O blog da AWS
Aplicações escaláveis e econômicas orientadas a eventos com KEDA e Karpenter no Amazon EKS
Por Sanjeev Ganjihal e Asif Khan
No atual cenário nativo da nuvem, o gerenciamento eficiente das aplicações orientadas a eventos é essencial para o processamento de dados em tempo real. O escalonamento automático tradicional geralmente fica complicado em meio a volumes de eventos imprevisíveis, levando a ineficiências e aumento de custos. Amazon Elastic Kubernetes Service (EKS), é uma plataforma gerenciada de orquestração de container e adequada para a implantação de aplicações baseadas em container. Ao integrar o Kubernetes Event-Driven Autoscaling (KEDA) e o Karpenter com o Amazon EKS, podemos superar esses desafios. O KEDA permite o escalonamento automático detalhado com base em métricas de eventos, e o Karpenter garante o provisionamento dos worker nodes, endereçando as ineficiências do escalonamento manual. Esta postagem tem como objetivo fornecer um guia simplificado para integrar o KEDA e o Karpenter com o Amazon EKS para uma configuração mais eficiente, econômica e de alto desempenho.
Por meio de uma abordagem passo a passo, simplificaremos o processo de configuração para ajudar as equipes a gerenciar melhor as cargas de trabalho orientadas a eventos no Amazon EKS. Essa integração mostra uma configuração escalável, econômica e resiliente para lidar com aplicações orientadas a eventos em um ambiente Kubernetes, aproveitando ao máximo os recursos do Amazon EKS, KEDA e Karpenter.
Kubernetes Event-Driven Autoscaling (KEDA)
Voltando nossa atenção para o domínio do escalonamento automático, o KEDA se destaca como a base no escalonamento orientado a eventos. Ele habilita suas implantações do Kubernetes com a capacidade de se adaptar dinamicamente em resposta a eventos externos canalizados de várias fontes, como filas de mensagens e fluxos de eventos. Ao adotar um paradigma orientado a eventos, que permite que seus aplicativos sejam escalados com precisão de acordo com o fluxo de eventos, garantimos a otimização de recursos e a eficiência de custos. Com o KEDA, os clientes podem aproveitar uma infinidade de escaladores que atendem a diferentes fontes de eventos, fortalecendo a ponte entre o Kubernetes e o mundo externo.
Karpenter
O Karpenter é um escalador automático dos worker nodes do cluster Kubernetes, flexível e de alto desempenho, que oferece o aprovisionamento dinâmico e sem grupos da capacidade do nó de trabalho para atender a pods pendentes de recursos. Graças a arquitetura sem grupos do Karpenter, a restrição de usar tipos de instância especificados de forma semelhante é eliminada. O Karpenter avalia perpetuamente as demandas coletivas de recursos dos pods pendentes junto com outras restrições de agendamento (por exemplo, seletores de nós, afinidades, toleration e restrições de distribuição de topologia) e orquestra a capacidade computacional ideal da instância, conforme definido na configuração do NodePool. Essa flexibilidade permite que diferentes equipes personalizem suas próprias configurações do NodePool de acordo com seus requisitos de aplicação e escalabilidade. Além disso, o Karpenter aprovisiona diretamente os nós utilizando a interface de programação de aplicativos (API) do fleet Amazon EC2, ignorando a necessidade de nós e grupos de escalabilidade automática do Amazon EC2, o que acelera significativamente os tempos de provisionamento e novo teste (passando de minutos para meros milissegundos). Essa aceleração não apenas aumenta o desempenho, mas também aprimora os contratos de nível de serviço (SLAs).
Arquitetura da solução para executar aplicações orientadas a eventos no Amazon EKS
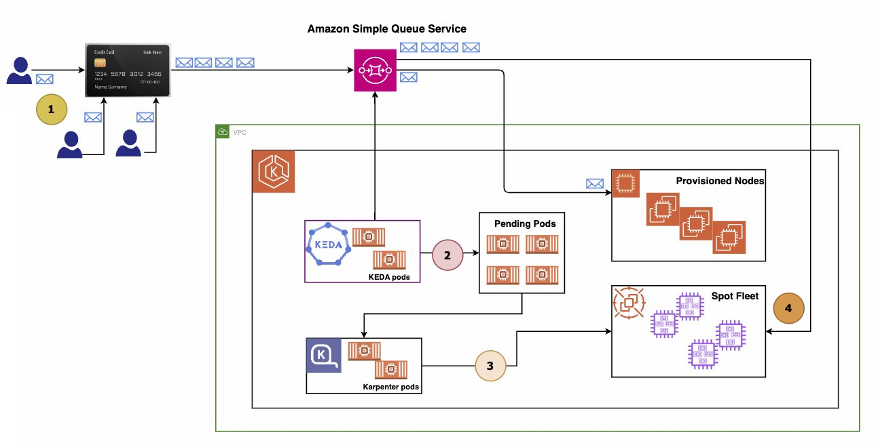
Esboço do fluxo de trabalho
- Início da transação financeira: os usuários iniciam transações financeiras que são capturadas e encaminhadas para um Amazon Simple Queue Service (SQS) Para fins de demonstração, um script emulando a função de um produtor de mensagens será executado para preencher a fila com mensagens representando transações.
