亚马逊AWS官方博客
在现代数据架构中将 Amazon Redshift RA3 与托管存储结合使用
Amazon Redshift 是云中一个完全托管的 PB 级数据仓库服务。您可以从几百 GB 数据开始,然后扩展到 1 PB 或更多。这使您能够使用自己的数据为企业和客户获取新的见解。
多年来,为了满足我们的客户需求,Amazon Redshift 发生了很大变化。它最初是一个独立的数据仓库设备,提供基于云的低成本、高性能数据仓库。后来添加了对 Amazon Redshift Spectrum 计算节点的支持,以支持将数据仓库扩展到数据湖,还添加了并发扩展功能,以支持突发活动和扩展数据仓库来同时支持数千个查询。在其最新产品中,Amazon Redshift 在第三代架构上运行,在该架构中,存储层和计算层相互分离,独立扩展。最新一代产品为我们的客户积极采纳的几种现代数据架构模式提供了支持,以构建灵活且可扩展的分析平台。
启动新的 Amazon Redshift 实例时,您可以选择 Amazon Redshift Serverless 以获得一个能够随着需求的不可预测变化无缝自动扩展的数据仓库,您也可以选择 Amazon Redshift 预置集群来处理稳态工作负载并更好地控制 Amazon Redshift 集群的配置。
Amazon Redshift 预置集群是称为节点的计算资源的集合,这些资源被组织成一个称为集群的组。每个集群都运行 Amazon Redshift 引擎并包含一个或多个数据库。创建 Amazon Redshift 集群是构建 Amazon Redshift 数据仓库过程中的第一步。启动预置集群时,您指定的一个选项是节点类型。节点类型决定了每个节点的 CPU、RAM、存储容量和存储驱动器类型。
在这篇博文中,我们将介绍当前一代节点 RA3 架构、不同的 RA3 节点类型、仅在 RA3 节点类型上可用的重要功能,以及如何将当前的 Amazon Redshift 节点类型升级到 RA3。
Amazon Redshift RA3 节点
借助具有托管存储的 RA3 节点,您可以通过独立扩展和支付计算和托管存储费用来优化数据仓库。RA3 节点类型是 Amazon Redshift 的最新节点类型。使用 RA3,您可以根据性能要求选择节点数,并且只需为使用的托管存储付费。RA3 架构使您能够根据每天处理的数据量或要在仓库中存储的数据量来调整集群规模;无需同时考虑存储和处理需求。
我们之前提供的其他节点类型包括:
- 密集计算 — DC2 节点使您能够拥有包含本地 SSD 存储的计算密集型数据仓库。您可以根据数据大小和性能要求选择所需的节点数。
- 密集存储(已弃用)— DS2 节点使您能够使用硬盘驱动器 (HDD) 创建大型数据仓库。如果您使用的是 DS2 节点类型,我们强烈建议您升级到 RA3,以便以相同的按需成本获得两倍的存储空间和更高的性能。
当您使用 RA3 节点大小并选择节点数时,您可以独立于存储来预置计算。RA3 节点基于 AWS Nitro 系统构建,具有高带宽联网和大型高性能 SSD 作为本地缓存。RA3 节点使用您的工作负载模式和高级数据管理技术来提供本地 SSD 的性能,同时自动将存储扩展到 Amazon Simple Storage Service (Amazon S3)。
RA3 节点类型有三种不同的大小,可适应您的各种分析工作负载。您可以通过创建单节点 ra3.xlplus 集群来快速开始试验 RA3 节点类型,并探索各种可用的功能。如果您运行的是中型数据仓库,则可以使用 ra3.4xlarge 节点调整集群规模。对于大型数据仓库,您可以从 ra3.16xlarge 开始。下表提供了截至撰写本文时有关 RA3 节点类型及其规格的更多信息。
