Amazon Web Services ブログ
カスタムメトリクスを用いた Amazon Elastic Container Service (ECS) のオートスケーリング
この記事は Amazon Elastic Container Service (ECS) Auto Scaling using custom metrics (記事公開日 : 2022 年 5 月 23 日) の翻訳です。
導入
Amazon ECS を使用することで、クラスター管理のための独自のインフラストラクチャをインストール、運用、スケールする必要がなくなります。
お客様は、Amazon ECS 上で動作するマイクロサービスアプリケーションのデプロイとスケーリングに、水平スケーラビリティを採用しています。これは、Application Auto Scaling サービスを用いて、メトリクスデータに基づいて自動でスケールすることで実現できます。Amazon ECS は通常、平均の CPU およびメモリ使用率に基づいて ECS サービスの使用率を測定し、定義済みの CloudWatch メトリクス、ECSServiceAverageCPUUtilization と ECSServiceAverageMemoryUtilization として公開します。Application Auto Scaling は、これらの定義済みのメトリクスとスケーリングポリシーを使用することで、サービス内のタスク数を比例的にスケールします。しかし、ダウンストリームにいるワーカーがリクエストをポーリング、処理するようなリクエストフローを持つユースケースもあります。このようなユースケースでは、リクエストの受信速度の変化に対応するようにワーカーをスケールしたいと考えるかもしれません。このように、お客様は、いつ、どの程度のスケーリングアクションを実行すべきかを決めるトリガーとして、ユースケースに関連したスケーリングメトリクスを使用したいと考えるでしょう。
平均レスポンス時間、新規リクエスト率、SQS キューのバッファの深さ、その他アプリケーションのある側面を追跡するカスタムメトリクスなど、追跡・測定可能なカスタムメトリクスは多数存在します。これらのカスタムメトリクスは、シナリオによっては、定義済みのメトリクスよりもスケーリングアクションのトリガーとして適している場合があります。
この記事では、マイクロサービス、分散システム、サーバーレスアプリケーションを分離、スケール可能にするフルマネージド型のメッセージキューサービス、Amazon Simple Queue Service (Amazon SQS) キューを用いて、負荷の変化に応じて ECS サービスをスケールする方法を紹介します。
シナリオ例
このシナリオでは、高可用性とオートスケーリングのために、ECS サービスに属する ECS タスクのフリート (訳注 : 本記事では、“フリート” は “集合” の意味で用います) 上で動作する非同期ウェブアプリケーションを想定します。このアプリケーションでは、ユーザーがバウチャーをアップロードすることで、オンラインで使用する前に残高と有効性を確認できます。バウチャーの確認プロセスは、典型的に、ユーザーにレスポンスを返す前に、関連する結果を取得するためにデータベースと通信します。ECS サービスは、典型的なアップロード速度に対応できるように構成されています。ECS サービスは、希望のタスク数を維持するために、異常なタスクを自動的に置き換えます。アプリケーションは、バウチャーのメタデータを SQS キューに格納します。そして、バウチャーを処理し、有効性ステータスと残高を返し、ユーザーがそれらを閲覧できるようにします。
このアーキテクチャは、バウチャーのアップロード数が時間と共に変化しない場合、うまく機能します。しかし、アップロード数が時間と共に変化する場合、Amazon SQS キューで待機するメッセージのレイテンシーを許容範囲内に維持するために、ECS サービスのキャパシティをスケールする、より動的なスケーリングメカニズムの使用を検討できます。この許容できる最大レイテンシーは、信頼性のあるユーザーエクスペリエンスを維持するための、アプリケーションの理想のサービスレベルアグリーメント (SLA) から導出できます。Amazon SQS キューの深さに関するカスタムメトリクスに基づくターゲット追跡スケーリングポリシーを使用する場合、動的スケーリングは、負荷の変化に応じてより効果的に ECS サービスのキャパシティを調整できます。
Amazon SQS キューで ApproximateNumberOfMessagesVisible のような CloudWatch メトリクスを使用する場合の問題は、キュー内のメッセージ数が ECS サービスのキャパシティに比例して変化しない可能性があることです。なぜなら、SQS キュー内のメッセージ数のみが、必要な ECS タスク数を決定する訳ではないからです。一般的に、ECS サービスのタスク数は、メッセージの処理時間や許容できるレイテンシー (キューの遅延) など、複数の要因によって左右される可能性があります。
解決案
その解決案として、タスクあたりのバックログに関するカスタムメトリクスを使用し、タスクあたりの許容バックログをターゲット値とすることです。この数値は以下のように計算できます。
- タスクあたりのバックログ – タスクあたりのバックログを計算するには、まず ApproximateNumberOfMessages キュー属性から SQS キューの長さ (キューから取得可能なメッセージ数) を決定します。次に、その値をフリートの実行中のキャパシティ (ECS サービスの場合、”実行中” 状態のタスク数) で割ると、タスクあたりのバックログが得られます。
