亚马逊AWS官方博客
基于 Amazon SageMaker Canvas 无代码构建分类模型
前言:
如果想要让机器学习有效赋能企业的每个部门,就要把机器学习的能力交到每一个企业角色手中。试想您是一位银行的业务分析师,需要根据历史数据来预测客户是否会办理长期存款业务,但是您在机器学期和代码方面的经验都非常有限,这个时候您就可以使用Amazon SageMaker Canvas,他具有以下优点:
-
无需编写代码即可生成 ML 预测:
Amazon SageMaker Canvas是一款无代码、可视化的机器学习工具。通过为业务分析师提供可视化的点击式界面来扩展对机器学习 (ML) 的访问,使他们能够自行生成准确的 ML 预测,而无需任何机器学习经验或编写任何代码。
-
快速访问和准备数据以实现 ML:
借助 SageMaker Canvas,您可以快速连接和访问来自云和本地数据源的数据、组合数据集并创建统一的数据集以训练 ML 模型。SageMaker Canvas 会自动检测和纠正数据错误并分析 ML 的数据准备情况。
-
使用内置 AutoML 生成预测:
SageMaker Canvas 使用来自 Amazon SageMaker 的强大 AutoML 技术,根据您的独特用例自动创建 ML 模型。 这使 SageMaker Canvas 能够根据您的数据集确定最佳模型,以便您生成准确的预测 — 无论是单个预测还是批量预测。
-
与数据科学家一起验证 ML 模型:
SageMaker Canvas 与 Amazon SageMaker Studio 集成,使业务分析师可以更轻松地与数据科学家共享模型和数据集,以便他们验证和进一步优化 ML 模型。
在本篇博客中,我们将会以银行业务分析的场景为例,用Amazon SageMaker Canvas来构建预测用户是否会办理存款业务的二分类模型,并将最终生成的模型结果分享到Amazon SageMaker Studio。本示例将使用开源数据集bank.csv(https://archive.ics.uci.edu/ml/datasets/bank+marketing),其中包含16个特征和一个二分类目标值。同时我们也将使用bank-full.csv的前199行作为预留的测试数据。
示例:
- 创建SageMaker Domain: 登陆Amazon SageMaker控制台,在左栏中选择SageMaker Domain。选择Quick setup,在User profile里填写Domain的名字并创建Execution Role,然后选择Submit。

- 选择我们刚刚创建的Domain,在Launch下拉菜单中选择Canvas。

- 选择New model并创建一个新的模型。

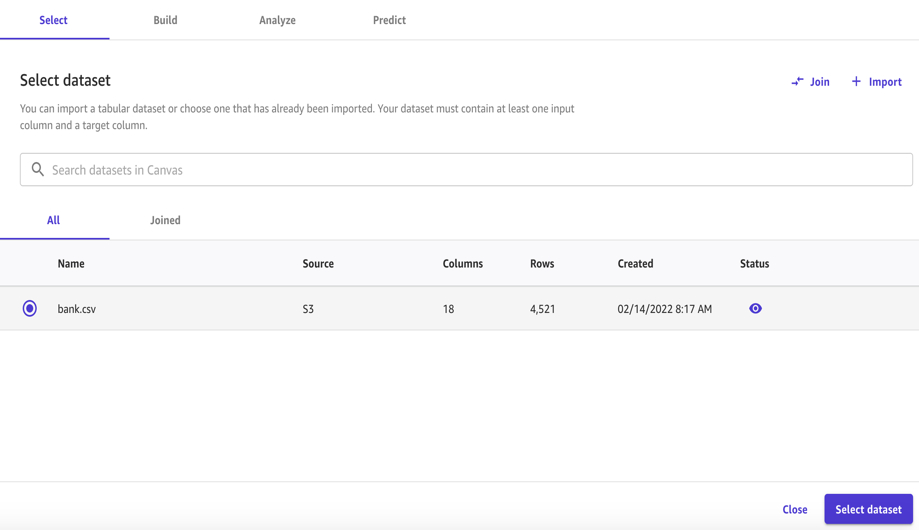
- 在Select下加载S3上清理过的数据集。SageMaker Canvas 支持 CSV、XLSX 和 Parquet 文件类型,并且能够发现您的账户有权访问的 AWS 数据源,包括 Amazon Simple Storage Service (S3) 和 Amazon Redshift。您也可以从本地磁盘拖放文件,并使用预构建的连接器从第三方源(如 Snowflake)导入数据。此外,您还可以使用连接操作来连接多个来源的数据,并为训练预测模型创建新的统一数据集。例如,您可以将 Amazon Redshift 中包含客户 ID 的交易数据与 Amazon S3 中包含客户资料数据的 CSV 表联接起来,从而创建新的数据集。在 SageMaker Canvas 可视化界面中,您可以验证数据是否已正确导入、了解平均值和中位数,并确定数据中是否存在缺失值。您还可以分析数据并识别数据集中列之间的相关性。

