亚马逊AWS官方博客
使用新查询编辑器查询您的 Amazon Redshift 集群
Original URL:https://aws.amazon.com/blogs/big-data/query-your-amazon-redshift-cluster-with-the-new-query-editor/
使用查询编辑器替代 SQL IDE 或工具
查询编辑器提供浏览器内的界面,用于在 Amazon Redshift 集群上运行 SQL 查询。对于在计算节点上运行的查询,您可以查看查询结果及查询旁边的查询执行计划。
能够在便捷的用户界面中可视化查询和结果使您能够以数据库管理员和数据库开发人员的身份完成多项任务。可视化查询编辑器可帮助您执行以下操作:
- 构建复杂的查询。
- 编辑和运行查询。
- 创建和编辑数据。
- 查看和导出结果。
- 生成有关查询的 EXPLAIN 计划。
使用查询编辑器,您还可以同时打开多个 SQL 选项卡。带颜色的语法、查询自动完成和单步查询格式化,这些都是它的额外好处!
数据库管理员通常会维持他们定期运行的常用 SQL 语句的存储库。如果您在记事本的某个位置编写了此存储库,则可以使用保存的查询功能。利用此功能,您可以一步保存和重新使用您常运行的 SQL 语句。这使您可以高效地查看、重新运行和修改以前运行的 SQL 语句。查询编辑器还拥有一个导出器,以便您可以将查询结果导出到 CSV 格式。
查询编辑器可使您执行常见任务,例如在集群上创建架构和表及在表中加载数据。现在,通过您在控制台上直接运行的几个简单的 SQL 语句,便可以执行这些常见任务。您还可以从控制台中执行日常管理任务。这些任务可以包括在集群中查找长时间运行的查询、检查集群中长时间运行的更新是否存在死锁,以及检查集群中有多少可用空间。
查询编辑器已在 16 个 AWS 区域推出。您可以在 Amazon Redshift 控制台上使用该编辑器,无需额外付费。您的集群使用和 Amazon Redshift Spectrum 适用 Amazon Redshift 标准费率。要了解更多信息,请参阅 Amazon Redshift 定价。
接下来,让我们开始使用查询编辑器
下面的章节介绍使用查询编辑器直接从控制台中用 Amazon S3 存储桶中的示例数据集设置 Amazon Redshift 集群的步骤。对于新用户,这是设置 JDBC/ODBC 客户端以建立与集群连接的一个特别方便的替代方法。如果您已经有集群,则可以在 10 分钟或以下完成这些步骤。
在下面的示例中,您使用查询编辑器执行这些任务:
- 将示例数据集加载到您的集群中。
- 在示例数据集上运行 SQL 查询并查看结果和执行详细信息。
- 在系统表上运行管理查询并保存经常使用的查询。
- 运行 SQL 查询以加入内部和外部表。
使用下面的步骤设置您的集群,以进行查询:
- 在 Amazon Redshift 控制台上,创建集群。要了解详细步骤,请参见 Amazon Redshift 入门指南中的启动示例 Amazon Redshift 集群中所述的程序。使用当前支持的以下任何一个节点类型:dc1.8xlarge、dc2.large、dc2.8xlarge 或 ds2.8xlarge。在此博文中,我们使用 Amazon Redshift 控制面板上的快速启动集群按钮创建单节点 dc2.large 集群,在 us-east-1 区域称为 demo-cluster。在学习本教程的过程中,将这个集群名称替换为您启动的集群的名称以及您启动该集群所在的区域。

- 为 AWS 账户添加查询编辑器的相关权限。要在控制台上访问查询编辑器功能,您需要权限。有关详细步骤,请参阅 Amazon Redshift 集群管理指南 中的启用至查询编辑器的访问权。
- 要在示例数据集上加载和运行查询(包括从 S3 中加载数据或使用 AWS Glue 或 Amazon Athena 数据目录的权限),请遵照下述步骤:
a.要使用 COPY 命令从 Amazon S3 中加载样本数据,您必须为集群提供身份验证,以便代表您访问 Amazon S3。此程序的示例数据提供在 Amazon Redshift 所拥有的 Amazon S3 存储桶中。 储 桶的权限被配置为,允许所有经过身份验证的 AWS 用户读取访问示例数据文件。要执行此步骤:
• 将 AmazonS3ReadOnlyAccess 策略附加到 IAM 角色。AmazonS3ReadOnlyAccess 策略为您的集群授予只读访问所有 Amazon S3 存储桶的权限。
• 如果您使用 AWS Glue 数据目录,将 AWSGlueConsoleFullAccess 策略附加至 IAM 角色。如果您使用 Athena 数据目录,将 AmazonAthenaFullAccess 策略附加到 IAM 角色。
b.在示例的步骤 2 中,您运行 COPY 命令来加载示例数据。COPY 命令包括 IAM 角色 Amazon 资源名称 (ARN) 的占位符。要加载示例数据,在 COPY 中添加角色 ARN。下面是 COPY 命令示例:
完成这些步骤后,您的 Amazon Redshift 集群即准备就绪。下面的部分描述了演示查询编辑器可实现的操作的三个步骤:
- 使用查询编辑器加载数据。
- 执行几个日常管理任务。
- 对 Amazon Redshift 集群和 Amazon S3 数据湖中存储的数据运行查询,无需加载或进行其他数据准备。
步骤 1:在查询编辑器中连接您的集群
要连接您的集群:
- 使用 Amazon Redshift 控制台上的左侧导航窗格导航至查询编辑器。
- 在集群下拉列表中的凭证对话框中,选择集群名称 (demo-cluster)。为此集群选择数据库和数据库用户。
- 如果您使用服务提供的默认值创建了集群,请将 dev 选为您的数据库选择,并在数据库用户框中输入 awsuser。
- 为集群输入密码。通常情况下,Amazon Redshift 数据库用户通过提供数据库用户名和密码进行登录。作为替代方法,如果您忘记了密码,您可以通过选择创建临时密码以加密格式检索密码,如下面的示例所示。有关更多信息,请参阅使用 IAM 身份验证生成数据库用户凭证。

如果您拥有 AWS 账户的查询编辑器相关权限,这将会连接到集群。有关更多信息,请参见前一部分中将查询编辑器相关权限添加到 AWS 账户的步骤。
步骤 2:使用示例数据集准备集群
要使用示例数据集准备集群:
- 在查询编辑器中运行以下 SQL。这将会在 Amazon Redshift 集群 demo-cluster 中创建架构 myinternalschema。

- 在查询编辑器中运行以下 SQL 语句,以为架构 myinternalschema 创建表。
- 使用 COPY 命令运行以下 SQL 语句,以在 us-east-1 区域中将示例数据集从 Amazon S3 复制到您的 Amazon Redshift 集群 demo-cluster 中。示例数据集的 Amazon S3 路径为 s3://aws-redshift-spectrum-sample-data-us-east-1/spectrum/event/allevents_pipe.txt。
选择运行查询之前,记得把示例中的占位符替换为与此 AWS 账户相关的 IAM 角色的 ARN。如果您的集群在另一个 AWS 区域中,请替换区域参数中的 Region 和 Amazon S3 路径,如下面的 SQL 命令所示:
- 要确保可以访问 Amazon S3 中的公共数据集,请确保此 AWS 账户具有能访问 Amazon S3、AWS Glue 和 Athena 的正确权限。有关更多信息,请参阅此博文前面所述的在示例数据集(Amazon S3 和 AWS Glue/Amazon Athena 数据目录权限)中加载和运行查询的步骤。
- 要在查询编辑器中验证以前创建的表中的数据,请浏览左侧架构查看器中的表。选择表名称旁的预览图标,以查看事件表中前 10 个记录。选择此选项将运行表格预览的以下查询,从而显示表中的 10 行内容:
您也可以输入自己的 SQL 语句。使用 Ctrl + Space 在查询编辑器中自动完成查询,以验证您创建的表中的数据。
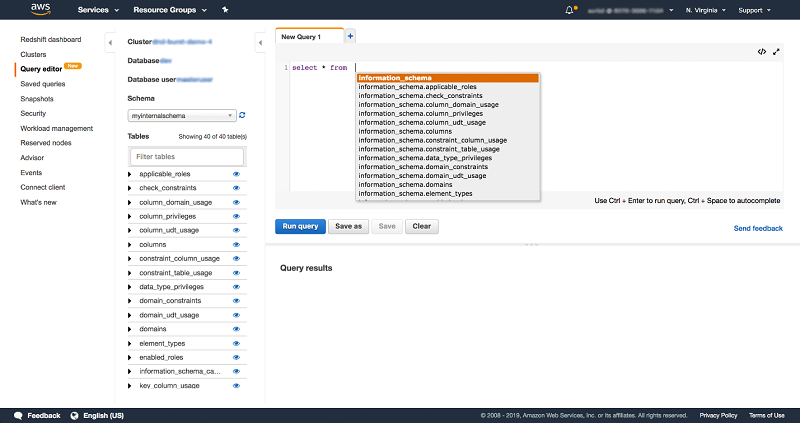
