Blog de Amazon Web Services (AWS)
Cómo Verizon Media Group migró de Apache Hadoop y Spark de su centro de datos a Amazon EMR
Este es un artículo de los autores invitados por Verizon Media Group
En Verizon Media Group (VMG), uno de los principales problemas a los que nos enfrentábamos era la dificultad de ampliar la capacidad de informática en el tiempo que se requiere para adquirir hardware, lo que a menudo llevaba meses. No era rentable ampliar y actualizar el equipo informático para adaptarse a los cambios de la carga de trabajo, y la actualización del software de administración redundante requería importantes periodos de inactividad e implicaba una gran cantidad de riesgos.
En VMG, dependíamos de tecnologías como Apache Hadoop y Apache Spark para ejecutar las canalizaciones de procesamiento de datos. Anteriormente administrábamos nuestros clústeres con Cloudera Manager, que tenía ciclos de liberación lenta. Por lo tanto, ejecutábamos versiones anteriores de las versiones de código abierto y no podíamos aprovechar las últimas correcciones de errores ni mejoras de rendimiento de los proyectos de Apache. Por estos motivos, junto con nuestra inversión existente en AWS, decidimos explorar la migración de nuestras canalizaciones de informática distribuida a Amazon EMR.
Amazon EMR es una plataforma de clúster administrada que simplifica la ejecución de marcos de big data, como Apache Hadoop y Apache Spark.
En esta publicación, hablaremos sobre los problemas que encontramos y resolvimos cuando creábamos una canalización atender nuestras necesidades de procesamiento de datos.
Acerca de nosotros
Verizon Media es, en última instancia, una empresa de publicidad en línea. La mayoría de los anuncios en línea hoy en día se realizan a través de anuncios de display, también conocidos como banners o anuncios de video. Independientemente del formato, todos los anuncios de Internet suelen lanzar varios tipos de balizas a los servidores de seguimiento, que suelen ser implementaciones de servidores web altamente escalables con la única responsabilidad de registrar las balizas recibidas en uno o varios puntos de acceso.
Arquitectura de canalización
En nuestro grupo, que se dedica principalmente a la publicidad en video, utilizamos servidores web NGINX implementados en varias ubicaciones geográficas, que registran los eventos ejecutados desde nuestro reproductor de video directamente a Apache Kafka para el procesamiento en tiempo real y a Amazon S3 para el procesamiento por lotes. Una canalización típica de datos en nuestro grupo implica el procesamiento de los datos de entrada, la aplicación de rutinas de validación y enriquecimiento, la suma de los datos resultantes y su replicación a otros destinos con fines informativos. El siguiente diagrama muestra una canalización típica que hemos creamos.
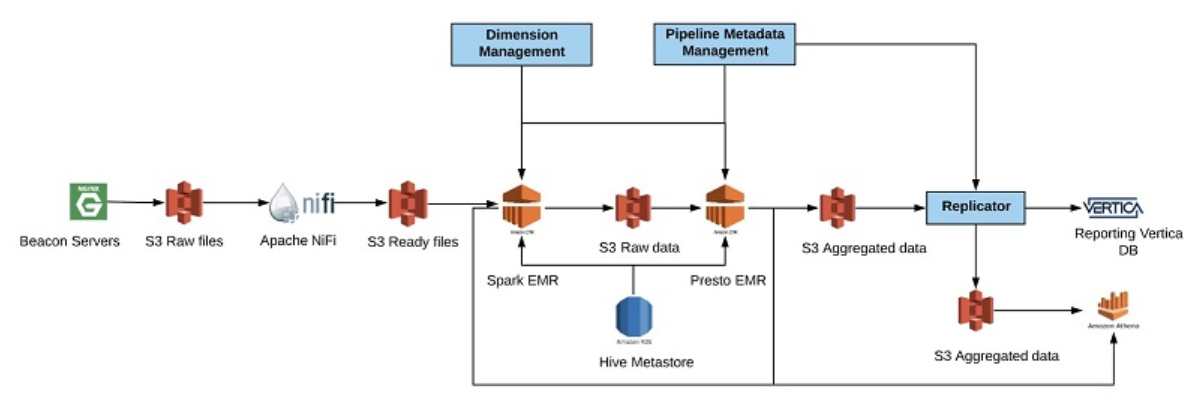
Comezamos a recibir datos en nuestros servidores de baliza NGINX. Los datos se almacenan en intervalos de 1 minutos en el disco local, con formato gzip. Cada minuto, movemos los datos de los servidores NGINX a la ubicación de los datos sin interpretar en S3. Tras acceder a S3, el archivo envía un mensaje a Amazon SQS. Apache NiFi espera los mensajes de SQS para comenzar a trabajar en los archivos. Durante este tiempo, NiFi agrupa los archivos pequeños en archivos más grandes y almacena el resultado en una ruta específica en una ubicación temporal en S3. El nombre de la ruta se combina con la marca de tiempo inversa para asegurarnos de que almacenamos los datos en una ubicación aleatoria y así evitar los cuellos de botella en la lectura.
