亚马逊AWS官方博客
宣布推出 Amazon SageMaker Canvas — 面向业务分析师的可视化、无代码机器学习功能
作为一个每天面对业务问题并和数据打交道的组织,构建可以预测业务结果的系统的能力变得非常重要。这种能力通过自动执行缓慢的流程并在 IT 系统中嵌入智能,让您可以解决问题并加快行动速度。
但是,如何确保组织中的所有团队和个人决策者都能够在不依赖其他数据科学和数据工程团队的情况下大规模创建这些机器学习 (ML) 系统? 作为业务用户或数据分析师,您希望基于每天分析和处理的数据来构建和使用预测系统,而无需了解数百种算法、训练参数、评估指标和部署最佳实践。
我很高兴地宣布 Amazon SageMaker Canvas 正式上市,这是一种新的可视化、无代码功能,使业务分析师可以构建机器学习 (ML) 模型并生成准确的预测,而无需编写代码或机器学习 (ML) 专业知识。其直观的用户界面让您可以浏览和访问云端或本地的不同数据源,通过单击按钮组合数据集,训练准确的模型,然后在新数据可用时立即生成新的预测。
SageMaker Canvas 利用与 Amazon SageMaker 相同的技术来自动清理和组合您的数据,在幕后创建数百个模型,选择性能最佳的模型,并生成新的单个或批量预测。它支持二元分类、多类分类、数值回归和时间序列预测等多种问题类型。这些问题类型让您无需编写任何代码即可处理业务关键型使用案例,例如欺诈侦测、减少客户流失和库存优化。
SageMaker Canvas 的实际操作
想象一下,我是一名电子商务经理,需要预测产品是否会按时发货。我可以使用的数据集包括产品目录和历史运输数据集,它们都以 CSV 格式提供。
首先,进入 SageMaker Canvas 应用程序,在其中创建和检查我的所有模型和数据集。
![]()
选择导入,然后上传两个 CSV 文件:ProductData.csv 和 ShippingData.csv。我有 120 件产品和 10,000 条发货记录。