- Consumo de mensagens de transação: dentro de um cluster do Amazon EKS, um aplicativo de consumidor de mensagens em container está monitorando e recuperando ativamente mensagens da fila do Amazon SQS para processamento.
- Aumento da profundidade da fila: à medida que o engajamento do usuário aumenta, exemplificado pela execução do script Message Producer em vários terminais durante a demonstração, o aumento do fluxo de mensagens de transação causa um aumento na profundidade da fila, indicando um acúmulo, pois o aplicativo Message Consumer se esforça para acompanhar a taxa de mensagens recebidas.
- Resposta de escalabilidade automatizada: Integrados ao cluster Amazon EKS estão o KEDA e o Karpenter, que monitoram continuamente a profundidade da fila. Ao detectar um acúmulo de mensagens, o KEDA aciona o aprovisionamento de pods adicionais de consumidores de mensagens, aprimorando a capacidade de processamento do sistema para gerenciar com eficácia o maior volume de mensagens em tempo hábil.
Visão geral da solução
Pré-requisitos:
- Uma conta da AWS
- eksctl — v0.162.0
- AWS CLI — v2.10.0
- kubectl — v1.28.3
- Helm — v3.13.1
- Docker — v24.0.6
- EKS — v1.28
- KEDA — v 2.12
- Karpenter — v0.32
Passo a passo
Exemplo de visão geral do aplicativo: orquestrando mensagens orientadas a eventos
Vamos nos aprofundar na construção de um aplicativo básico de processamento de mensagens, mostrando a orquestração perfeita de mensagens orientadas a eventos. O aplicativo compreende os seguintes componentes integrais:
- Amazon SQS: Servindo como a espinha dorsal de nossa arquitetura de mensagens, o Amazon SQS é um serviço de enfileiramento de mensagens totalmente gerenciado que gerencia as mensagens recebidas e as disponibiliza aos consumidores mediante solicitação.
- Produtor de mensagens: encapsulado em um container, esse aplicativo baseado em Python emula cenários de transações do mundo real publicando mensagens na fila do Amazon SQS.
- Consumidor de mensagens: Residindo em um container separado, o Consumidor de Mensagens vigia, examinando incessantemente a fila do SQS, para capturar imediatamente a mensagem mais antiga que aguarda processamento.
- Amazon DynamoDB: atuando como o ponto terminal de nossa jornada de mensagens, o consumidor de mensagens recupera mensagens da fila e as deposita devidamente em uma tabela do DynamoDB, marcando a conclusão do ciclo de processamento de mensagens.
Implantação do Amazon EKS Cluster, KEDA, Karpenter e aplicativo de amostra
Siga as etapas para configurar um cluster Amazon EKS e instalar o KEDA e o Karpenter no seu cluster Amazon EKS.
Clone o repositório em sua máquina local ou baixe-o como um arquivo ZIP usando o seguinte comando:
git clone https://github.com/aws-samples/amazon-eks-scaling-with-keda-and-karpenter.gitNavegue até o diretório do repositório:
cd amazon-eks-scaling-with-keda-and-karpenterModifique o arquivo environmentVariables.sh localizado no diretório de implantação de acordo com seus requisitos.
| Nome da variável | Descrição | |
| 1 | AWS_REGION | A região da AWS. |
| 2 | ACCOUNT_ID | O ID da conta da AWS. |
| 3 | TEMPOUT | Arquivo de saída temporário. Isso era usado para armazenar temporariamente CFN para karpenter |
| 4 | DYNAMODB_TABLE | O nome da tabela do Amazon DynamoDB. |
| 5 | CLUSTER_NAME | O nome do cluster Amazon EKS. |
| 6 | KARPENTER_VERSION | A versão do Karpenter. |
| 7 | NAMESPACE | O namespace Kubernetes para KEDA. |
| 8 | SERVICE_ACCOUNT | A conta de serviço do Kubernetes para KEDA. |
| 9 | IAM_KEDA_ROLE | A função do AWS IAM para o KEDA. |
| 10 | IAM_KEDA_SQS_POLICY | A política do AWS IAM para que o KEDA acesse o SQS. |
| 11 | IAM_KEDA_DYNAMO_POLICY | A política do AWS IAM para que o KEDA acesse o DynamoDB. |
| 12 | SQS_QUEUE_NAME | O nome da fila do Amazon SQS |
| 13 | SQS_QUEUE_URL | O URL da fila do Amazon SQS. |
| 14 | SQS_TARGET_DEPLOYMENT | A implantação do KEDA para escalar com base nas mensagens do Amazon SQS. |
| 15 | SQS_TARGET_NAMESPACE | O namespace de destino para a implantação que o KEDA escala com base nas mensagens do Amazon SQS. |
Para implantar o aplicativo, execute este comando
sh ./deployment/_main.shVocê deverá verificar a conta no contexto:
Em seguida, selecione sua opção de implantação:

Por debaixo do capô
Ao selecionar as opções 1, 2 ou 3, os componentes correspondentes são implantados. Especificamente, a opção três aciona a implantação de todos os componentes — o cluster Amazon EKS, o Karpenter e o KEDA.
Cada um desses componentes vem com seus próprios scripts de implantação independentes. Portanto, se você quiser ignorar o processo de implantação mencionado acima ou modificar os recursos de cada componente, poderá alterar os arquivos relevantes associados a cada componente:
- createCluster.sh
- createKarpenter.sh
- createKeda.sh
Essa configuração fornece uma abordagem flexível para implantar e personalizar os componentes de acordo com seus requisitos.
O repositório do GitHub abriga os arquivos de configuração essenciais necessários para a implantação do KEDA e do Karpenter. Esses arquivos podem ser personalizados para atender às suas necessidades específicas.
Abaixo estão alguns arquivos a serem considerados:
- deployment/keda: contém os arquivos de implantação dos componentes do KEDA.
- deployment/karpenter: contém os arquivos de implantação dos componentes do Karpenter.
Teste: escalabilidade KEDA e Karpenter em ação
Nesta seção, avaliaremos a eficácia do escalonamento por meio de um script de simulação. Em vez de várias solicitações do mundo real serem canalizadas para o Amazon SQS a partir de transações humanas, executaremos um script que injeta mensagens no Amazon SQS, imitando um cenário do mundo real.
O script keda-mock-sqs-post.py tem uma função simples que envia mensagens para o Amazon SQS em intervalos recorrentes especificados.