Cada hora, escalamos el clúster de Spark en Amazon EMR para procesar los datos sin interpretar. Este procesamiento incluye el enriquecimiento y la validación de los datos. Los datos se almacenan en una carpeta de ubicación permanente en S3 en un formato de columnas de Apache ORC. También actualizamos el catálogo de datos de AWS Glue para que estos datos se muestren en Amazon Athena en caso de que necesitemos realizar una investigación por algún problema. Después de procesar los datos sin interpretar, disminuimos el clúster Spark EMR y comenzamos a agregar datos según las plantillas de concentración predefinidas mediante Presto en Amazon EMR. Los datos concentrados se almacenan en formato ORC, en una ubicación especial en S3.
También actualizamos nuestro catálogo de datos con la ubicación de los datos para poder consultarlos con Athena. Además, replicamos los datos de S3 en Vertica para que nuestros informes expongan los datos a clientes internos y externos. En este caso, usamos Athena como la solución de recuperación de desastres (DR) para Vertica. Cada vez que nuestra plataforma de información detecta que el estado de Vertica tiene problemas, automáticamente pasamos a Amazon Athena. Esta solución demostró ser sumamente rentable para nosotros. Tenemos otro caso de uso para Athena en nuestro análisis en tiempo real que no comentamos en esta publicación.
Desafíos de migración
La migración a Amazon EMR implicó algunos cambios en el diseño para obtener los mejores resultados. Cuando se ejecutan canalizaciones de big data en la nube, es necesario optimizar los costos operativos. Los principales costos son el almacenamiento y la informática. En las instalaciones tradicionales de Hadoop, estos están acoplados como nodos de almacenamiento que también actúan como nodos de computación. La desventaja de este acoplamiento es que cualquier cambio en la capa de almacenamiento, como el mantenimiento, también puede afectar a la capa de computación. En un entorno como el de AWS, podemos desacoplar el almacenamiento y la computación mediante S3 para el almacenamiento y Amazon EMR para la computación. Esto proporciona una gran ventaja de flexibilidad a la hora de realizar el mantenimiento de los clústeres, ya que todos son temporales.
Para ahorrar aún más costos, tuvimos que averiguar cómo lograr el máximo aprovechamiento en nuestra capa de computación. Esto implicó cambiar nuestra plataforma para usar múltiples clústeres para diferentes canalizaciones, donde cada clúster se escala automáticamente según las necesidades de canalización.
Cambio a S3
Ejecutar un almacén de datos Hadoop en S3 presenta consideraciones adicionales. S3 no es un sistema de archivos como HDFS y no ofrece las mismas garantías de consistencia inmediata. Puede considerar a S3 como un almacén de objetos eventualmente consistente con una API REST para acceder al mismo.
Las operaciones de cambio de nombre
Una de las diferencias clave de S3 es que el cambio de nombre archivos no es una operación atómica. Todas las operaciones de cambio de nombre en S3 ejecutan una copia seguida de una operación de borrado. Ejecutar cambios de nombre en S3 es poco conveniente debido a los costos de tiempo de ejecución. Para utilizar S3 de manera eficiente, debe eliminar el uso de cualquier operación de cambio de nombre. Las operaciones de cambio de nombre se utilizan comúnmente en los almacenes de Hadoop en varias etapas de confirmación, como el traslado de un directorio temporal a su destino final como una operación atómica. Lo mejor es evitar cualquier operación de cambio de nombre y, en su lugar, escribir los datos una vez.
