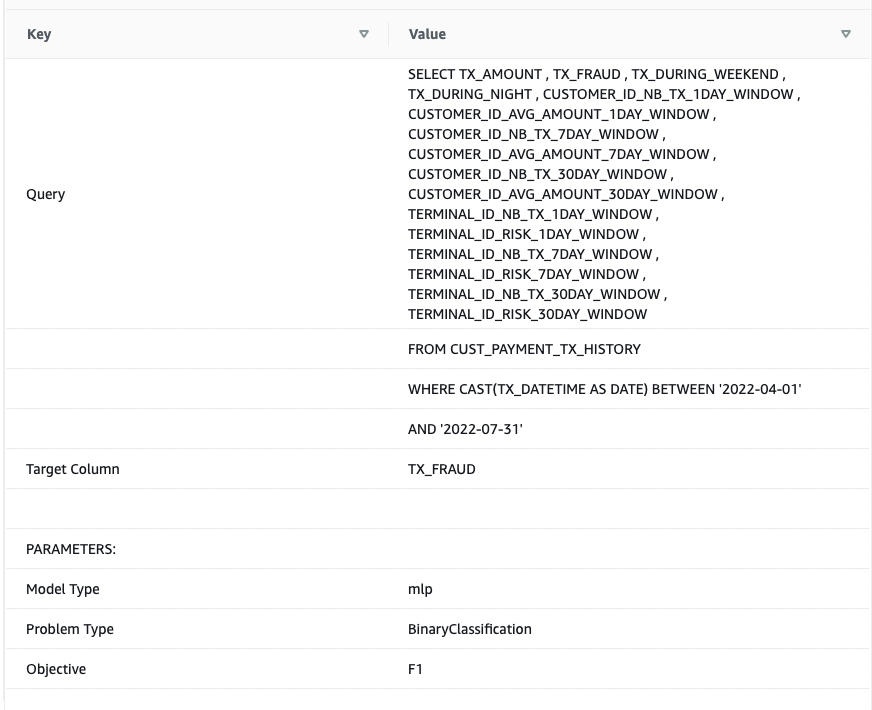
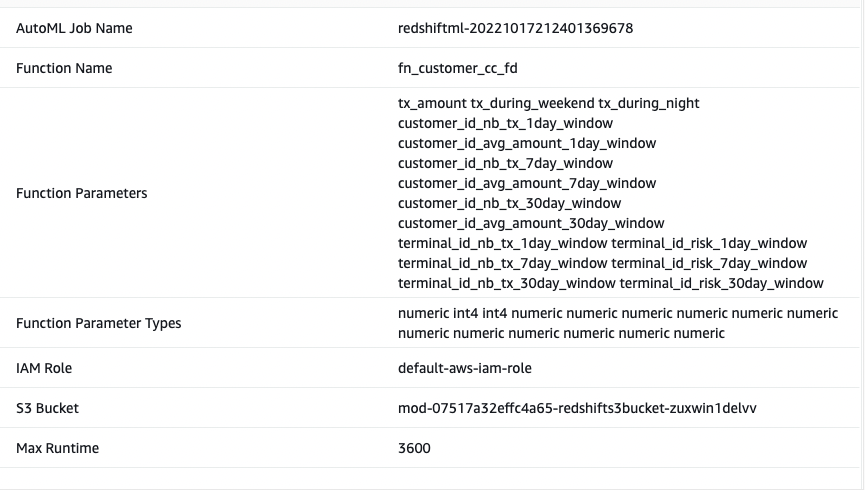
从输出中,我看到模型已被正确识别为 BinaryClassification,且 F1 被选为目标。F1 分数是同时考虑精度和召回的指标。它返回介于 1(完美精度和召回)和 0(最低评分)之间的值。在这个例子中是 0.91。该值越高,模型性能越好。
我们使用测试数据集来测试这个模型。运行以下命令检索示例预测:
SELECT
tx_fraud ,
fn_customer_cc_fd(
TX_AMOUNT ,
TX_DURING_WEEKEND ,
TX_DURING_NIGHT ,
CUSTOMER_ID_NB_TX_1DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW ,
CUSTOMER_ID_NB_TX_7DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW ,
CUSTOMER_ID_NB_TX_30DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW ,
TERMINAL_ID_NB_TX_1DAY_WINDOW ,
TERMINAL_ID_RISK_1DAY_WINDOW ,
TERMINAL_ID_NB_TX_7DAY_WINDOW ,
TERMINAL_ID_RISK_7DAY_WINDOW ,
TERMINAL_ID_NB_TX_30DAY_WINDOW ,
TERMINAL_ID_RISK_30DAY_WINDOW )
FROM cust_payment_tx_history
WHERE cast(tx_datetime as date) >= '2022-10-01'
limit 10 ;
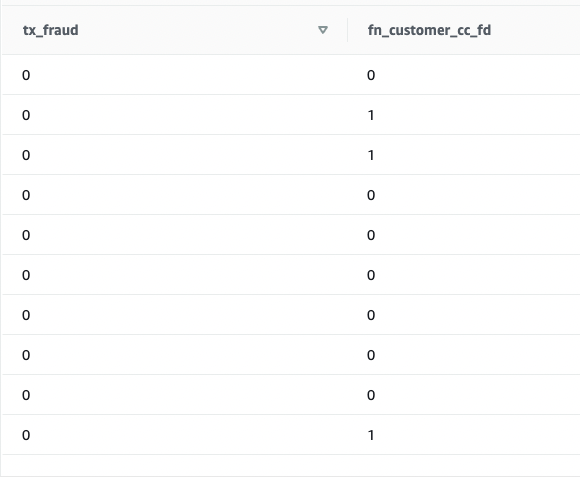
我们看到有些值匹配,有些值不匹配。我们可以将预测与事实进行比较:
SELECT
tx_fraud ,
fn_customer_cc_fd(
TX_AMOUNT ,
TX_DURING_WEEKEND ,
TX_DURING_NIGHT ,
CUSTOMER_ID_NB_TX_1DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW ,
CUSTOMER_ID_NB_TX_7DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW ,
CUSTOMER_ID_NB_TX_30DAY_WINDOW ,
CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW ,
TERMINAL_ID_NB_TX_1DAY_WINDOW ,
TERMINAL_ID_RISK_1DAY_WINDOW ,
TERMINAL_ID_NB_TX_7DAY_WINDOW ,
TERMINAL_ID_RISK_7DAY_WINDOW ,
TERMINAL_ID_NB_TX_30DAY_WINDOW ,
TERMINAL_ID_RISK_30DAY_WINDOW
) as prediction, count(*) as values
FROM public.cust_payment_tx_history
WHERE cast(tx_datetime as date) >= '2022-08-01'