步骤 3:有用的集群管理查询
您已准备好尝试 Amazon Redshift 了! 在日常集群管理和监控中,您可以在查询编辑器中运行以下 SQL 查询。这些常用查询可让您查找并管理长期运行的查询、发现死锁状况并检查您的 Amazon Redshift 集群上的可用磁盘空间。通过在控制台的左侧导航窗格中选择保存的查询来保存这些查询并方便地访问它们,如下面的示例所示:

消除集群上的故障或长期运行的查询
如果存在必须要关闭的故障查询,通常要经过多步骤过程才能找到查询。在查询编辑器中运行以下 SQL 以查找使用 SQL 语句在 Amazon Redshift 集群中运行的所有查询:
从查询结果集中找到故障查询后,使用取消 <pid> <msg> 命令来消除查询。务必使用过程 ID(在以前的 SQL 中为 pid)而非查询 ID。您可以提供一个可选消息,该消息将返回至查询发布者并被记录。
监测集群上使用的磁盘空间
最常用的控制台功能之一是监测集群所用磁盘空间的百分比。如果集群中用于创建查询运行时使用的临时表的空间有限,查询将会失败。如果集群中没有可用空间在集群恢复过程中存储中间数据,Vacuum 也可能会失败。监测此指标对于在集群满载之前进行计划很重要,且您必须调整集群大小或添加更多集群。
如果您怀疑您的 Amazon Redshift 磁盘使用量过高或已满,请在查询编辑器中运行以下 SQL,以查找可用磁盘空间并查看集群上的各个表大小:
您可以从这里删除不必要的表,或者调整集群的大小以获得更大的容量。有关更多信息,请参阅调整 Amazon Redshift 中的集群大小。
观察集群上可疑的长时间运行更新有无发生死锁状况
如果集群发生可疑的长时间运行更新,它可能处于死锁事务中。stv_locks 表中显示了已锁定的任何事务,以及相关会话的过程 ID。此 pid 可以传递到 pg_terminate_backend(pid) 中,以消除有问题的会话。
在查询编辑器中运行 SQL 语句,以检查锁定情况:
要关闭会话,请使用 stl_locks 中的值运行 select pg_terminate_backend(lock_owner_pid)。
查看受集群最新 Vacuum 影响的行
通过在集群中的表上运行 Vacuum 命令,可以回收由于删除和更新操作而产生的任何可用空间。同时,表中的数据将被排序。结果将产生紧凑型排序表,从而提高集群性能。
运行以下 SQL 语句以查看从 svv_vacuum_summary 表的最新 Vacuum 中删除或存储的行的计数:
调试 Amazon Redshift 集群的连接问题
加入 stv_sessions 和 stl_connection_log 表会返回所有会话的列表(集群上的所有连接、身份验证和断开连接)及各自的远程主机和端口信息。
要列出所有连接,请在查询编辑器中运行以下 SQL 语句:
使用保存的查询功能将这些常用的 SQL 语句保存在您的账户中,并在查询编辑器中单击一下运行它们。
额外的步骤 4:使用 Amazon Redshift Spectrum 查询
使用 Amazon Redshift Spectrum,您可以在 Amazon S3 中查询数据,无需首先将其加载到 Amazon Redshift 中。Amazon Redshift Spectrum 查询采用大量并行处理 S3 中的大型数据集,无需将该数据提取到 Amazon Redshift 中。大部分处理发生在 Amazon Redshift Spectrum 层。多个集群可以同时查询 Amazon S3 中的同一个数据集,无需对每个集群的数据进行复制。
要使用 Amazon Redshift Spectrum 进行设置,请在查询编辑器中为 demo-cluster 运行以下 SQL 语句。如果您的集群在另一个 AWS 区域中,务必替换区域参数中的 Region 和以下 SQL 语句中的 Amazon S3 路径。
要从数据目录中创建新架构以与 Amazon Redshift Spectrum 结合使用:
要为 Amazon Redshift Spectrum S3 示例数据集创建表:
开始查询!