Comisiones de salida
Tanto los trabajos de Spark como de Apache MapReduce tienen etapas de envío que confirman los archivos de salida producidos por varios trabajadores distribuidos en los directorios de salida final. En este artículo, no hablaremos sobre cómo funcionan las comisiones de salida, pero es importante destacar que las comisiones predeterminadas de salida estándar diseñadas para funcionar en HDFS dependen de operaciones de cambio de nombre, que como se ha explicado anteriormente, tienen una penalización de rendimiento en los sistemas de almacenamiento como S3. La estrategia más simple que nos funcionó fue desactivar la ejecución especulativa y cambiar la versión del algoritmo de las comisiones de salida. También puede escribir sus propias comisiones personalizadas para no depender de la operación de cambio de nombre. Por ejemplo, a partir de Amazon EMR 5.19.0, AWS lanzó un OutputCommitter personalizado para Spark que optimiza la escritura en S3.
Consistencia final
Uno de los mayores desafíos de trabajar con S3 es que con el tiempo es consistente, mientras que HDFS es altamente consistente. El S3 ofrece garantías de lectura tras la escritura para los PUTS de los nuevos objetos, pero esto no siempre es suficiente para crear canalizaciones distribuidas de forma consistente. Un caso común que se presenta mucho en el procesamiento de big data es un trabajo que genera una lista de archivos en un directorio y otro trabajo que lee desde ese directorio. Para que se ejecute el segundo trabajo, tiene que enumerar el directorio para encontrar todos los archivos que tiene que leer. En S3, no hay directorios; simplemente se enumeran los archivos con el mismo prefijo, lo que significa que es posible que no vea todos los archivos nuevos inmediatamente después de que termine de ejecutarse el primer trabajo.
Para abordar este problema, AWS ofrece EMRFS, que es una capa de coherencia agregada en la parte superior de S3 para que se comporte como un sistema de archivos consistente. EMRFS funciona con Amazon DynamoDB y mantiene metadatos sobre cada archivo de S3. Resumiendo, con EMRFS habilitado al enumerar un prefijo S3, la respuesta real de S3 se compara con los metadatos en DynamoDB. Si hay un desajuste, el controlador S3 sondea un poco más y espera a que se muestren los datos en S3.
En general, descubrimos que EMRFS era necesario para garantizar la coherencia de los datos. Para algunas de nuestras canalizaciones de datos, utilizamos PrestoDB para agregar datos almacenados en S3, donde decidimos ejecutar PrestoDB sin compatibilidad con EMRFS. Si bien esto nos ha expuesto al posible riesgo de consistencia final para nuestros trabajos ascendentes, descubrimos que podemos solucionar estos problemas al monitorear las discrepancias entre los datos descendentes y ascendentes y volver a ejecutar los trabajos ascendentes si es necesario. Según nuestra experiencia, los problemas de consistencia ocurren muy raramente, pero son posibles. Si elige ejecutar sin EMRFS, debe diseñar su sistema de acuerdo a ello.
Estrategias de escalado automático
Un desafío importante, aunque en cierto modo trivial, fue descubrir cómo aprovechar las capacidades de escalado automático de Amazon EMR. Para lograr costos operativos óptimos, queríamos aseguramos de que ningún servidor estuviera inactivo.
Para lograrlo, la respuesta podría parecer obvia: crear un clúster EMR de larga duración y utilizar las funciones de escalado automático disponibles para controlar el tamaño de un clúster en función de un parámetro, como la memoria libre disponible en el clúster. Sin embargo, algunas de nuestras canalizaciones por lotes comienzan cada hora, funcionan exactamente durante 20 minutos y son computacionalmente muy intensas. Como el tiempo de procesamiento es muy importante, teníamos que asegurarnos de no perder tiempo. La estrategia óptima para nosotros es cambiar el tamaño del clúster de manera preventiva mediante scripts personalizados antes de que comiencen las canalizaciones de lotes grandes particulares.
