亚马逊AWS官方博客
无代码机器学习:AutoGluon、Amazon SageMaker 与 AWS Lambda 合力加持 AutoML
AWS的一大核心目标,就是将机器学习(ML)能力交付至每一位开发人员手中。借助由Amazon SageMaker与AWS Lambda部署的开源AutoML库AutoGluon,我们得以更进一步,将ML能力交付至每一位希望根据数据做出预测的用户手中。无需任何编程或数据科学专业知识,AutoGluon真正实现了ML解决方案的开箱即用目标。
AutoGluon能够自动为实际应用程序当中的图像、文本与表格类数据集提供ML处理能力。AutoGluon训练出多套ML模型,能够基于当前观察中的各项特征值,对指定特征值(即目标值)做出预测。在训练期间,模型将预测目标值与训练数据中的实际目标值进行比较,借此不断提升自身预测能力,同时配合适当算法相应改善预测准确率。在训练完成之后,即使你不了解的实际目标值,模型也能够通过未观察过的特征值给出特征值预测。
AutoGluon会自动应用多种技术,通过调用单一高级API对数据进行训练,大家无需亲自动手构建模型。基于用户配置的评估指标,AutoGluon将自动选择性能最高的模型组合。关于AutoGluon工作原理的更多详细信息,请参阅使用AutoGluon(一套开源AutoML库)实现机器学习。
要了解如何使用AutoGluon,请参阅 AutoGluon GitHub repo。关于在应用程序中使用其他更复杂的AutoML解决方案的详细信息,请参阅AutoGluon网站。Amazon SageMaker是一项全托管服务,旨在为每一位开发人员及数据科学家提供高效构建、训练及部署ML模型的能力。AWS Lambda则帮助您在无需配置或管理服务器的前提下运行代码,通过Amazon Simple Storage Service (Amazon S3)等其他AWS服务自动触发相应函数,并以此为基础构建起各类实时数据处理系统。
使用AutoGluon,大家只需要三行Python代码即可结合当前观察结果实现出色的预测性能。在本文中,我们将使用AWS服务部署一套完整管道,用以训练ML模型并通过AutoGluon对表格数据进行预测。整个流程无需任何代码,因此非开发人员也能够享受到AutoML类解决方案的强大功能。将这条管道部署至AWS账户中之后,大家只需将数据上传至附带AutoGluon软件包的S3存储桶内,即可对其进行高准确率预测。
无代码ML管道
这条管道从S3存储桶起步,大家可以在其中上传供AutoGluon用于模型构建的训练数据,待预测的测试数据,以及配置AutoGluon的脚本等预制软件包。在将数据上传至Amazon S3之后,Lambda函数将启动Amazon SageMaker模型的训练作业,由该作业以训练数据为基础运行预置的AutoGluon脚本。训练作业结束之后,AutoGluon将挑选出性能最佳的模型对测试数据进行预测,并将预测结果保存至同一S3存储桶内。下图所示,为此管道的基本架构。
使用AWS CloudFormation部署管道
大家可以使用预制AWS CloudFormation模板,自动在AWS账户当中部署本文中的示例。具体操作步骤如下:
- 选择要进行模板部署的目标AWS区域。如果您希望将模板部署至其他区域,请从GitHub处下载此模板,而后将其手动上传至CloudFormation。
| 北弗吉尼亚州 | Launch Stack |
| 俄亥俄州 | Launch Stack |
| 爱尔兰 | Launch Stack |
| 悉尼 | Launch Stack |