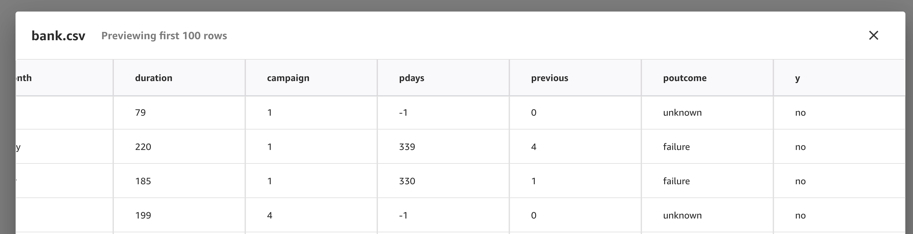
点击数据集,我们也可以预览前一百行的数据。确认之后选择Import data加载数据集,接着选择Select dataset来使用该数据集作为建模的源数据。
- 在Build下配置我们的模型需求。

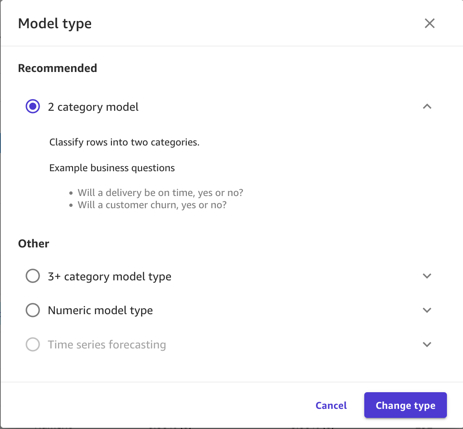
首先在Select a column to predict中选择我们的目标值y。

然后在Model type中选择2 category prediction(二分类模型)。除了二分类模型,SageMaker Canvas还支持线性回归模型,多分类模型以及时序预测模型。
接着我们可以在下方的预览中查看到每一个特征值的,是否存在缺失值以及与目标值的相关性,并根据需要进行特征值或特征组合的筛选。通过查看特征分布,我们可以查看特征是否存在偏移和不均衡的问题。Amazon Canvas可以自动识别数据中的缺失值并用相邻值进行填补。通过结合业务逻辑和与目标值的相关性,我们可以初步选定特征组合。



与此同时,我们还可以通过选择Preview model快速预测当前配置下模型的效果并查看每一个特征的影响力,从而实现动态交互优化。
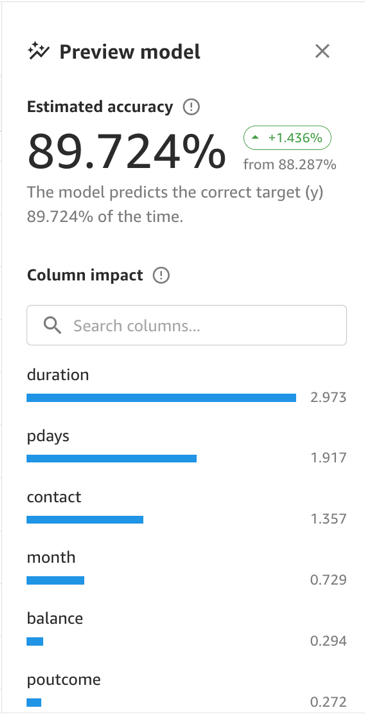
从上面结果我们可以看出,duration(与客户上次交流的时间),pdays(距离上次与客户交流的时间)以及contact(与客户交流的方式:固化或移动电话)是影响力最大的三个特征。default和day对结果影响较小。age虽然与目标值有想对较强的相关性,但是添加之后整体预测准确性会有所下降,很可能是冗余特征。因此,我们最终使用去除掉default,day和age的特征组进行建模。
- 在选定特征组合之后我们就可以开始构建模型了。SageMaker Canvas可以自动完成数据清洗,构建最多250个模型,并从中选取最优的模型。我们可以选择Quick build或者Standard build两种模式训练模型:Quick build通常只需要2-15分钟;而Standard build则需要2-4个小时,但是可以提供更高准确率并能一键分享给SageMaker Studio。实际训练过的模型精度理论上要高于我们前面预测的效果。

