Artificial Intelligence
Category: AWS Glue

Build a serverless AI Gateway architecture with AWS AppSync Events
In this post, we discuss how to use AppSync Events as the foundation of a capable, serverless, AI gateway architecture. We explore how it integrates with AWS services for comprehensive coverage of the capabilities offered in AI gateway architectures. Finally, we get you started on your journey with sample code you can launch in your account and begin building.

Advancing ADHD diagnosis: How Qbtech built a mobile AI assessment Model Using Amazon SageMaker AI
In this post, we explore how Qbtech streamlined their machine learning (ML) workflow using Amazon SageMaker AI, a fully managed service to build, train and deploy ML models, and AWS Glue, a serverless service that makes data integration simpler, faster, and more cost effective. This new solution reduced their feature engineering time from weeks to hours, while maintaining the high clinical standards required by healthcare providers.
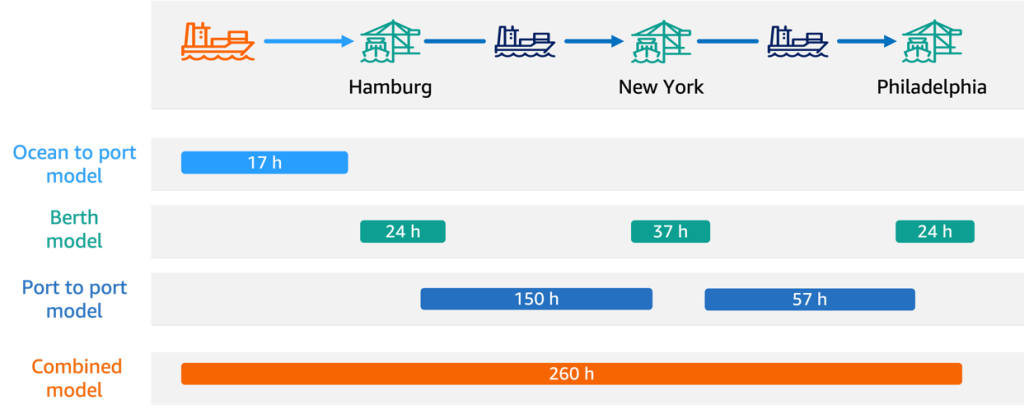
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.
Natural language-based database analytics with Amazon Nova
In this post, we explore how natural language database analytics can revolutionize the way organizations interact with their structured data through the power of large language model (LLM) agents. Natural language interfaces to databases have long been a goal in data management. Agents enhance database analytics by breaking down complex queries into explicit, verifiable reasoning steps and enabling self-correction through validation loops that can catch errors, analyze failures, and refine queries until they accurately match user intent and schema requirements.

Build conversational interfaces for structured data using Amazon Bedrock Knowledge Bases
This post provides instructions to configure a structured data retrieval solution, with practical code examples and templates. It covers implementation samples and additional considerations, empowering you to quickly build and scale your conversational data interfaces.

How Rocket Companies modernized their data science solution on AWS
In this post, we share how we modernized Rocket Companies’ data science solution on AWS to increase the speed to delivery from eight weeks to under one hour, improve operational stability and support by reducing incident tickets by over 99% in 18 months, power 10 million automated data science and AI decisions made daily, and provide a seamless data science development experience.

How Formula 1® uses generative AI to accelerate race-day issue resolution
In this post, we explain how F1 and AWS have developed a root cause analysis (RCA) assistant powered by Amazon Bedrock to reduce manual intervention and accelerate the resolution of recurrent operational issues during races from weeks to minutes. The RCA assistant enables the F1 team to spend more time on innovation and improving its services, ultimately delivering an exceptional experience for fans and partners. The successful collaboration between F1 and AWS showcases the transformative potential of generative AI in empowering teams to accomplish more in less time.

Super charge your LLMs with RAG at scale using AWS Glue for Apache Spark
In this post, we will explore building a reusable RAG data pipeline on LangChain—an open source framework for building applications based on LLMs—and integrating it with AWS Glue and Amazon OpenSearch Serverless. The end solution is a reference architecture for scalable RAG indexing and deployment.

Intelligent healthcare forms analysis with Amazon Bedrock
In this post, we explore using the Anthropic Claude 3 on Amazon Bedrock large language model (LLM). Amazon Bedrock provides access to several LLMs, such as Anthropic Claude 3, which can be used to generate semi-structured data relevant to the healthcare industry. This can be particularly useful for creating various healthcare-related forms, such as patient intake forms, insurance claim forms, or medical history questionnaires.

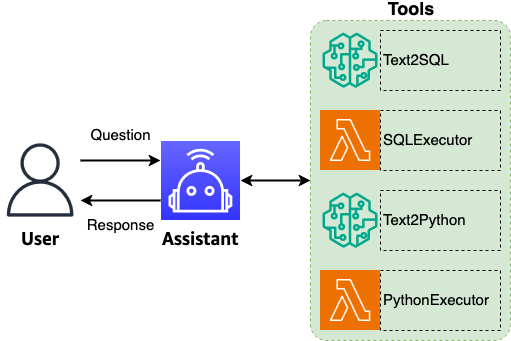
Build a robust text-to-SQL solution generating complex queries, self-correcting, and querying diverse data sources
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. The solution in this post aims to […]