- 登录至AWS管理控制台。
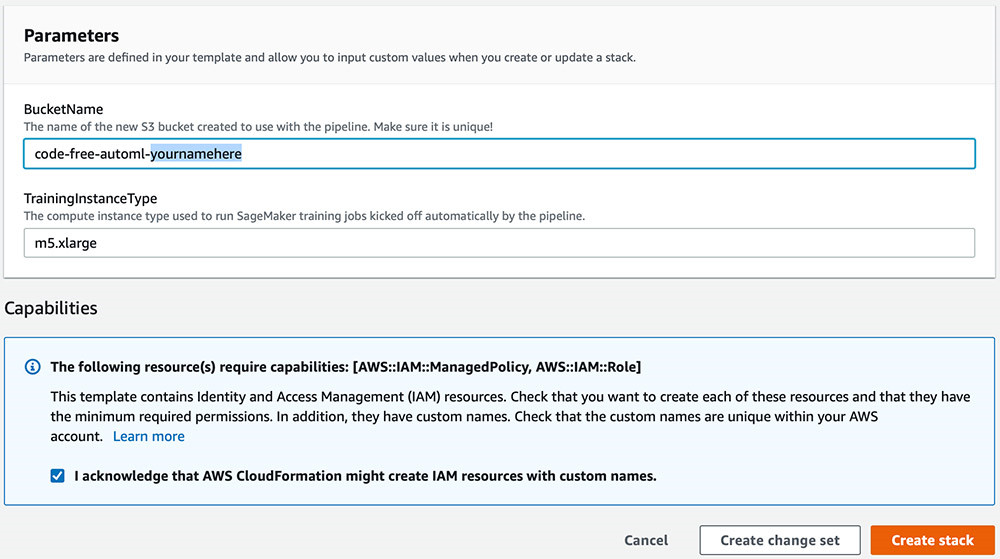
- 在Stack name部分,为您的Stack输入名称(例如,
code-free-automl-stack)。 - 在BucketName部分,为S3存储桶输入唯一名称(例如,
code-free-automl-yournamehere)。 - 在TrainingInstanceType部分,输入您的计算实例。
此参数负责控制Amazon SageMaker模型训练作业在数据之上所运行的具体AutoGluon实例类型。AutoGluon针对m5实例类型进行了优化,且AWS Free Tier免费套餐中提供长达50小时的免费m5.xlarge实例Amazon SageMaker训练时长。我们建议您从免费套餐入手,根据初始工作的所需时间以及获取结果的速度要求,对实例类型进行具体调整。
- 选择IAM创建确认复选框,而后选择Create stack。

- 根据AWS CloudFormation向导程序继续推进,直至来到Stacks页面。


AWS CloudFormation需要一段时间创建所需的所有资源。当状态显示为CREATE_COMPLETE(可能需要刷新页面)时,即代表示例管道已经可以使用。
- 要查看架构中的所有组件, 请选择Resources选项卡。
- 要导航至我们的S3存储桶,请选择对应链接。


在使用管道之前,我们还需要将预制的AutoGluon软件包上传至新的S3存储桶内。
- 在存储桶内创建一个名为
source的文件夹。
- 将tar.gz 软件包上传至该文件夹中,保持全部默认设置。



现在,我们的管道就部署完成了!
准备训练数据
要准备训练数据,请返回存储桶的根目录位置(您将在这里看到源文件夹),并创建一个名为 data的新目录。所有训练数据都将被上传到这里。
接下来,收集用于模型学习的数据(即训练数据)。此管道旨在对表格数据进行预测,而表格数据也是现实应用程序当中最常见的数据类型。大家可以将其理解成电子表格,各列代表变量(即特征值)的数值,而各行代表一个独立的数据点(观察)。
对于每一条观察,我们的训练数据集必须包含用于解释特征的列,与有待模型做出预测的特征值所归属的行。
将训练数据保存至名称为 <Name>_train.csv的CSV文件,其中的〈Name〉部分可以随意替换。
请确保将所有目标列的标题名称(即该列中第一行的值)设置为target,这样AutoGluon才能正确识别到对应位置。具体参见以下截屏中的示例数据集。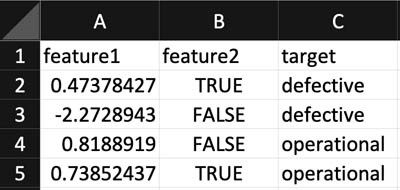
准备测试数据
我们还需要提供预测所需要的测试数据。如果此数据集已经包含目标列的值,则可以将这些实际值与模型的预测值进行比较,借此评估模型的预测质量。
将测试数据集保存到名为<Name>_test.csv的另一CSV文件当中,将其中的〈Name〉部分替换为您所选定的对应训练数据。
确保当前列名与 <Name>_train.csv的列名相匹配,其中目标列 target的名称也应保证匹配(如果存在)。
将 <Name>_train.csv 与 <Name>_test.csv 文件上传至我们之前在S3存储桶内创建的数据文件夹内。
上传完成之后,我们的这条无代码ML管道就将自动启动。
训练模型