| 节点类型 | vCPU |
RAM (GiB) |
每个节点的默认切片数 | 每个节点的托管存储配额 | 创建集群的节点范围 | 托管存储总容量 |
| ra3.xlplus | 4 | 32 | 2 | 32 TB | 1-16 | 1024 TB |
| ra3.4xlarge | 12 | 96 | 4 | 128 TB | 2-32 | 8192 TB |
| ra3.16xlarge | 48 | 384 | 16 | 128 TB | 2-128 | 16384 TB |
具有托管存储的 Amazon Redshift
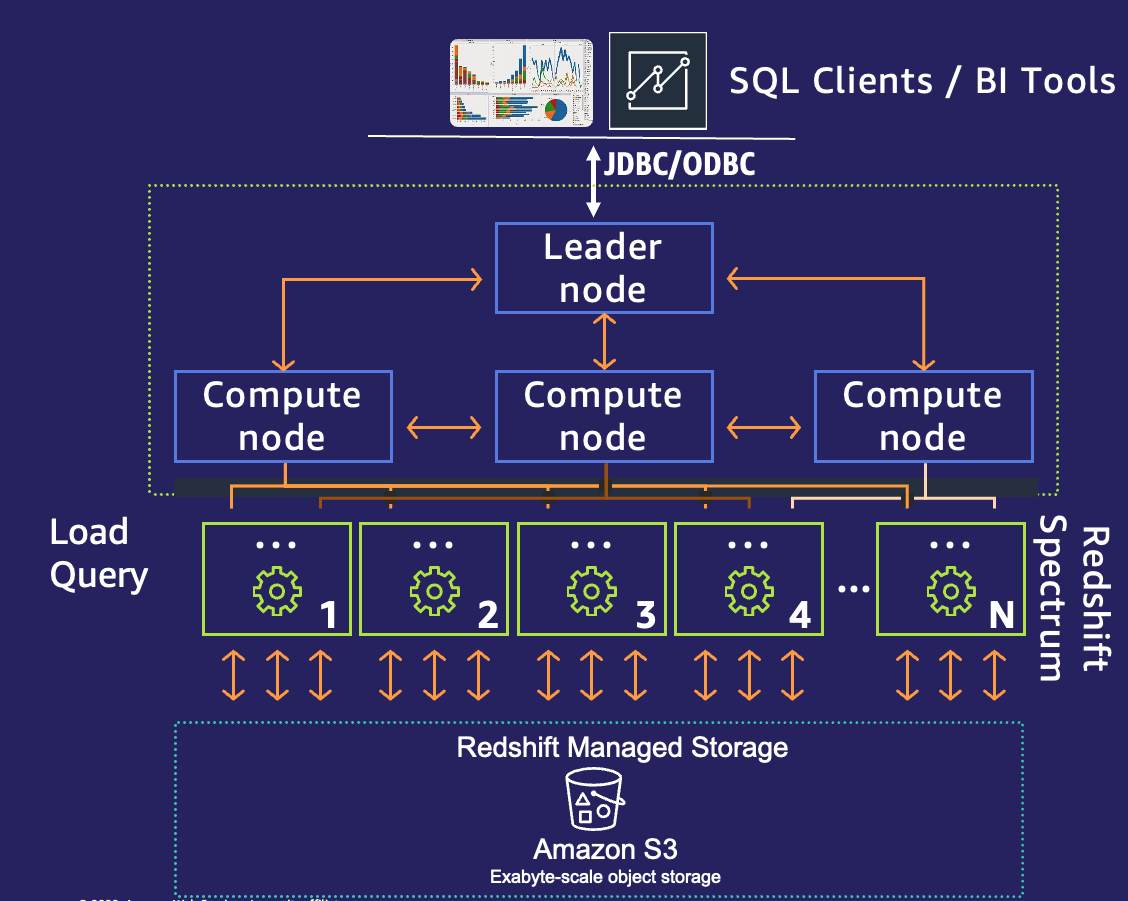
具有托管存储架构 (RMS) 的 Amazon Redshift 仍然拥有相同的弹性和业界领先的硬件。借助托管存储,Amazon Redshift 可根据数据的温度使用智能数据预取和数据驱逐功能。此方法可帮助您决定将查询次数最多的数据存储在何处。最常使用的块(热数据)缓存在 SSD 本地,不常使用的块(冷数据)存储在由 Amazon S3 支持的 RMS 层上。下图描述了领导节点、计算节点和 Amazon Redshift 托管存储。
在以下各部分,我们将讨论具有托管存储的 Amazon Redshift RA3 可以提供的功能。
独立扩展计算和存储
随着组织规模的扩大,数据也在不断增长,达到 PB 级。您摄入 Amazon Redshift 数据仓库的数据量也在增加。您可能希望能够经济高效地分析所有数据,同时控制在正确的时间选择正确的计算或存储资源。对于追求成本效益的客户,RA3 平台提供了单独扩展和支付计算和存储资源的选项。
使用具有托管存储的 RA3 实例,您可以根据性能要求选择节点数,并且只需为使用的托管存储付费。这使您可以根据每天处理的数据量灵活地调整 RA3 集群的大小,而不会增加存储成本。它允许您按小时支付计算费用并单独扩展数据仓库存储容量,而无需添加任何额外的计算资源,也只需按实际使用量付费。
RMS 的另一个好处是,Amazon Redshift 管理哪些数据应该存储在本地以实现最快速的访问,而稍微冷一些的数据仍然保持在快速访问范围内。
高级硬件
RA3 实例使用基于 AWS Nitro 系统构建的高带宽联网来进一步缩短将数据分载到 Amazon S3 以及从中检索数据所花费的时间。托管存储使用高性能 SSD 来存储热数据,使用 Amazon S3 来存储冷数据,从而提供简单易用、经济高效的存储和快速的查询性能。
其他安全选项
借助 Amazon Redshift 托管 VPC 端点,您可以设置专用连接,以便从同一 AWS 账户、另一个 AWS 账户或子网中的另一个 VPC 中的客户端应用程序安全地访问虚拟私有云 (VPC) 中的 Amazon Redshift 集群,而无需使用公共 IP,也无需流量穿越 Internet。
以下场景描述了允许使用 Amazon Redshift 托管 VPC 端点访问集群的常见原因:
- AWS 账户 A 想要允许 AWS 账户 B 中的 VPC 访问集群
- AWS 账户 A 想要允许同样位于 AWS 账户 A 中的 VPC 访问集群
- AWS 账户 A 想要允许 AWS 账户 A 中集群的 VPC 中的其他子网访问集群
有关另一个 VPC 的访问选项的信息,请参阅允许从另一个 VPC 中的客户端应用程序对 Amazon Redshift 进行专用访问。
进一步优化您的工作负载
在本部分,我们将讨论进一步优化工作负载的两种方法。
AQUA