我还可以从 Amazon Simple Storage Service (Amazon S3) 获取数据或连接到其他云中或本地的数据源,例如 Amazon Redshift 或 Snowflake。对于此使用案例,我偏向于直接从计算机上载 1.6 MB 的数据。
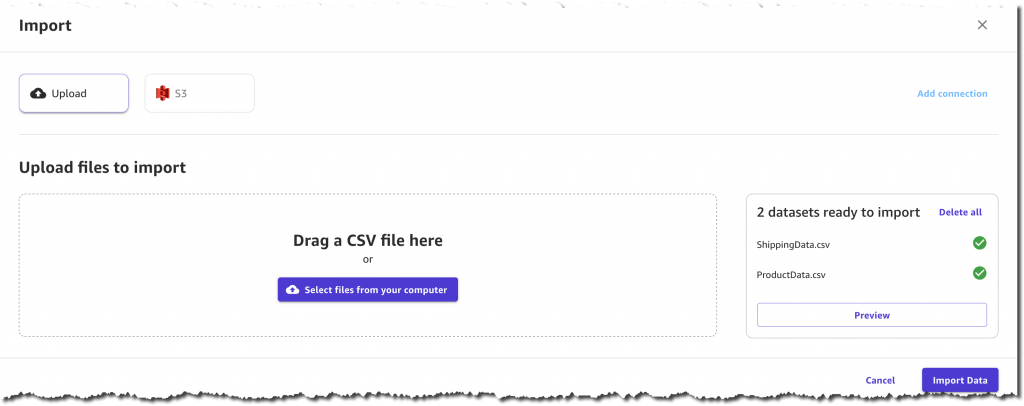
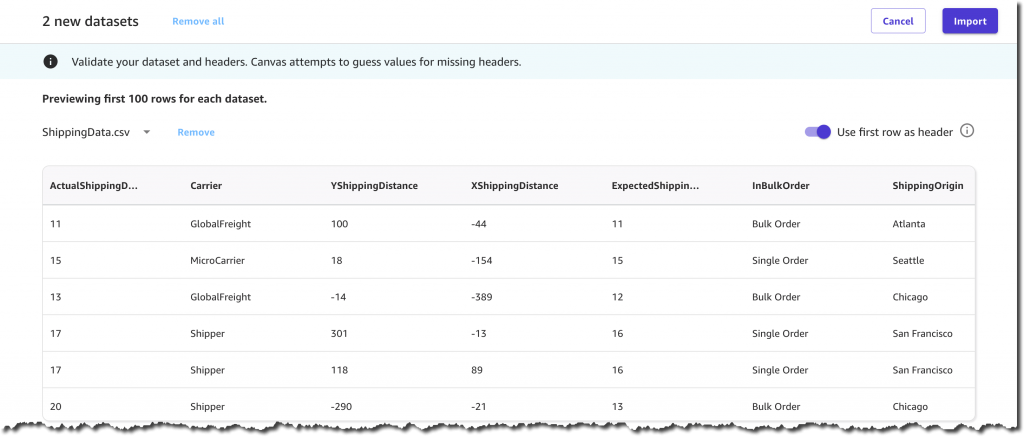
在确认导入之前,我有机会预览两个数据集、它们的列和它们各自的值。例如,每个产品都有一个 ComputerBrand、ScreenSize 和 PackageWeight。除了诸如 ShippingOrigin、OrderDate 和 ShippingPriority 等有用的列之外,运输数据集中的每条记录还包含 OnTimeDelivery,即 On Time 或 Late。SageMaker Canvas 将使用此列,根据历史数据生成预测模型。
经过几秒钟的处理后,数据集准备就绪,我决定联接它们以创建包含产品和运输信息的单个数据集。这是一个可选步骤,通常可以让您提高预测模型的精度。
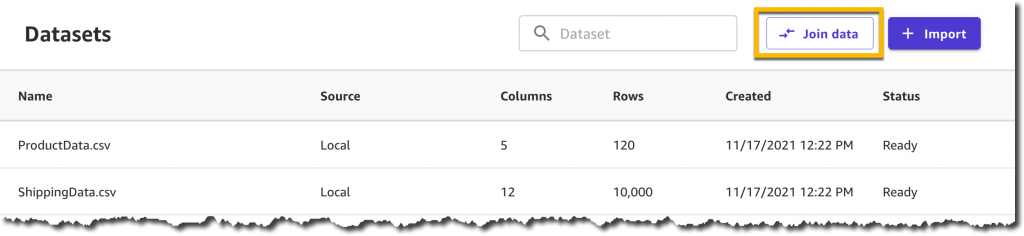
现在,我只需拖放两个数据集:SageMaker Canvas 将自动识别共享的 ProductId 列并应用内部联接转换。
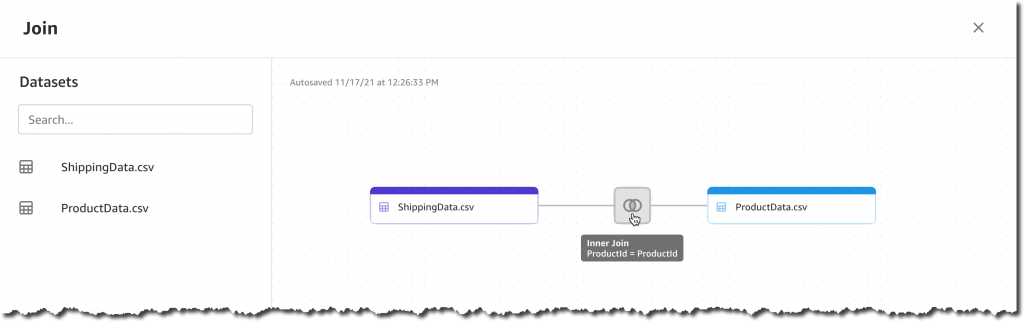
通过联接预览,我可以直观显示结果列、识别缺失值或无效值,并可选择取消选择不需要的列。

我选择保存联接数据并为该联接数据集提供一个新名称,它现在包括 16 列和 10000 条记录。
接下来,我想创建一个模型:首先在左侧菜单的模型部分中选择新建模型。我称之为准时预测模型。
第一步是选择一个数据集。
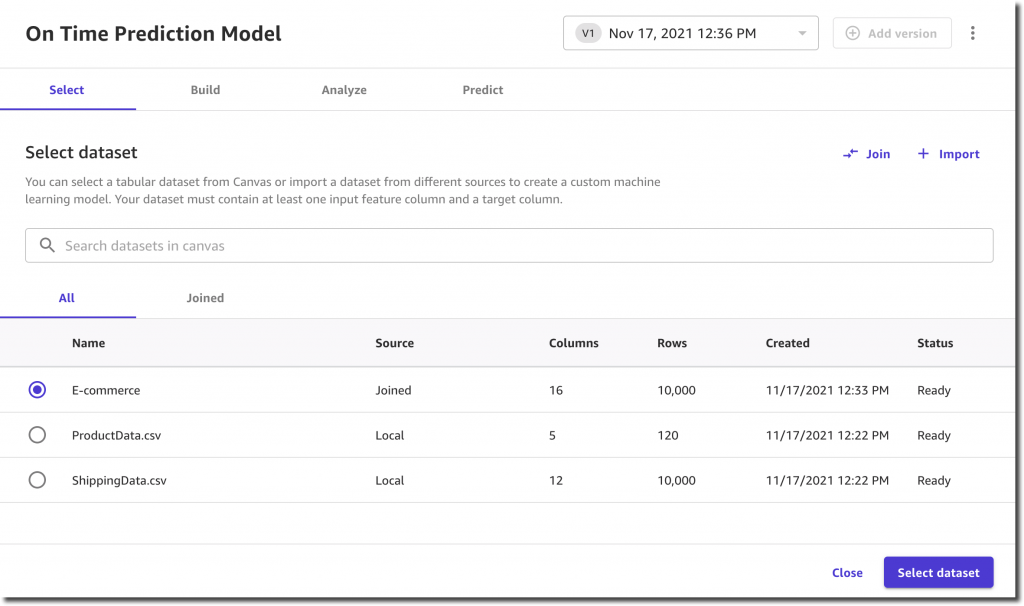
我选择了我的模型将预测的目标列:OntimeDelivery。
SageMaker Canvas 向我展示了值的分布情况,并且已经推荐了最合适的模型类型:两类分类。