Además, sería difícil ejecutar varias canalizaciones de datos en un solo clúster e intentar mantenerlo a una capacidad óptima en un momento dado porque cada canalización es ligeramente diferente. En cambio, hemos optado por hacer funcionar todas nuestras canalizaciones principales en clústeres EMR independientes. Esto tiene muchas ventajas y solo una pequeña desventaja. Las ventajas son que cada clúster puede redimensionarse exactamente en el momento requerido, ejecutar la versión de software necesaria por su canalización y administrarse sin afectar a otras canalizaciones. El único inconveniente es que hay una pequeña cantidad de desperdicio computacional al ejecutar nodos adicionales de nombre y nodos de tarea.
Cuando desarrollamos una estrategia de escalado automático, primero intentamos crear y lanzar clústeres cada vez que necesitábamos hacer funcionar las canalizaciones. Sin embargo, descubrimos rápidamente que arrancar un clúster desde cero puede llevar más tiempo del que nos hubiese gustado. Al contrario, mantenemos estos clústeres siempre ejecutándose, y aumentamos el tamaño del clúster agreagando nodos de tarea antes de que empiece la canalización y eliminamos los nodos de tarea tan pronto como esta finaliza. Descubrimos que, simplemente agregando nodos de tarea, podemos comenzar a ejecutar nuestras canalizaciones mucho más rápido. Si tenemos problemas con los clústeres de larga duración, podemos reciclarlos rápidamente y crear uno nuevo desde cero. Seguimos trabajando con AWS con respecto a estos temas.
Nuestros scripts de escalado automático personalizados son simples scripts en Python, que normalmente se ejecutan antes de que empiece una canalización. Por ejemplo, supongamos que nuestra canalización consiste en un simple trabajo de MapReduce con una sola fase de mapeo y reducción. También supongamos que la fase de mapeo es más costosa desde el punto de vista computacional. Podemos escribir una secuencia de comandos simple que observe la cantidad de datos que deben procesarse la próxima hora y calcule la cantidad de mapeadores necesarios para procesar estos datos de la misma manera que lo hace un trabajo de Hadoop. Cuando conozcamos la cantidad de tareas de mapeo, podremos decidir cuántos servidores queremos para ejecutar todas las tareas de mapeadores en paralelo.
Cuando se ejecutan canalizaciones en tiempo real de Spark, la situación es un poco más complicada porque a veces tenemos que eliminar los recursos computacionales mientras se ejecuta la aplicación. Una estrategia sencilla que nos ha funcionado es crear un clúster independiente en tiempo real en paralelo al existente, ampliarlo hasta el tamaño requerido en función de la cantidad de datos procesados durante la última hora con alguna capacidad extra, y reiniciar la aplicación en tiempo real en el nuevo clúster.
Costos operativos
Puede evaluar todos los costos de AWS por adelantado con la calculadora EC2. Cuando se ejecutan canalizaciones de big data, los principales costos son el almacenamiento y la computación, con algunos costos menores adicionales, como DynamoDB cuando se utiliza EMRFS.
Costos de almacenamiento
El primer costo a considerar es el almacenamiento. Debido a que HDFS tiene un factor de replicación predeterminado de 3, requeriría 3 PB de capacidad de almacenamiento real en lugar de 1 PB.
Almacenar 1 GB en S3 cuesta aproximadamente 0,023 USD al mes. S3 ya es muy redundante, por lo que no necesita tener en cuenta el factor de replicación, lo que reduce los costos de inmediato en un 67 %. También debe considerar los otros costos de las solicitudes de escritura o lectura, pero estos suelen ser pequeños.
Costos de computación
El segundo mayor costo después del almacenamiento es el costo de computación. Para reducir los costos de computación, tiene que aprovechar al máximo los precios de instancia reservada. Un tipo de instancia m4.4xlarge con 16 VCPU en AWS cuesta 0,301 USD por hora cuando se reserva durante 3 años, con todas las tarifas por adelantado. Una instancia bajo demanda cuesta 0,8 USD la hora, lo que supone una diferencia de precio del 62 %. Esto es más fácil de lograr en organizaciones más grandes que planifican regularmente la capacidad. Se agrega una tarifa extra de 0,24 USD por hora a cada máquina Amazon EMR para el uso de la plataforma Amazon EMR. Es posible reducir aún más los costos utilizando las instancias de spot de Amazon EC2. Para obtener más información, consulte Opciones de compra de instancias.