AQUA (Advanced Query Accelerator) 是一种新的分布式硬件加速缓存,通过自动提升某些查询类型,使 Amazon Redshift 的运行速度达到其他企业云数据仓库的 10 倍。AQUA 可用于 ra3.16xlarge、ra3.4xlarge 或 ra3.xlplus 节点,无需额外付费,也无需更改代码。
AQUA 是 Amazon Redshift 的分析查询加速器,它使用定制设计的硬件来加快扫描大型数据集的查询速度。AQUA 会自动优化对需要大量扫描、筛选和聚合的数据子集的查询性能。通过这种方法,您可以使用 AQUA 运行扫描、筛选和聚合大型数据集的查询。
有关使用 AQUA 的更多信息,请参阅如何评估 AQUA 对您的 Amazon Redshift 工作负载的好处。
写入操作的并发扩展
借助 RA3 节点,您可以利用并发扩展来执行写入操作,例如提取、转换和加载 (ETL) 语句。如果您希望在集群收到大量请求时保持一致的响应时间,那么写入操作的并发扩展特别有用。它提高了争夺主集群资源的写入操作的吞吐量。
并发扩展支持 COPY、INSERT、DELETE 和 UPDATE 语句。在某些情况下,您可能会跟随 DDL 语句(如 CREATE),在同一个提交块中使用写入语句。在这些情况下,写入语句不会发送到并发扩展集群。
当您累积并发扩展的信用时,此信用累积适用于读取和写入操作。
提高了扩展计算资源的敏捷性
弹性大小调整使您能够在几分钟内纵向扩展或缩减 Amazon Redshift 集群,以便在需要时获得所需的性能。但是,您可以添加到集群的节点有限制。对于某些 RA3 节点类型,您可以将节点数增加到现有计数的四倍。所有 RA3 节点类型都支持将节点数减少到现有数量的四分之一。下表列出了每种 RA3 节点类型的增长和减少限制。
| 节点类型 | 增长限制 | 减少限制 |
| ra3.xlplus | 2 倍(例如,从 4 节点到 8 节点) | 到现有数量的四分之一 |
| ra3.4xlarge | 4 倍(例如,从 4 节点到 16 节点) | 到现有数量的四分之一(例如,从 16 节点到 4 节点) |
| ra3.16xlarge | 4 倍(例如,从 4 节点到 16 节点) | 到现有数量的四分之一(例如,从 16 节点到 4 节点) |
由于存储和计算是分开的,RA3 节点类型的快照恢复时间也较短。
提高了弹性
Amazon Redshift 采用广泛的故障检测和自动修复技术,以最大限度地提高集群的可用性。借助 RA3 架构,您可以启用集群重新定位,这样就可以在不丢失任何数据(RPO 为零)或更改客户端应用程序的情况下跨可用区重新部署集群,从而提供额外的弹性。重新定位后,集群的端点保持不变,因此应用程序无需修改即可继续运行。当现有集群出现故障时,将在另一个可用区中按需创建一个新集群,从而避免了备用副本集群的成本。
加快数据民主化
在本部分,我们将分享三种加速数据民主化的技术。
数据共享
数据共享提供了即时、精细和高性能的访问,而无需复制数据和移动数据。您可以在同一 AWS 账户、不同 AWS 账户或不同 AWS 区域中的不同 RA3 集群上持续查询所有使用者的实时数据。安全共享数据,提供受监管的协作。您可以提供不同粒度的访问权限,包括架构、数据库、表、视图和用户定义的函数。
这开启了各种新的用例,在这些用例中,您可能有一个 ETL 集群正在生成数据,并且有多个使用者(例如临时查询、仪表板和数据科学集群)来查看相同的数据。这也实现了双向协作,营销和财务等小组可以彼此共享数据。访问共享数据的查询使用使用者 Amazon Redshift 集群的计算资源,不会影响创建者集群的性能。
有关数据共享的更多信息,请参阅在 Amazon Redshift 集群之间安全共享 Amazon Redshift 数据以实现工作负载隔离。
AWS Data Exchange for Amazon Redshift
