- What is Cloud Computing?›
- Cloud Computing Concepts Hub›
- Analytics›
- What Is Data Architecture?
What Is Data Architecture?
Page topics
- What is data architecture?
- What are the components of any data architecture?
- How is data architecture implemented?
- What are the types of data architectures?
- What is a data architecture framework?
- How does data architecture compare to other related terms?
- How can AWS support your data architecture requirements?
What is data architecture?
Data architecture is the overarching framework that describes and governs an organization's data collection, management, and usage. Organizations today have vast data volumes coming in from various data sources and disparate teams wanting to access that data for analytics, machine learning, artificial intelligence, and other applications. Modern data architecture presents a cohesive system that makes data accessible and usable while ensuring data security and quality. It defines policies, data models, processes, and technologies that allow organizations to easily move data across departments and ensure it is available whenever needed—including real-time access—while fully supporting regulatory compliance.
What are the components of any data architecture?
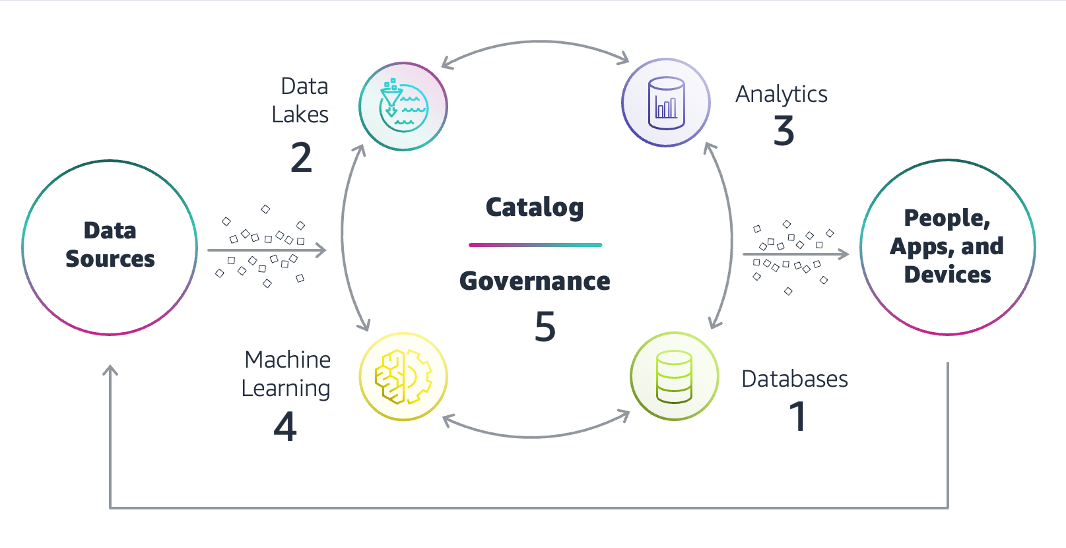
The main data architecture components are given below.
Data sources
Data sources can be customer-facing applications, monitoring and telemetry systems, IoT devices and smart sensors, apps supporting business operations, internal knowledge stores, data archives, third-party data stores, and more. Both structured and unstructured data enter the organization at varying speeds, volumes, and frequencies.
Databases
Purpose-built database systems support modern applications and their different features. They can be relational or non-relational, some storing data as structured tables and others storing unstructured data types as documents or key-value pairs. Databases typically store domain-specific data related to a narrow use case. However, the data can be used beyond the current system. For example, data from a customer-facing app can be used for marketing analytics or planning and needs to be taken out of the database for processing. Similarly, processed data from elsewhere has to be reloaded into the database of an analytics or machine learning (ML) application.
Data lakes
A data lake is a centralized repository for raw data storage at scale. The data architecture describes how data moves from different databases to the data lake and back to different databases as needed for usage. The data lake stores data in a native or open format, allowing for formatting and cleaning before use. It supports data integration and breaks down data silos within an organization.
Data analytics
The data analytics component includes traditional data warehouses, batch reporting, and data streaming technology for real-time alerting and reporting. They can be used for one-time querying and advanced analytics use cases. Analytics are not constrained by data silos because the data architecture opens access and allows more freedom for everyone to use the organization's data assets.
Artificial intelligence
ML and AI are critical for a modern data strategy to help organizations predict future scenarios and build intelligence into applications. Data scientists use data from lakes to experiment, identify intelligence use cases, and train new models. Even after training, AI models require ongoing access to fresh data to generate relevant and useful output. Modern data architectures include all the technology and infrastructure that supports AI model training and inference.
Data governance
Data governance determines roles, responsibilities, and standards for data usage. It outlines who can take what action, upon what data, using what methods, and in what situations. It includes both data quality and data security management. Data architects define processes to audit and track data usage for ongoing regulatory compliance.
Metadata management is an integral part of data governance. Data architecture includes tools and policies to store and share metadata. It outlines mechanisms to provide a central metadata store where disparate systems can store and discover metadata and use it to further query and process data assets.
How is data architecture implemented?
It is a best practice to implement your modern data architecture in layers. The layers group processes and technologies based on distinct objectives. Implementation details are flexible, but the layers guide technology choices and how they should integrate.

Staging layer
The staging layer is the entry point for data within the architecture. It handles raw data ingestion from various sources, including structured, semi-structured, and unstructured formats. You want this layer to be as flexible as possible.
If schema (data formats and types) are enforced rigidly in this layer, downstream use cases get limited. For example, enforcing all date values as a month, year format limits future use cases that require dd/mm/yyyy formatting. At the same time, you want some consistency. For example, if phone numbers are stored as strings and used as such, but some other data source starts generating the same data as numeric, it causes data pipelines to break.