- タスクあたりの許容バックログ – ターゲット値を計算するには、まずアプリケーションが許容できるレイテンシーを決定します。次に、許容できるレイテンシーを、ECS タスクがメッセージ処理にかかる平均時間で割ります。
例を用いて説明すると、現在の ApproximateNumberOfMessages が 1,500 であり、フリートの実行中のキャパシティが 10 の ECS タスクがあるとします。各メッセージの平均処理時間が 0.1 秒、許容できる最大レイテンシーが 10 秒だとすると、タスクあたりの許容バックログは 10 / 0.1 で、100 (メッセージ/タスク) となります。つまり、100 がターゲット追跡ポリシーのターゲット値となります。タスクあたりのバックログが現在 150 (1500/10) の場合、ターゲット値への比率を維持するために、フリートは 5 タスク分スケールアウトします。
デプロイ手順
以下の手順では、カスタムメトリクスの公開、ターゲット追跡スケーリングポリシーの作成、およびこれらの計算に基づいた ECS サービスのスケーリングの設定方法を示します。
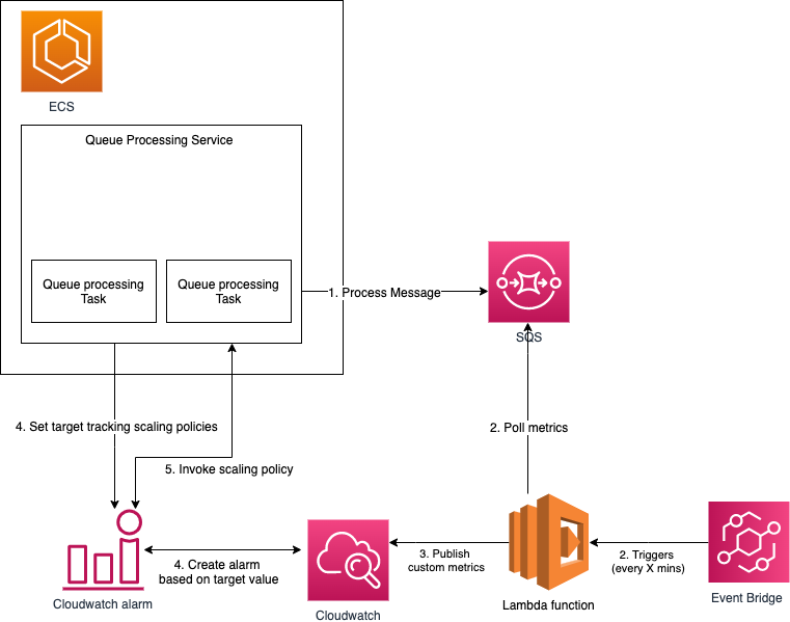
設定は、大きく 5 つのパートで構成されます。
- SQS キューからのメッセージを処理するタスクを管理するための ECS サービス。
- スケーリングメトリクスを計算する AWS Lambda 関数をトリガーする、定期的 (例えば 5 分ごと) な Amazon EventBridge のスケジュールイベント。この AWS Lambda 関数では、SQS キュー内の現在の ApproximateNumberOfMessages をポーリングし、その数を ECS タスクの現在のフリートの実行中のキャパシティで割ることで、タスクあたりのバックログに関するスケーリングメトリクスを計算します。
- AWS Lambda で計算される、タスクあたりのキュー内のメッセージ数 (タスクあたりのバックログ) を監視する Amazon CloudWatch カスタムメトリクス。
- カスタムメトリクスと、許容可能なレイテンシー (キューの遅延) を満たすターゲット値に基づいて、ECS サービスをスケールするように構成されたターゲット追跡ポリシー。ターゲット追跡スケーリングポリシーは、カスタムメトリクス (タスクあたりのバックログ) のターゲット値に基づいて、ECS サービスが実行するタスク数を増減します。これは、サーモスタットが家の温度を維持する方法とよく似ています。好みの温度を選択すると、サーモスタットが残りの処理を実行します。
- タスクあたりのバックログの測定値に基づいてスケーリングポリシーを呼び出す CloudWatch アラーム。
以下の図に、この構成のアーキテクチャを示します。
タスクあたりのバックログの計算方法に関する疑似コードを以下に示します。
exports.main = async function(event, context) {
try {
const clusterName = process.env.ECS_CLUSTER_NAME
const serviceName = process.env.ECS_SERVICE_NAME
const approximateNumberOfMessages = await getQueueAttributes(
process.env.QUEUE_URL,
({Attributes}) => Attributes["ApproximateNumberOfMessages"]
)
const numberOfActiveTaskInService = await getNumberOfActiveTaskInService(
process.env.ECS_CLUSTER_NAME,
process.env.ECS_SERVICE_NAME,
({taskArns}) => taskArns.length
)
const backlogPerTask = approximateNumberOfMessages/numberOfActiveTaskInService
const metricData = await putMetricData(backlogPerTask, clusterName, serviceName)
return {
statusCode: 200,
body: metricData
};
} catch(error) {
const body = error.stack || JSON.stringify(error, null, 2);
return {
statusCode: 400,
headers: {},
body: JSON.stringify(body)
}
}
}まとめ
多くのお客様は、高可用性とオートスケーリングのために Amazon ECS 上で非同期アプリケーションを構築したいと考えており、ECS タスクは、入ってくるリクエストをバッファする SQS キューからメッセージを消費するワーカーとして機能します。Amazon EventBridge と AWS Lambda を使用することで、タスクあたりのバックログを定期的に計算し、Amazon CloudWatch のカスタムメトリクスを更新、Amazon CloudWatch によってトリガーされたアラームに基づいて ECS サービスをスケールできます。これにより、アプリケーションの SLA を満たすために、ECS サービスを効率的にスケールし、適切なタイミングで適切なキャパシティをプロビジョニングできます。このアーキテクチャは、パフォーマンスとコストの最適化の適切なバランスを自動的に維持するのに役立つでしょう。私たちは、この記事があなたの役に立つことを願っています。また、このパターンがあなたの現在および将来のプロジェクトにどのようにフィットするかに関して、コメントやフィードバックをお待ちしています。