AWS Data Exchange for Amazon Redshift 使您能够在 AWS Data Exchange 中查找和订阅第三方数据,您可以在几分钟内在 Amazon Redshift 数据仓库中查询这些数据。您还可以通过 AWS Data Exchange 在 Amazon Redshift 中许可数据。当客户订阅您的数据时,会自动授予访问权限,并在其订阅结束时自动撤销访问权限。自动生成发票,并通过 AWS 自动收取和支付款项。借助此功能,您能够使用这些第三方数据集快速查询、分析和构建应用程序。
有关如何使用 AWS Data Exchange for Amazon Redshift 发布数据产品和订阅数据产品的详细信息,请参阅新增功能 — AWS Data Exchange for Amazon Redshift。
Amazon Redshift 的跨数据库查询
Amazon Redshift 支持跨 Redshift 集群中的数据库进行查询的功能。通过跨数据库查询,无论您连接到哪个数据库,您都可以无缝地查询集群中任何数据库的数据。跨数据库查询可以消除数据副本并简化数据组织,以支持同一集群上的多个业务组。
有很多用例都能体现跨数据库查询对您的帮助,其中一个是,在 Redshift 集群中跨多个数据库组织数据以支持多租户配置。例如,拥有和管理同一数据仓库中特定数据库中的数据集的不同业务组和团队需要与其他组协作。当原始数据分布在多个数据库中时,您可能希望执行常见的 ETL 暂存和处理。从传统数据仓库系统迁移时,在多个 Redshift 数据库中组织数据也是一种常见的情况。通过跨数据库查询,您现在可以从 Redshift 集群上的任何数据库访问数据,且无需连接到该特定数据库。您还可以在一个查询中联接来自多个数据库的数据集
您可以在此处阅读有关跨数据库查询的更多信息。
升级到 RA3
无论您当前的 Amazon Redshift 集群规模如何,您都可以在几分钟内升级到 RA3 实例。只需拍摄集群的快照并将其还原到新的 RA3 集群即可。有关更多信息,请参阅升级到 RA3 节点类型。
您还可以使用 Amazon Redshift Simple Replay 来简化迁移工作。有关更多信息,请参阅使用 Simple Replay 实用程序简化 Amazon Redshift RA3 迁移评估
小结
在这篇博文中,我们讨论了 RA3 节点类型、Amazon Redshift 托管存储的好处,以及将 Amazon Redshift RA3 与托管存储结合使用所获得的其他功能。迁移到 RA3 节点类型并不复杂,您可以立即开始。
关于作者
 Bhanu Pittampally 是驻达拉斯办事处的一名分析专家解决方案构架师。他擅长构建分析解决方案。他侧重于数据仓库领域,包括架构、开发和管理。他在数据和分析领域工作了超过 13 年。
Bhanu Pittampally 是驻达拉斯办事处的一名分析专家解决方案构架师。他擅长构建分析解决方案。他侧重于数据仓库领域,包括架构、开发和管理。他在数据和分析领域工作了超过 13 年。
 Jason Pedreza 是 AWS 的高级分析专家解决方案构架师,拥有处理 PB 级数据的数据仓库经验。在加入 AWS 之前,他为 Amazon.com 构建了各种数据仓库解决方案。他专长于 Amazon Redshift,帮助客户构建可扩展的分析解决方案。
Jason Pedreza 是 AWS 的高级分析专家解决方案构架师,拥有处理 PB 级数据的数据仓库经验。在加入 AWS 之前,他为 Amazon.com 构建了各种数据仓库解决方案。他专长于 Amazon Redshift,帮助客户构建可扩展的分析解决方案。