在继续模型训练之前,我可以选择生成分析报告。这个分析给了我两个非常重要的信息:估计的准确度和每列的影响。

99.9% 的估计准确率让我充满信心,但随后我注意到 ActualShippingDays 列产生的影响最大。遗憾的是,此列无法提前获得,我无法将其用于我的预测。所以我取消选择它并再次运行分析。

新的估计准确率为 94.2%,仍然相当高。影响最大的列是 ShippingPriority、YShippingDistance、XShippingDistance 和 Carrier。这很棒,因为所有这些信息都可以提前获得,并且可以用于预测。另一方面,与产品相关的列(例如 PackageWeight 和 ScreenSize)对预测的影响非常小。这意味着将来我可以通过仅将运输信息输入到训练和预测阶段来简化整个流程。
我对分析见解感到满意。因此,我决定通过选择标准构建选项来继续构建预测模型。
现在我可以出去散散步,参加一些富有成效的会议,或者只是陪陪家人。SageMaker Canvas 将为我完成所有工作,在幕后训练数百个模型。它将选择表现最出色的一个,以便我可以开始在几个小时内生成准确的预测。当然,训练时长会因数据集大小和问题类型而异。
大约一个半小时后,模型准备就绪,我可以通过控制台直观地分析其准确性和各列的影响。我也很高兴看到该模型在 95.8% 的时间预测了正确的值,甚至高于预计的准确率。
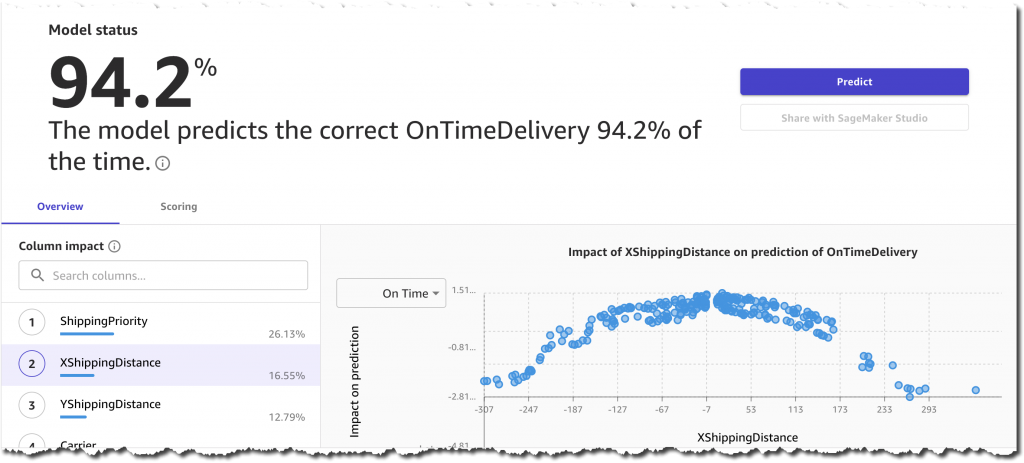
我还可以根据需要检查高级指标,例如精确度、召回率、F1 得分等。这些指标可以帮助我了解模型的表现以及该模型可能会出现哪种误报和漏报。

从这里,我可以将模型共享到 Amazon SageMaker Studio 或继续使用 Canvas UI 来生成新的预测。
我决定继续使用直观的 UI,并且选择了预测。现在我可以使用单个记录或使用数据集进行批量预测。
选择单一预测时,SageMaker Canvas 简化了操作,让我可以从现有记录开始。我修改列值并立即获得有关预测和相应功能重要性的反馈。

这种快速的反馈循环和直观的 UI 使我无需编写自定义代码即可使用机器学习 (ML) 模型。如果我决定将模型集成到自动化生产系统中,Amazon SageMaker Studio 集成可以让我可以轻松地与团队中的其他数据科学家共享模型。
现已正式推出
SageMaker Canvas 现已在美国东部(俄亥俄)、美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、欧洲(法兰克福)和欧洲(爱尔兰)正式发布。您可以开始将它与本地数据集以及已存储在 Amazon S3、Amazon Redshift 或 Snowflake 上的数据一起使用。只需单击几下,就可以准备并联接数据集、分析估计的准确率、验证哪些列具有影响力、训练性能最佳的模型并生成新的单个或批量预测。我们很高兴听取您的反馈并帮助您使用机器学习 (ML) 解决更多业务问题。
— Alex