- 在模型训练好之后我们可以得到一个比较详细的可视化报告。我们可以在Overview中查看到根据SHAP(https://towardsdatascience.com/shap-explained-the-way-i-wish-someone-explained-it-to-me-ab81cc69ef30)计算的每一个特征的重要性(Column Impact)。也可以在Scoring中看到模型在验证集上的表现并通过点击Scoring里面Advanced metrics来查看混沌矩阵并得到包括Recall和AUC在内的更多业务指标。我们还可以点击Download下载这份可视化报告。从结果上我们看到经过训练的模型准确率863%确实高于之前预测的89.724%。如果想尝试更多的特征组合,点击Add version我们就可以使用同一数据集创建新的模型版本。
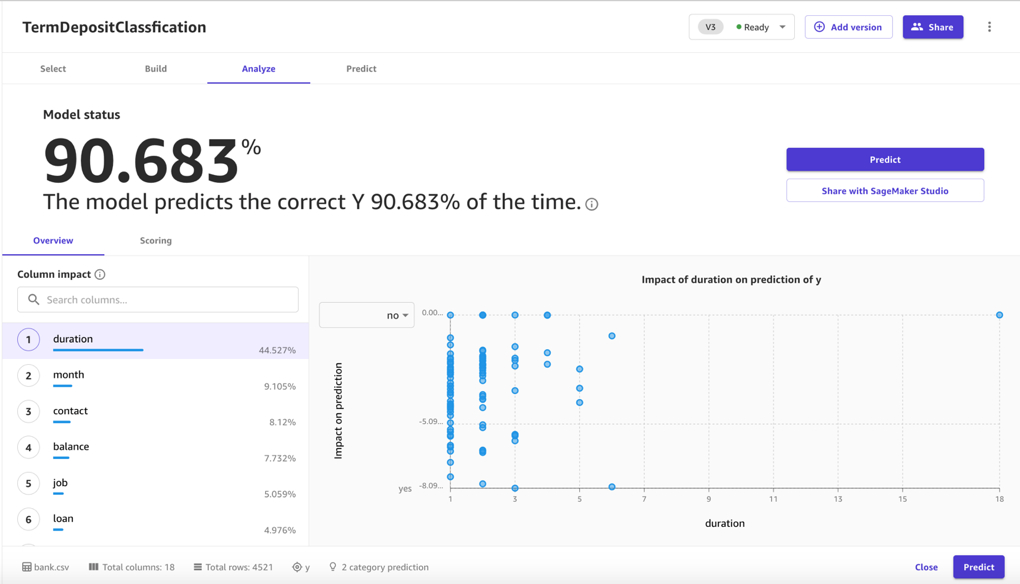


- 我们还可以用训练好的模型进行单点(Single prediction)或者批量(Batch Prediction)的推理测试。这边我们使用预留的测试数据集进行批量推理。这边我们可以看到每一条特征组对应的预测结果和概率,同时也可以选择下载整个推理结果的表格。在单点测试中我们还可以通过调节每个特征值动态观察预测结果的变化。