Conforme ilustrado no diagrama anterior, a arquitetura da implantação do nosso ambiente permanece inalterada; no entanto, introduzimos um script de criação de mensagens. Várias instâncias desse script serão executadas para simular uma carga realista, fazendo com que o KEDA e o Karpenter escalem os pods e worker nodes adequadamente.
Após a implantação do Cluster, do Karpenter e do KEDA, sua interface shell exibirá uma aparência semelhante.

Abra dois terminais adicionais e estabeleça uma conexão com o cluster Amazon EKS.
No primeiro terminal, navegue até o namespace keda-test.

No segundo terminal, navegue até a seção Nodes (seu terminal deve aparecer conforme mostrado abaixo).

Abra três ou mais terminais, copie o conteúdo do deployment/environmentVariables.sh e execute-o nos três terminais.
Essa ação configura o contexto do terminal com todas as variáveis de ambiente necessárias para a execução do script.
Execute o script keda-mock-sqs-post.py em todos os quatro terminais.

Navegue até o diretório app → keda e crie um ambiente virtual Python.
cd app/keda
python3 -m venv env
source env/bin/activate
pip install boto3
cd {your path}/amazon-eks-scaling-with-keda-and-karpenter
python3 ./app/keda/keda-mock-sqs-post.py Abra três ou quatro terminais e execute o script (ou seja, vários terminais são necessários para que possamos adicionar mais mensagens na fila e aumentar a profundidade da fila)

Após a ativação, os scripts começarão a injetar mensagens no Amazon SQS. Conforme mencionado anteriormente, há um único pod operando dentro do namespace keda-test, que verifica continuamente o Amazon SQS em busca de mensagens para processar.
Como as três instâncias de script anteriores estão enviando mensagens com alta frequência, esse pod se esforça para manter a escala de processamento das mensagens necessárias para manter o tamanho da fila dentro dos limites definidos (ou seja, 2) conforme especificado em keda-scaledobject.sh.

Quando o limite de scaleobject ==> QueueLength for excedido, o KEDA acionará a instanciação de pods adicionais para agilizar o processamento de mensagens do Amazon SQS e reduzir o tamanho da fila até os limites desejados.
Dimensionamento para oito pods e dois nós:
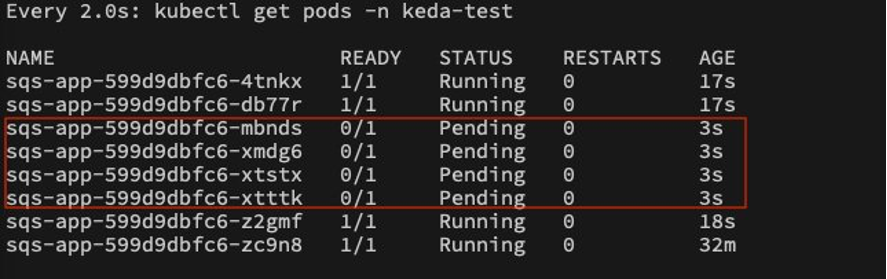

Devido a essa ação de escalonamento rápido iniciada pelo KEDA, começamos a observar vários pods em um estado pendente, pois o número padrão de nós no cluster (ou seja, dois) só pode acomodar um determinado número de pods.
Nesse ponto, o Karpenter intervém e monitora continuamente a fila de pods pendentes. Ao analisar a situação, o Karpenter inicia o provisionamento de novos nós dentro do cluster.
O dimensionamento horizontal de pods e nós orquestrado por KEDA e Karpenter persistirá até que uma das seguintes condições ocorra:
- O queueLength de destino é atingido (ou)
- O KEDA atinge o MaxReplicaCount (ou)
- O Karpenter encontra os limites de CPU e memória.
Ao eliminar o acúmulo de mensagens no Amazon SQS, a força dessa arquitetura brilha, pois facilita a escalabilidade em ambas as direções:
- Scale-out – lidar proficientemente com atividades pendentes ou
- Scale-in – otimiza a infraestrutura para melhorar a utilização e os benefícios de custo.
Dimensionando para mais de 50 pods e seis nós (ou seja, quatro nós Karpenter):

Scale-out and scale-in
A jornada de escalonamento começa no nível do pod (ou seja, orquestrada pela KEDA) com base no acúmulo de mensagens aguardando processamento e se estende até o Karpenter para garantir que muitos nós estejam disponíveis para hospedar os pods provisionados pela KEDA. O processo de escalabilidade reflete esse padrão. Quando o KEDA percebe que as tarefas pendentes (neste caso, Amazon SQS) estão se aproximando da profundidade de fila desejada, ela inicia um encerramento controlado dos pods aprovisionados. A elegância dessa configuração está na previsão do KEDA: ela não demora até que a profundidade exata da fila seja alcançada, mas mede proativamente o momento ideal para o encerramento do pod, tornando-a altamente eficiente em termos de recursos.
À medida que os pods começam a diminuir, Karpenter acompanha de perto a utilização de recursos nos nós do cluster. Ele pode desligar nós subutilizados, minimizando o desperdício de recursos e reduzindo os custos operacionais.