Balancing flexibility with consistency requires you to divide this layer into two sub-layers.
Raw layer
The raw layer stores unaltered data exactly as it arrives, preserving the original format and structure without transformations. It is an enterprise-wide repository for data exploration, auditing, and reproducibility. Teams can revisit and analyze data in its original state when needed, ensuring transparency and traceability.
Standardized layer
The standardized layer prepares raw data for consumption by applying validation and transformations according to predefined standards. For example, in this layer, all telephone numbers would be converted to strings, all time values to specific formats, etc. It thus becomes the interface for all users within the organization to access structured, quality-assured data.
The standardized layer in data architecture is crucial for enabling self-service business intelligence (BI), routine analytics, and ML workflows. It enforces schema standards while minimizing disruptions caused by schema changes.
Conformed layer
Data integration from different sources is completed in the conformed layer. It creates a unified enterprise data model across domains. For example, customer data may have different details in different departments—order details are captured by sales, financial history is captured by accounts, and interests and online activity are captured by marketing. The conformed layer creates a shared understanding of such data across the organization. Key benefits include:
- Consistent, unified definition of core entities across the organization.
- Compliance with data security and privacy regulations.
- Flexibility that balances enterprise-wide uniformity with domain-specific customization through centralized and distributed patterns.
It is not directly used for operational business intelligence but supports exploratory data analysis, self-service BI, and domain-specific data enrichment.
Enriched layer
This layer transforms data from the previous layer into datasets called data products tailored for specific use cases. Data products can range from operational dashboards used for daily decision-making to detailed customer profiles enriched with personalized recommendations or next-best-action insights. They are hosted in various databases or applications chosen based on the specific use case.
Organizations catalog the data products in centralized data management systems for discoverability and access by other teams. This reduces redundancy and ensures that high-quality, enriched data is easily accessible.
What are the types of data architectures?
There are two different approaches to the conformed layer that create different data architecture types.
Centralized data architecture
In centralized data architectures, the conformed layer focuses on creating and managing common entities, like customer or product, that are universally used across the enterprise. The entities are defined with a limited set of generic attributes for easier data management and broad applicability. For example, a customer entity might include core attributes like name, age, profession, and address.
Such data architectures support centralized data governance, especially for sensitive information like personally identifiable information (PII) or payment card information (PCI). Centralized metadata management ensures that data is cataloged and governed effectively, with lineage tracking and lifecycle controls for transparency and security.
However, this model avoids including all possible attributes, as centrally managing complex data requirements slows down decision-making and innovation. Instead, domain-specific properties, such as customer campaign impressions(only required by marketing), are derived in the enriched layer by respective business units.
Data fabric technologies are useful in implementing centralized data architectures.
Distributed data architecture
Each domain creates and manages its own conformed layer in distributed data architectures. For example, marketing focuses on attributes like customer segments, campaign impressions, and conversions, while accounting prioritizes properties such as orders, revenue, and net income.
Distributed data architectures allow flexibility in defining entities and their properties but result in multiple datasets for common entities. Discoverability and governance of these distributed datasets are achieved through a central metadata catalog. Stakeholders can find and use the appropriate dataset while overseeing data exchange processes.
Data mesh technologies are useful in implementing distributed data architectures.
What is a data architecture framework?
A data architecture framework is a structured approach to designing data architecture. It provides a set of principles, standards, models, and tools that ensure efficient data management processes aligned with the organization's business objectives. You can think of it as a standard blueprint that a data architect uses to build high-quality and comprehensive data architectures.
Some examples of data architecture frameworks include
The DAMA-DMBOK framework
The Data Management Body of Knowledge (DAMA-DMBOK) framework outlines best practices, principles, and processes for effective data management across its lifecycle. It supports establishing consistent data management practices while ensuring alignment with business goals. By treating data assets as a strategic resource, DAMA-DMBOK provides actionable guidance for improving decision-making and operational efficiency.
The Zachman framework
The Zachman framework is an enterprise architecture framework that uses a matrix format to define the relationships between different perspectives (such as business owner, designer, and builder) and six key interrogatives (What, How, Where, Who, When, and Why). Organizations can visualize how data fits within their overall operations, ensuring that data-related processes align with business objectives and system requirements. The Zachman framework is widely recognized for its ability to bring clarity to enterprise-wide data and system dependencies.
TOGAF
The Open Group Architecture Framework (TOGAF) treats data architecture as a critical component of a broader system, emphasizing the creation of data models, data flows, and governance structures that support organizational needs. It establishes standardized data processes, ensuring system interoperability and efficient data management. It is particularly beneficial for large enterprises looking to align their IT and business strategies through a unified approach.
How can AWS support your data architecture requirements?
AWS provides a comprehensive set of analytics services for every layer of your data architecture—from storage and management to data governance and AI. AWS offers purpose-built services with the best price-performance, scalability, and lowest cost. For example,
- Databases on AWS include over 15 purpose-built database services to support diverse relational and non-relational data models.
- Data lakes on AWS include services that provide unlimited raw data storage and build secure data lakes in days instead of months.
- Data integration with AWS includes services that bring together data from multiple sources so you can transform, operationalize, and manage data across your organization.
AWS Well-Architected helps cloud data architects build secure, high-performing, resilient, and efficient infrastructure. AWS Architecture Center includes use case based guidelines for implementing various modern data architectures in your organization.
Get started with data architecture on AWS by creating a free account today.