Para conseguir costos operativos óptimos, intente asegurarse de que sus clústeres de computación nunca estén inactivos e intente reducir dinámicamente la escala en función de la cantidad de trabajo que dichos clústeres estén realizando en un momento dado.
Conclusiones
Llevamos más de un año operando nuestras canalizaciones de big data en Amazon EMR y almacenando todos nuestros datos en S3. En ocasiones, nuestros canales de procesamiento en tiempo real han alcanzado su punto máximo en el manejo de más de 2 millones de eventos por segundo, con una latencia de procesamiento total desde el evento inicial hasta los agregados actualizados de 1 minuto. Hemos disfrutado de la flexibilidad de Amazon EMR y su capacidad para derribar y recrear clústeres en cuestión de minutos. Estamos satisfechos con la estabilidad general de la plataforma Amazon EMR y seguiremos trabajando con AWS para mejorarla.
Como hemos mencionado antes, el costo es un factor importante a considerar, y podríamos decir que sería más barato ejecutar Hadoop en sus propios centros de datos. Sin embargo, este argumento depende de la capacidad de su organización para hacerlo de manera eficiente, ya que puede tener costos operativos subyacentes y reducir la elasticidad. Sabemos por experiencia que trabajar en las instalaciones no es una tarea que se deba tomar a la ligera y que requiere mucha planificación y mantenimiento. Creemos que las plataformas como Amazon EMR brindan muchas ventajas al diseñar sistemas de big data.
Aviso legal: el contenido y las opiniones de esta publicación corresponden a su autor y AWS no se responsabiliza por el contenido o la precisión de esta publicación.
Este artículo fue traducido del Blog de AWS en Inglés.
Sobre los autores
 Lev Brailovskiy es el director de Ingeniería que dirige el Grupo de Ingeniería de Servicios en la Supply Side Platform (SSP) en Verizon Media. Tiene más de 15 años de experiencia diseñando y desarrollando sistemas de software. En los últimos seis años, Lev se dedicó a diseñar, desarrollar y ejecutar programas informáticos de elaboración de informes y procesamiento de datos a gran escala tanto en centros de datos privados como en la nube pública.
Lev Brailovskiy es el director de Ingeniería que dirige el Grupo de Ingeniería de Servicios en la Supply Side Platform (SSP) en Verizon Media. Tiene más de 15 años de experiencia diseñando y desarrollando sistemas de software. En los últimos seis años, Lev se dedicó a diseñar, desarrollar y ejecutar programas informáticos de elaboración de informes y procesamiento de datos a gran escala tanto en centros de datos privados como en la nube pública.
 Zilvinas Shaltys es el jefe técnico de la plataforma de almacenamiento de datos en la nube de Video Syndication en Verizon. Zilvinas tiene una amplia experiencia trabajando con una gran variedad de importantes tecnologías de datos implementadas a una escala considerable. Fue responsable de migrar las canalizaciones de biga data de los centros de datos de AOL a Amazon EMR. Zilvinas trabaja actualmente en la mejora de la estabilidad y la escalabilidad de los sistemas de big data en tiempo real y por lotes existentes.
Zilvinas Shaltys es el jefe técnico de la plataforma de almacenamiento de datos en la nube de Video Syndication en Verizon. Zilvinas tiene una amplia experiencia trabajando con una gran variedad de importantes tecnologías de datos implementadas a una escala considerable. Fue responsable de migrar las canalizaciones de biga data de los centros de datos de AOL a Amazon EMR. Zilvinas trabaja actualmente en la mejora de la estabilidad y la escalabilidad de los sistemas de big data en tiempo real y por lotes existentes.
|
|
Use los datos para impulsar el crecimiento empresarial. Logre una innovación constante con el volante de inercia de datos |
