O blog da AWS
Otimizando seus custos de computação em Kubernetes com a consolidação do Karpenter
Introdução
O Karpenter foi criado para resolver problemas relacionados à seleção ideal de worker nodes em Kubernetes. O modelo “o que você precisa, quando precisar” do Karpenter simplifica o processo de gerenciamento de recursos computacionais no Kubernetes, adicionando capacidade computacional ao seu cluster com base nos requisitos de um pod. Com o lançamento da funcionalidade de consolidação de worker node, o Karpenter agora pode monitorar e otimizar continuamente o posicionamento dos pods para melhorar a utilização dos recursos da instância e reduzir seus custos de computação.
Esta postagem explora os recursos de consolidação do Karpenter e mostra o impacto que isso pode ter na otimização dos custos do plano de dados do Kubernetes com um exemplo prático.
Consolidação da carga de trabalho do Karpenter
Nas versões anteriores, o Karpenter só desprovisionava nós de trabalho que estavam sem pods que não fossem daemonset. Com o tempo, à medida que as cargas de trabalho eram reprogramadas, alguns nós de trabalho poderiam ficar subutilizados. A consolidação da carga de trabalho visa consolidar ainda mais a visão do escalonamento automático eficiente e econômico da Karpenter, consolidando as cargas de trabalho no menor número de instâncias e de menor custo, sem deixar de cumprir as restrições de recursos e agendamento do pod. A consolidação da carga de trabalho pode ser habilitada na Definição de Custom Resource Definition (CRD) do Karpenter. Os aprovisionadores são responsáveis pelas ações do ciclo de vida dos worker nodes controlados pelo Karpenter no cluster. Eles permitem que as equipes definam restrições de capacidade, bem como comportamentos (como expiração e consolidação) para os worker nodes lançados.
Quando ativado no Provisioner, o Karpenter monitora continuamente seus workloads no cluster em busca de oportunidades de consolidar a capacidade computacional para melhor utilização dos worker nodes, bem como economia. O Karpenter também respeita todas as restrições de agendamento que você especificou (ou seja, regras pod affinity, restrições de topology spread, etc.). Como o Karpenter cria nodes com base nos requisitos do workload, é importante especificá-los com precisão. Para fazer isso, você deve adicionar a unidade central de processamento (CPU) e as solicitações de memória para seus pods. Isso ajuda a evitar a falta ou o consumo excessivo de recursos, especialmente ao executar várias cargas de trabalho lado a lado no cluster. Além disso, é um requisito importante que o recurso de consolidação da carga de trabalho no Karpenter seja eficaz.
Pré-requisitos
Para executar este exemplo, você precisará configurar o seguinte:
- Provisione um cluster Kubernetes na AWS
- Instale o Karpenter para escalonamento automático de clusters
- Instale o EKS Node Viewer, para visualizar os worker nodes do Amazon Elastic Kubernetes Service (Amazon EKS)
Para automatizar o processo dessa configuração, você pode usar os blueprints do Amazon EKS para Terraform, que tem um exemplo de implantação do Karpenter como um complemento ao seu cluster. Você não precisa modificar o código-fonte do Terraform para executar o exemplo desta postagem.
Provisionadores
O Karpenter controla os worker nodes com base no Custom Resource Definition (CRD) do Provisioner. O Provisioner é um arquivo de configuração responsável por determinar coisas como o tipo de capacidade de computação, tipos de instância, configurações adicionais do kubelet, parâmetros de recursos e outras especificações do ciclo de vida do nó. Você pode implantar vários CRDs em seu cluster, dependendo de seus respectivos usos e desde que não se sobreponham.
Os blueprints do Amazon EKS têm exemplos de provisionadores na pasta examples/karpenter/provisioners. Nesse caso, trabalharemos com um único Provisioner para um aplicativo de exemplo do Node.js chamado express-test. Dessa forma, nenhum pod desse aplicativo não será programado, a menos que seu Provisioner dedicado seja implantado no cluster.
O arquivo Provisioner é fornecido no seguinte código:
Provisionador
Você pode salvar esse arquivo e aplica-lo em seu cluster com o seguinte comando:
Passo a passo
Exemplo de consolidação dos workloads
Nesta seção, implantaremos o aplicativo express-test com várias réplicas, um núcleo de CPU para cada pod e uma restrição de dispersão de topologia zonal. Além disso, o manifesto da carga de trabalho especificará uma regra seletora de nós para que os pods sejam programados para computar recursos gerenciados pelo Provisioner que criamos na etapa anterior. Depois de observar como o Karpenter provisiona o conjunto inicial de nós, modificaremos a implantação atualizando o número de réplicas e acompanharemos a consolidação do Karpenter em resposta a essa mudança.
O manifesto de recursos do aplicativo é especificado no código a seguir.
manifesto do aplicativo
Você pode salvar e aplicar-lo no seu cluster executando o seguinte comando:
Depois disso, podemos visualizar o uso computacional e o custo dos worker nodes do Karpenter usando o eks-node-viewer.