在将训练与测试数据集文件上传至Amazon S3时,AWS会记录这一事件并自动触发Lambda函数。此函数将启动Amazon SageMaker的训练作业,使用AutoGluon对ML模型组合进行训练。大家可以在Amazon SageMaker控制台的Training jobs部分查看作业的当前状态(如以下截屏所示)。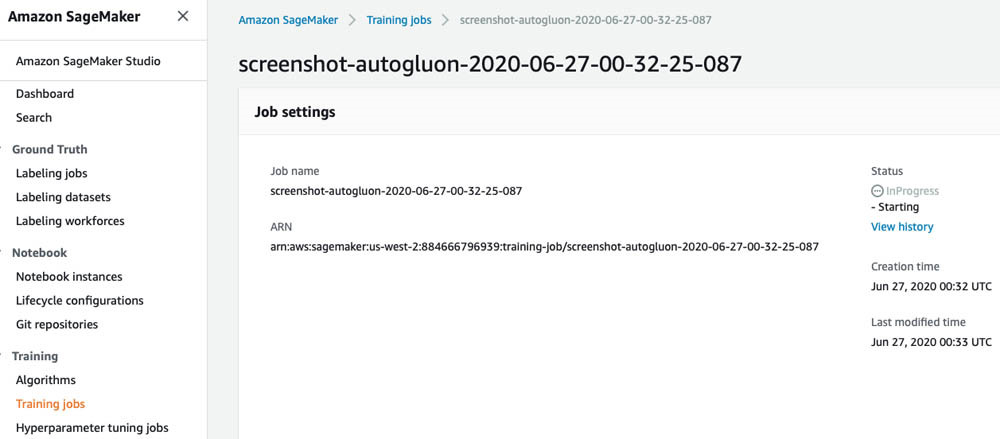
执行推理
训练作业完成之后,AutoGluon将使用具有最佳性能的模型或模型的加权组合(由AutoGluon判定)计算测试数据集内各项观察目标的预测值。这些预测结果将会自动以 <Name>_test_predictions.csv文件名的形式存储在S3存储桶的results目录当中。
AutoGluon还能够生成其他实用的输出文件,例如 <Name>_leaderboard.csv (由AutoGluon训练的各模型的排名及其预测性能) 以及 <Name>_model_performance.txt (最佳性能模型相对应的扩展衡量列表)。所有文件都可以从Amazon S3控制台下载至本地计算机当中(详见以下截屏)。
扩展
由AutoGluon训练得出的最佳性能模型物件,也将被保存在输出文件夹当中(详见以下截屏)。
大家也可以扩展本文的解决方案,可以将训练完成的模型部署为Amazon SageMaker的推理端点,借此对新数据进行实时预测;也可以运行Amazon SageMaker批处理转换作业对其他测试数据文件进行离线预测。关于更多详细信息,请参阅如何使用现有模型数据与训练作业。
大家还可以通过替换掉源文件夹中预置的Auto Gluon sourcedir.tar.gz软件包,使用您的自定义模型代码复用我们的这套自动化管道。解压缩现有软件包并查看其中的Python脚本,大家会发现其实是很简单的,只是单纯在数据上运行AutoGluon。我们可以对其中的参数定义做出调整,从而更好地匹配实际用例。此脚本,以及设置示例管道所涉及的其他资源,都可在GitHub repo当中免费获取。
资源清理
即使在账户中继续保留管道,也不会给您带来任何额外开销。这是因为管道完全根据实际使用的计算资源量计费。但如果您需要清理,只需删除S3存储桶内的所有文件,并删除启动的CloudFormation栈即可。另外,请注意先执行文件删除,AWS CloudFormation不会自动删除S3存储桶内的文件。
要删除S3存储桶内的文件,请前往Amazon S3控制台,选择目标文件,并在Actions下拉菜单中选择Delete。
要删除CloudFormation Stack,请前往AWS CloudFormation控制台,选择对应的Stack并选择Delete。
在确认窗口中, 选择 Delete stack。
总结
在本文中,我们介绍了如何在无需编写任何代码的前提下,实现ML模型的训练与推理预测。AutoGluon、Amazon SageMaker以及AWS Lambda的密切配合最终让这一看似不可能的任务成为现实。大家可以使用本文中的示例无代码管道实现ML功能,整个过程轻松便捷,不需要任何编程或数据科学方面的专业知识。
如果您希望了解如何在组织内的产品及流程中以最佳实践方式使用ML技术,请与Amazon ML Solution Lab合作。Amazon ML Solution Lab将为您的团队安排Amazon ML专家,分步推进数据准备、模型构建、模型训练以及模型的生产应用等具体任务。Amazon ML Solution Lab将动手实践研讨会、头脑风暴小组讨论与咨询专业服务集于一身,帮助大家结合业务运营中的实际挑战,开发出基于ML的高质量解决方案。在项目结束后,您将掌握到过程中学习到的各项知识,并运用这些知识将ML技术全面推向组织内的各个层面。