此部分提供开始从外部 (Amazon S3) 销售表和内部 (Amazon Redshift) 事件表中查询数据的示例场景。在此场景下加入查询将查找销售价格已支付 > 50(从 Amazon S3 中的 Amazon Redshift Spectrum 数据集中,s3://aws-redshift-spectrum-sample-data-us-east-1/spectrum/sales/)的所有事件(从 demo-cluster 上加载的销售数据集中)。
在查询结果部分中,选择查看执行以查看详细的执行计划。查询计划可用于在计算节点上执行的所有查询。
注:未参考用户表的查询,如只使用目录表的管理查询,没有可用的查询计划。
或者,可以将查询结果下载到您的本地磁盘中供离线使用。查询在查询编辑器中最多运行三分钟。查询完成后,查询编辑器将提供两分钟来获取结果。如果您达到了两分钟的阈值,请返回查询并重试。

通过使用以下 SQL 语句从 Amazon Redshift 示例数据集中加载其他表格,然后创造性地进行查询。在查询编辑器中选择运行查询之前,请记住在以下 SQL 语句的占位符中添加与此 AWS 账户相关的 IAM 角色的 ARN。如果您的集群处于另一个 AWS 区域中,请替换区域参数中的 Region 和以下 SQL 语句中的 Amazon S3 路径。
小结
在此博文中,我们介绍了查询编辑器,它是一个浏览器内界面,用于在 Amazon Redshift 集群上运行 SQL 查询。我们向您展示了如何使用它运行 SQL 查询以将数据加载到集群中及直接从控制台中监控集群性能。要详细了解 Amazon Redshift 并开始使用查询编辑器,请访问 Amazon Redshift 网页。
如果您喜欢此功能,如下所示通过使用控制台上的发送反馈链接分享您的反馈。

如果您有任何问题或建议,请在下方留言。
快乐查询!
关于作者
 Surbhi Dangi 是 AWS 的高级产品/设计经理。她的工作包括构建数据库、分析和 AI AWS 控制台的用户体验、启动新数据库和分析产品、处理现有产品的新功能发布以及为 AWS 团队构建广泛采用的内部工具。她喜欢去新的目的地旅游,探索新文化,喜欢尝试新的美食,向有志气的 PM 教授产品管理 101。
Surbhi Dangi 是 AWS 的高级产品/设计经理。她的工作包括构建数据库、分析和 AI AWS 控制台的用户体验、启动新数据库和分析产品、处理现有产品的新功能发布以及为 AWS 团队构建广泛采用的内部工具。她喜欢去新的目的地旅游,探索新文化,喜欢尝试新的美食,向有志气的 PM 教授产品管理 101。
 Raja Bhogi 是 AWS 的工程经理。他负责为分析和区块链产品构建愉悦且易于使用的 Web 体验。他的工作包括启动新分析产品的 Web 体验,以及处理现有产品的新功能发布。他对 Web 技术、性能详情和调整充满热情。他是一个寻求刺激的人,喜欢过山车到蹦极之类的一切刺激运动。
Raja Bhogi 是 AWS 的工程经理。他负责为分析和区块链产品构建愉悦且易于使用的 Web 体验。他的工作包括启动新分析产品的 Web 体验,以及处理现有产品的新功能发布。他对 Web 技术、性能详情和调整充满热情。他是一个寻求刺激的人,喜欢过山车到蹦极之类的一切刺激运动。