De volta ao estado padrão, todas as instâncias do Karpenter são encerradas após o evento de escala


Limpeza
Navegue até o diretório raiz do repositório:
cd amazon-eks-scaling-com keda e karpenterPara iniciar a limpeza:
sh ./cleanup.shA execução desse comando remove todos os serviços AWS e cargas de trabalho estabelecidos para essa solução.
Conclusão
Nesta postagem, mostramos que a execução eficiente das aplicações orientadas a eventos no Amazon EKS é substancialmente aprimorada com a integração do KEDA e do Karpenter. O escalonamento automático e meticuloso da KEDA baseado em métricas de eventos, juntamente com o provisionamento oportuno de nós do Karpenter, cria uma estrutura robusta que se destaca em lidar com a natureza dinâmica das cargas de trabalho orientadas a eventos. Essa sinergia supera significativamente os desafios de escalabilidade, garantindo um ambiente responsivo e econômico. A experiência colaborativa do KEDA e do Karpenter no Amazon EKS não apenas simplifica o gerenciamento das aplicações orientadas a eventos, mas também abre caminho para um ecossistema nativo em nuvem escalável, eficiente em recursos e de alto desempenho. Por meio dessa integração, as empresas podem gerenciar com eficácia as cargas de trabalho orientadas a eventos, otimizando a utilização de recursos e garantindo desempenho e economia superiores.
Fique atento às próximas postagens com foco em vários padrões de arquitetura para executar cargas de trabalho de arquitetura orientada a eventos (EDA) no EKS usando o KEDA. Esses próximos insights explorarão e iluminarão ainda mais o potencial e a versatilidade dessa poderosa integração em ambientes nativos da nuvem.
Recursos
Para um mergulho mais profundo no KEDA e no Karpenter, os seguintes recursos são altamente recomendados:
- Repositório de código exibido nesta postagem
- Assista a esta gravação do Youtube de toda a demonstração
- KEDA — Escalonamento automático baseado em eventos baseado em Kubernetes
- KEDA Scalers
- Karpenter — Autoescalador de nós do Kubernetes
- Conceitos de Karpenter
Este blog é uma tradução do contéudo original em inglês (link aqui).
Biografia do Autores
 |
Sanjeev Ganjihal é arquiteto sênior de soluções especializado para container na AWS. A Sanjeev é especializada em Service Mesh, engenharia de plataforma, IA generativa, engenharia rápida, GitOps, IAC, escalonamento automático, otimização de custos e observabilidade. Ele ajuda os clientes a modernizar seus aplicativos fazendo a transição para soluções em container, implementando as melhores práticas da AWS e orientando sua jornada pela transformação da nuvem. Ele está ativamente dedicando tempo a integração da IA com soluções nativas da nuvem, mergulhando nos domínios da IA generativa, da engenharia rápida e do aproveitamento de dados no Kubernetes. Fora do trabalho, ele gosta de jogar críquete e passa o tempo com a família. |
 |
Asif Khan é arquiteto sênior de soluções experiente na equipe empresarial da AWS em Sydney, Austrália. Especializada em atender às necessidades dos principais clientes de varejo. A Asif possui uma rica história em container e Kubernetes, abrangendo perfeitamente várias plataformas de nuvem. Ele possui um talento especial para resolver desafios comerciais complexos por meio de uma fusão de tecnologias proprietárias e de código aberto. Além de suas proezas tecnológicas, Asif valoriza momentos de qualidade com sua amada esposa e dois filhos adoráveis. Asif acredita firmemente na capacidade da tecnologia de oferecer oportunidades iguais para uma vida melhor, onde o acesso é concedido apenas por meio de trabalho árduo, sem qualquer forma de discriminação ou demanda indevida. |
Biografia do Tradutor
 |
Gustavo Carreira é Arquiteto de Soluções sênior na AWS, trabalhando na indústria de FSI. Sua experiência profissional com mais de 10 anos de experiência em Arquitetura e 7 anos com banco de dados relacional e infraestrutura. Atualmente ajuda os clientes na definição e planejamento de diversas soluções corporativas. |
Biografia do Revisor
 |
Daniel Abib é Enterprise Solution Architect na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |
TAGS: Amazon EKS, Amazon SQS, Kapenter