O Karpenter adicionou 3 nós (2 instâncias t3.2xlarge e 1 x c6a.2xlarge) ao nosso cluster que atendem aos requisitos especificados em nosso manifesto, atendendo tanto aos requisitos de computação quanto às restrições de agendamento. Essas são instâncias spot com oito núcleos de CPU, e cada node foi provisionado em uma zona de disponibilidade (AZ) separada, eu-west-1a, eu-west-1b e eu-west-1c. O Karpenter adicionou nodes que respondem pelo único núcleo de CPU que foi solicitado para 20 réplicas (espalhadas por diferentes AZs), junto com o uso da CPU do daemonset e os recursos reservados para o kubelet.
Como você pode ver na captura de tela acima, a ferramenta CLI eks-node-viewer mostra quanto custaria a configuração atual dos nodes por mês.
A próxima etapa é modificar o manifesto de implantação original. Conforme mostrado abaixo, reduziremos o número de réplicas de pods de 20 para 10, o que, por sua vez, reduz a utilização solicitada dos recursos.
manifesto do aplicativo
Você pode aplicar essas alterações executando novamente o comando kubectl apply -f deployment.yaml.
Nesse ponto, nossos nodes estão subutilizados. Anteriormente, o Karpenter adicionou três nodes, cada um com aproximadamente oito CPUs disponíveis, para contabilizar as 20 réplicas. Agora, a única maneira de reduzir o custo do cluster é remover o nó subutilizado. Primeiro, é isolado e depois drenado os pods. Se você continuar monitorando os nodes, notará que essa sequência de eventos ocorre. Por fim, os pods são agendados entre as duas instâncias Spot restantes. Os resultados dessas mudanças podem ser vistos na imagem a seguir.
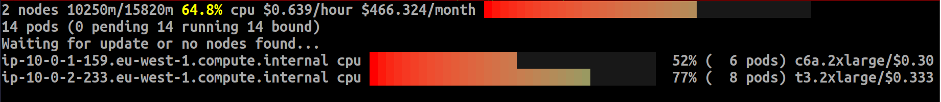
Como mostram os resultados, com a consolidação ativada, a Karpenter otimizou nossos custos de computação em cluster removendo uma das três instâncias, enquanto ainda atendia aos requisitos de recursos definidos e à restrição de distribuição de topologia para nossa carga de trabalho de aplicativos. O custo do plano de dados para essa carga de trabalho foi reduzido conforme mostrado na captura de tela acima.
Para ambientes de produção, é recomendável usar uma ferramenta como o kubecost junto com o Karpenter para monitorar e gerenciar os custos do Kubernetes. Você pode seguir este guia do usuário sobre como configurar o kubecost para monitoramento de custos no Amazon EKS.
Limpeza
Para evitar custos operacionais adicionais, lembre-se de destruir toda a infraestrutura que você criou para os exemplos desta postagem. Primeiro, você precisa excluir os nós criados pelo Karpenter. Eles são gerenciados pelo Provisioner CRD, então você pode excluir esse recurso do seu cluster Kubernetes. Depois disso, você pode excluir o restante da infraestrutura usando o Terraform. Verifique se você está na pasta certa em seu terminal e execute o comando terraform destroy. Você também pode seguir as etapas de limpeza dos projetos do Amazon EKS.
Conclusão
Neste post, mostramos como combinar o novo recurso de consolidação de carga de trabalho do Karpenter e seguir as boas práticas em relação às solicitações de recursos pode ajudar a reduzir seus custos de data plane no Kubernetes.
Aqui estão alguns recursos adicionais sobre o tópico:
Karpenter para Kubernetes | Karpenter vs Cluster Autoscaler
Consolidação do Karpenter no Kubernetes
Para saber mais sobre o Karpenter, leia os documentos e participe do slack channel do comunidade Kubernetes #karpenter.
TAGS: Amazon Elastic Kubernetes Service (Amazon EKS), otimização de custos, Kubernetes
Este artigo foi traduzido do Blog da AWS em Inglês.
Sobre o autor
 Lukonde Mwila é Sênior Developer Advocate na AWS. Ele tem anos de experiência em desenvolvimento de aplicações, arquitetura de soluções, engenharia de nuvem e DevOps workflows. Ele aprende há muito tempo e é apaixonado por compartilhar conhecimento por meio de vários meios. Atualmente, Lukonde passa a maior parte do tempo contribuindo para o Kubernetes e o ecossistema nativo da nuvem
Lukonde Mwila é Sênior Developer Advocate na AWS. Ele tem anos de experiência em desenvolvimento de aplicações, arquitetura de soluções, engenharia de nuvem e DevOps workflows. Ele aprende há muito tempo e é apaixonado por compartilhar conhecimento por meio de vários meios. Atualmente, Lukonde passa a maior parte do tempo contribuindo para o Kubernetes e o ecossistema nativo da nuvem
Tradutor
 Gustavo Carreira é Arquiteto de Soluções sênior na AWS, trabalhando na indústria de FSI. Sua experiência profissional com mais de 10 anos de experiência em Arquitetura e 7 anos com banco de dados relacional e infraestrutura. Atualmente ajuda os clientes na definição e planejamento de diversas soluções corporativas.
Gustavo Carreira é Arquiteto de Soluções sênior na AWS, trabalhando na indústria de FSI. Sua experiência profissional com mais de 10 anos de experiência em Arquitetura e 7 anos com banco de dados relacional e infraestrutura. Atualmente ajuda os clientes na definição e planejamento de diversas soluções corporativas.