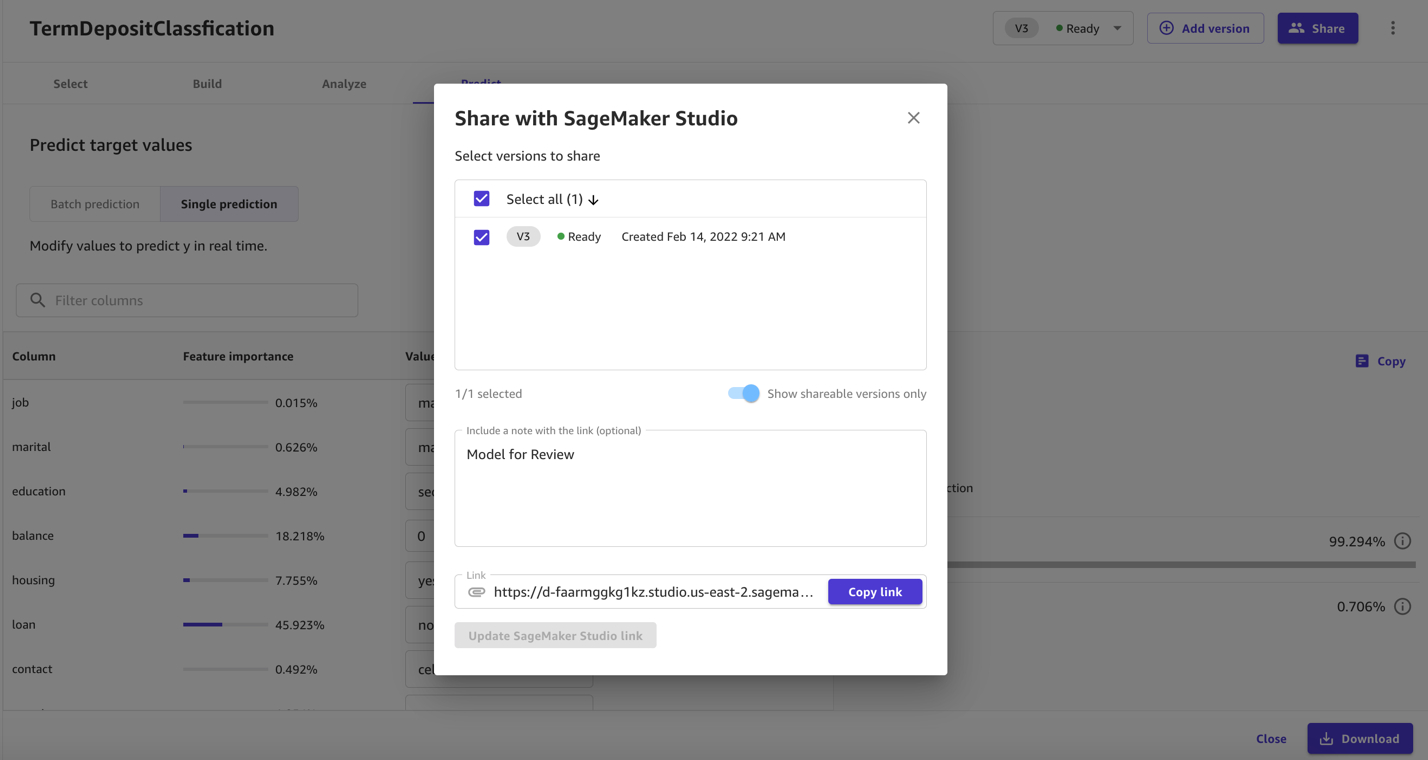
- 最后,我们还可以将模型和数据集分享给SageMaker Studio进行进一步的模型优化和生产部署。通过点击Share,我们可以生成分享链接。打开该链接,我们可以跳转到Amazon SageMaker Studio的界面。

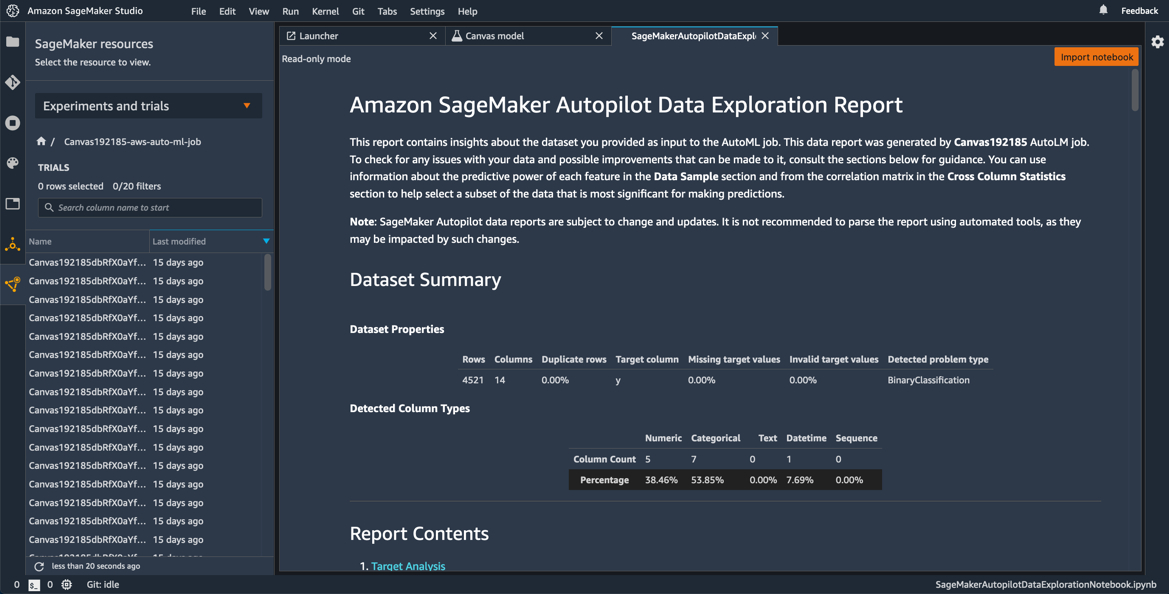
- 在Amazon SageMaker Studio中我们可以查看模型的配置参数并得到记录SageMaker Canvas中数据处理和构建模型操作的两个Jupyter notebook:通过点击Input Dataset中Open data exploration notebook,对数据清洗和特征筛选部分的代码进行修改;我们也可以点击Auto ML Job中的Open candidate generation notebook,在任务对应的笔记本中对模型训练部分代码进行优化。