Amazon Web Services ブログ
コンタクトセンターからのカスタマーコールを分析するための AWS Machine Learning の使用 (パート 2): Amazon Transcribe、Amazon Comprehend、AWS CloudFormation、Amazon QuickSight を使用した分析の自動化、デプロイメント、および視覚化
前回のブログ記事では、コンタクトセンターでの通話におけるセンチメント分析を実施できるように Amazon Transcribe と Amazon Comprehend をつなぎ合わせる方法を説明しました。今回は、そのプロセスを自動化し、大規模なソリューションをデプロイするために AWS CloudFormation を活用する方法をご紹介します。
ソリューションアーキテクチャ
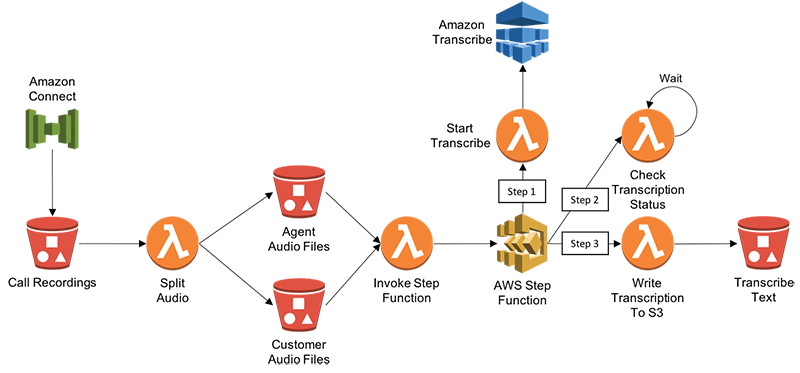
以下の図は、Amazon Transcribe を使ってコンタクトセンターからの通話記録のテキストトランスクリプトを作成するアーキテクチャを示しています。この例では Amazon Connect (クラウドベースのコンタクトセンターサービス) を参照していますが、このアーキテクチャはどのコンタクトセンターに対しても機能します。
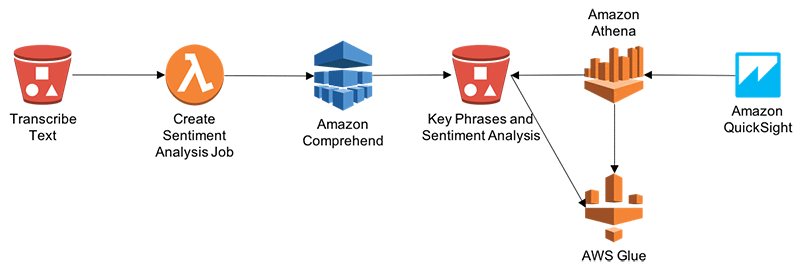
以下の図は、エンティティ分析、センチメント分析、およびキーフレーズ分析を実施するために、Amazon Comprehend を使用して文字に起こされたテキストを処理するアーキテクチャを示しています。最後に、Athena と QuickSight の組み合わせを使って分析を可視化することができます。
AWS CloudFormation を使用した自動化とデプロイメント
ここでは、上記のソリューションを自動化してデプロイするために AWS CloudFormation を使用します。
まず AWS コンソールにログインし、このリンクをクリックして CloudFormation でテンプレートを起動します。
コンソールで、以下のパラメータを入力します。
- RecordingsPrefix: 分割された記録が保存される S3 のプレフィックス
- TranscriptsPrefix: 文字に起こされたテキストが保存される S3 のプレフィックス
- TranscriptionJobCheckWaitTime: 文字起こしジョブチェック間の待ち時間 (秒単位)
他はすべてデフォルト値のままにしておきます。[AWS CloudFormation によって IAM リソースが作成される場合があることを承認します] の箇所にあるチェックボックスの両方にチェックを入れて、[変更セットの作成] をクリックしてから、[実行] を選択します。
このソリューションは以下のステップに沿って実行されます。
- Amazon Connect が通話記録と CTR レコードを Amazon S3 にドロップします。