Group by 1,2 ;
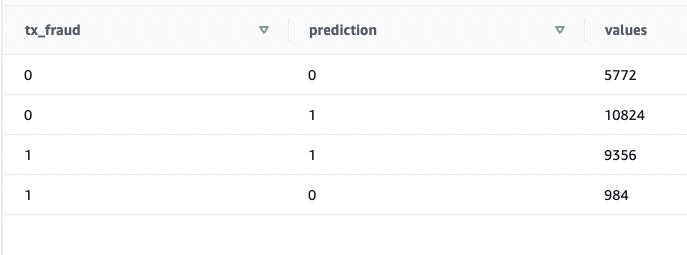
我们验证了该模型运行正常,F1 分数良好。我们继续对流数据生成预测。
预测欺诈交易
Redshift ML 模型已准备就绪,我们可以使用它对流数据摄取进行预测。历史数据集包含的字段比我们流数据来源中的字段多,但它们只是与欺诈交易的客户和终端风险相关的近期性和频率指标。
通过在视图中嵌入 SQL,我们可以非常轻松地对流数据应用转换。创建第一个视图,该视图在客户级别汇总流数据。然后创建第二个视图,该视图在终端级别汇总流数据,第三个视图则将传入的交易数据与客户和终端汇总数据相结合,并在一个地方调用预测函数。第三个视图的代码如下所示:
CREATE VIEW public.cust_payment_tx_fraud_predictions
as
select a.approximate_arrival_timestamp,
d.full_name , d.email_address, d.phone_number,
a.TRANSACTION_ID, a.TX_DATETIME, a.CUSTOMER_ID, a.TERMINAL_ID,
a.TX_AMOUNT ,
a.TX_TIME_SECONDS ,
a.TX_TIME_DAYS ,
public.fn_customer_cc_fd(a.TX_AMOUNT ,
a.TX_DURING_WEEKEND,
a.TX_DURING_NIGHT,
c.CUSTOMER_ID_NB_TX_1DAY_WINDOW ,
c.CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW ,
c.CUSTOMER_ID_NB_TX_7DAY_WINDOW ,
c.CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW ,
c.CUSTOMER_ID_NB_TX_30DAY_WINDOW ,
c.CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW ,
t.TERMINAL_ID_NB_TX_1DAY_WINDOW ,
t.TERMINAL_ID_RISK_1DAY_WINDOW ,
t.TERMINAL_ID_NB_TX_7DAY_WINDOW ,
t.TERMINAL_ID_RISK_7DAY_WINDOW ,
t.TERMINAL_ID_NB_TX_30DAY_WINDOW ,
t.TERMINAL_ID_RISK_30DAY_WINDOW ) Fraud_prediction
From
(select
Approximate_arrival_timestamp,
TRANSACTION_ID, TX_DATETIME, CUSTOMER_ID, TERMINAL_ID,
TX_AMOUNT ,
TX_TIME_SECONDS ,
TX_TIME_DAYS ,
case when extract(dow from cast(TX_DATETIME as timestamp)) in (1,7) then 1 else 0 end as TX_DURING_WEEKEND,
case when extract(hour from cast(TX_DATETIME as timestamp)) between 00 and 06 then 1 else 0 end as TX_DURING_NIGHT