- S3 の Put リクエストが、通話記録を 2 つのメディアチャネル (エージェント用とカスタマー用) に分割する AWS Lambda 関数をトリガーします。これは、2 つの出力音声ファイルを異なるフォルダにドロップします。
- S3 フォルダへの音声のドロップが AWS Step Functions を呼び出す Lambda 関数をトリガーします。
- ここでは、Amazon Transcribe の API を呼び出す Lambda 関数のスケジュールに Step Functions が使用されます。
- Step Functions からのステップ 1 が音声ファイルの文字起こしを開始します。
- ステップ 2 は、文字起こしジョブのステータスを一定の間隔でチェックします。ジョブステータスがジョブ終了になったら、プロセスがステップ 3 に進みます。
- ステップ 3 – 文字起こしジョブのステータスがジョブ終了になったら、文字に起こされた出力が S3 フォルダに書き込まれます。
- 文字に起こされたテキストの S3 へのドロップが、Amazon Comprehend API を呼び出し、エンティティ、センチメント、キーフレーズ、および言語の出力を S3 フォルダに書き込む Lambda 関数をトリガーします。出力を Amazon データウェアハウス – Redshift に書き込む必要がある場合は、Kinesis Firehose を利用できます。
- データベースカタログとデータベースのテーブル構造の維持には、AWS Glue が使用されます。Glue データベースカタログを使用した S3 内のデータのクエリには Amazon Athena を使用します。これで、CloudFormation テンプレートが完結します。
- 通話記録を分析するために Amazon QuickSight が使用され、発信者とエージェントとのやり取りのセンチメント分析とキーフレーズ分析を実行します。
Amazon QuickSight を使用した分析の視覚化
Amazon Comprehend のセンチメント分析を Amazon QuickSight を使って視覚化することができます。最初に、Amazon Athena と、アカウント内の関連する S3 バケットに対するアクセス権を Amazon QuickSight に付与する必要があります。これを実行するための詳細については、「Amazon QuickSight の AWS リソースへのアクセス権限の管理」を参照してください。 その後、デプロイメント中に作成された Athena テーブルに基づいて Amazon QuickSight に新しいデータセットを作成できます。
アクセス権限のセットアップ後、[New analysis] を選択することによって Amazon QuickSight で新しい分析を作成できます。

次に、新しいデータセットを追加します。
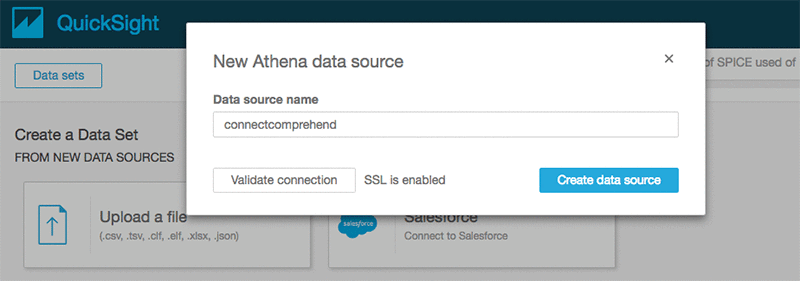
Athena をソースとして選択し、データソースに connectcomprehend などの名前を付けます。
データベースの名前を選択して、[Use Custom SQL] を選択します。
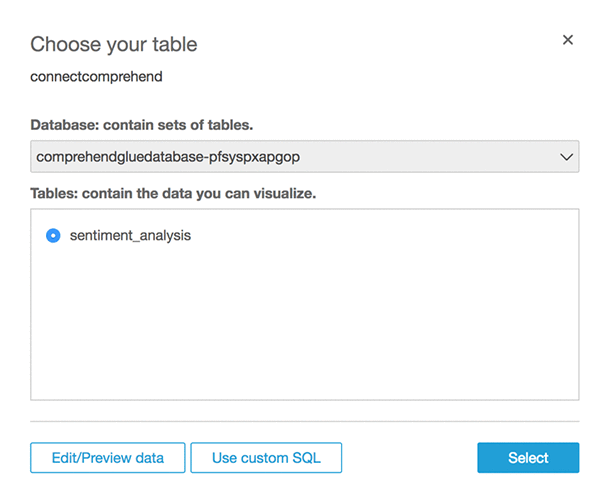
カスタム SQL に「Sentiment_SQL」などの名前を付けて、以下の SQL を入力します。データベース名 <YOUR DATABASE NAME> は、お使いのデータベース名に置き換えてください。
[Confirm query] を選択します。
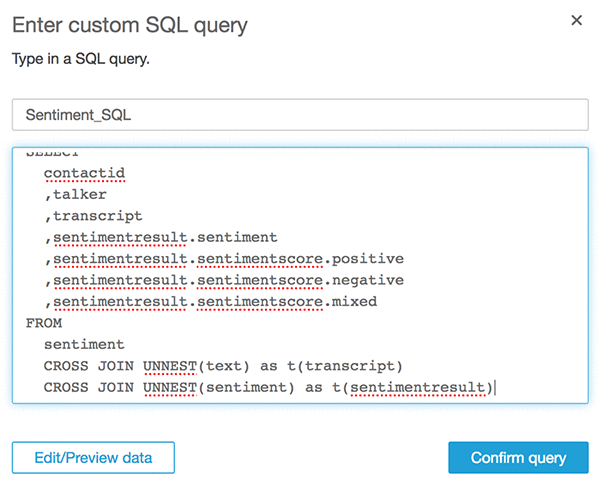
[Import to SPICE] オプションを選択してから、[Visualize] を選択します。
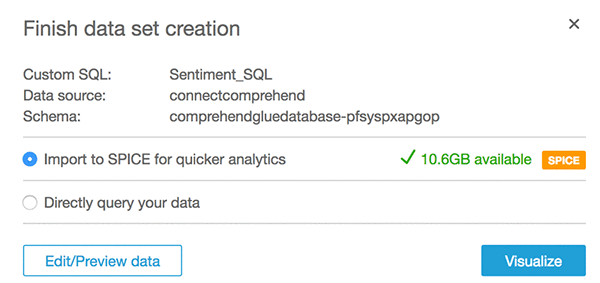
そうすると、以下の画面が表示されます。
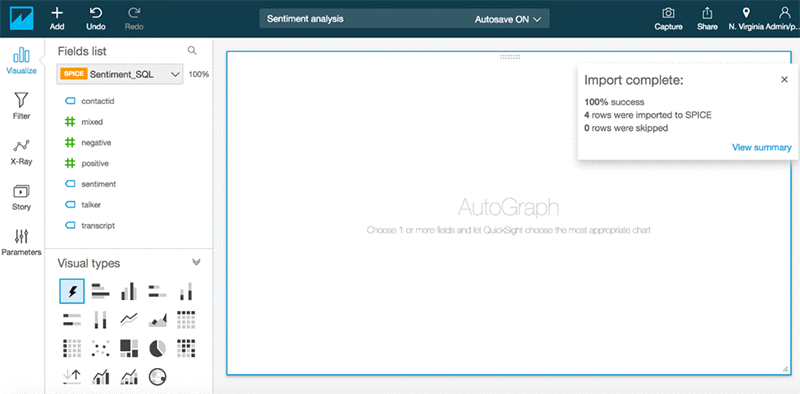
これで、視覚化のためにセンチメント分析を追加して、視覚化を実行することができるようになりました。
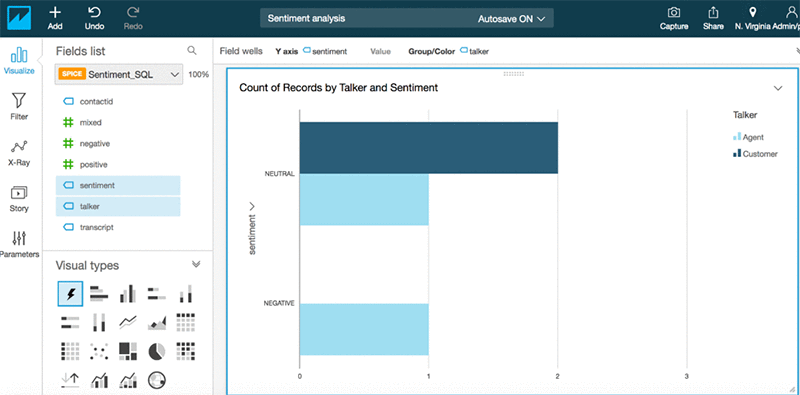
同様に、エンティティ、キーフレーズ、および言語などの他の Comprehend 出力を分析することもできます。S3 に利用可能な Amazon Connect CTR レコードがある場合、Comprehend 出力と CTR レコードのデータを組み合わせることができます。
結論
Amazon Transcribe および Amazon Comprehend などの Amazon AI サービスは、コンタクトセンターの記録を CTR (コール詳細)、コールフローログ、およびビジネス固有の属性などのその他のデータソースと組み合わせることによって、記録の分析を容易にします。企業は、コンタクトセンターでの膨大な量の発信者とエージェントの間の音声録音から隠れた価値を実現することで、大きなメリットを得ることができます。意味のある洞察を導き出すことで、企業はコールセンターの効率とパフォーマンスを向上させ、顧客に対する最終的なサービス品質を向上させることができます。ここまで、Amazon Transcribe を使用して音声データをテキストの文字起こしに変換した後、Amazon Comprehend を使用してテキスト分析を実行しました。分析中は、ソリューションをつなぎ合わせるために Lambda と Step Functions も使用しました。最後に、AWS Glue、Amazon Athena、および Amazon Quicksight を使って分析を視覚化しました。
著者について
Deenadayaalan Thirugnanasambandam
Piyush Patel
Paul Zhao
Revanth Anireddy
Loc Trinh