FROM cust_payment_tx_stream) a
join terminal_transformations t
on a.terminal_id = t.terminal_id
join customer_transformations c
on a.customer_id = c.customer_id
join customer_info d
on a.customer_id = d.customer_id
;
Run a SELECT statement on the view:
select * from
cust_payment_tx_fraud_predictions
where Fraud_prediction = 1;
当您反复运行 SELECT 语句时,最新的信用卡交易会近实时地进行转换和机器学习预测。
这展示了 Amazon Redshift 的强大功能 – 借助易用的 SQL 命令,您可以通过应用复杂的窗口函数转换流数据,然后应用机器学习模型预测欺诈性交易,而无需构建复杂的数据管道或构建和管理其他基础设施。
扩展解决方案
由于数据流输入和机器学习预测近实时完成,因此您可以使用 Amazon Simple Notification Service(Amazon SNS)构建提醒客户的业务流程,也可以在操作系统中锁定客户的信用卡账户。
这篇文章并未详细介绍这些操作,如果您有兴趣详细了解使用 Amazon Redshift 来构建事件驱动型解决方案,请参阅以下 GitHub 存储库。
清理
为避免将来产生费用,请删除在这篇文章演练中创建的资源。
小结
在这篇文章中,我们演示了如何设置 Kinesis 数据流、配置生成器并将数据发布到流中,然后创建 Amazon Redshift Streaming Ingestion 视图并在 Amazon Redshift 中查询数据。数据进入 Amazon Redshift 集群后,我们演示了如何训练机器学习模型和构建预测函数,并将该函数应用于流数据以生成近实时预测。
关于作者
 Bhanu Pittampally 是达拉斯分公司的一名分析专家解决方案构架师。他擅长构建分析解决方案。他侧重于数据仓库领域,包括架构、开发和管理。他在数据和分析领域工作了超过 15 年。
Bhanu Pittampally 是达拉斯分公司的一名分析专家解决方案构架师。他擅长构建分析解决方案。他侧重于数据仓库领域,包括架构、开发和管理。他在数据和分析领域工作了超过 15 年。
 Praveen Kadipikonda 是 AWS 驻达拉斯的一名高级分析专家解决方案构架师。他帮助客户构建高效、高性能且可扩展的分析解决方案。他在构建数据库和数据仓库解决方案等领域工作超过了 15 年。
Praveen Kadipikonda 是 AWS 驻达拉斯的一名高级分析专家解决方案构架师。他帮助客户构建高效、高性能且可扩展的分析解决方案。他在构建数据库和数据仓库解决方案等领域工作超过了 15 年。
 Ritesh Kumar Sinha 是一位驻旧金山的分析专家解决方案架构师。他帮助客户构建可扩展的数据仓库和大数据解决方案已超过 16 年。他喜欢在 AWS 上设计和构建高效的端到端解决方案。业余时间他喜欢读书、散步和做瑜伽。
Ritesh Kumar Sinha 是一位驻旧金山的分析专家解决方案架构师。他帮助客户构建可扩展的数据仓库和大数据解决方案已超过 16 年。他喜欢在 AWS 上设计和构建高效的端到端解决方案。业余时间他喜欢读书、散步和做瑜伽。