亚马逊AWS官方博客
新增功能 – 使用 Amazon Comprehend 训练自定义文档分类器
Amazon Comprehend 让您能够大规模处理自然语言文本(更多信息请参阅我的介绍文章 Amazon Comprehend – Continuously Trained Natural Language Processing)。在 2017 年底推出并提供英语和西班牙支持后,我们增加了多项以客户为中心的功能,包括异步批处理操作、语法分析、支持更多语言(法语、德语、意大利语和葡萄牙语)以及在更多区域开放。
Comprehend 采用自动机器学习 (AutoML) 技术,可让您使用已经拥有的数据创建自定义的自然语言处理 (NLP) 模型,无需深入了解机器学习。根据您的数据集和使用案例不同,它会自动选择正确的算法,调整参数,编译并测试得出的模型。
如果您已经(通过 Amazon Transcribe、论坛帖子等等)拥有一组标记文档,例如持工单、联络中心对话等,您可以将这些文档作为起点。在这种情况下,标记仅指您已经检查了每份文档,并以期望的方式添加了标签以说明其特征。每个标签至少需要 50 个文档才能使用自定义分类功能,如果有数百个甚至输给签个文档当然更好。
在此博文中,我将重点介绍自定义分类,并将演示如何对模型进行训练以区分干净的文本和包含脏话的文本。然后我将演示如何使用模型来对新文本进行分类。
分类器的使用
首先我将使用一个与以下类似的 CSV 训练文本文件(我将所有文本进行了遮盖处理;但其中确实有许多的脏话):
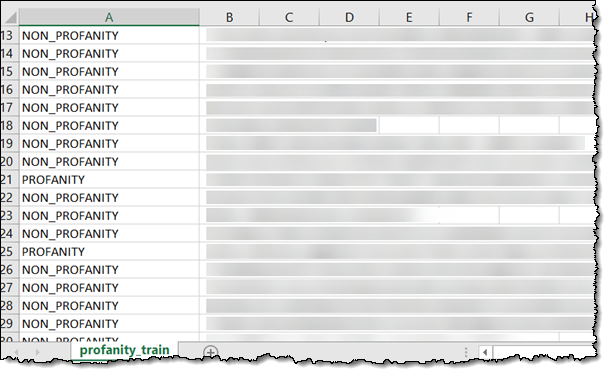
训练数据必须位于 S3 对象中,每行一个标签和一个文档:
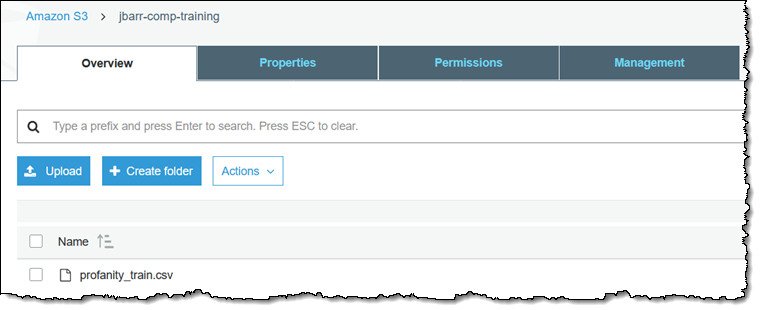
然后我会导航至 Amazon Comprehend 控制台并单击 分类。我还没有任何现有的分类器,因此我会单击 Create classifier 来创建一个:
我会给我的分类器命名并选择文档语言,选择我的训练数据所在的 S3 存储桶,然后创建一个拥有该存储桶访问权限的 AWS Identity and Access Management (IAM) 角色。然后我会单击 Create classifier 继续:
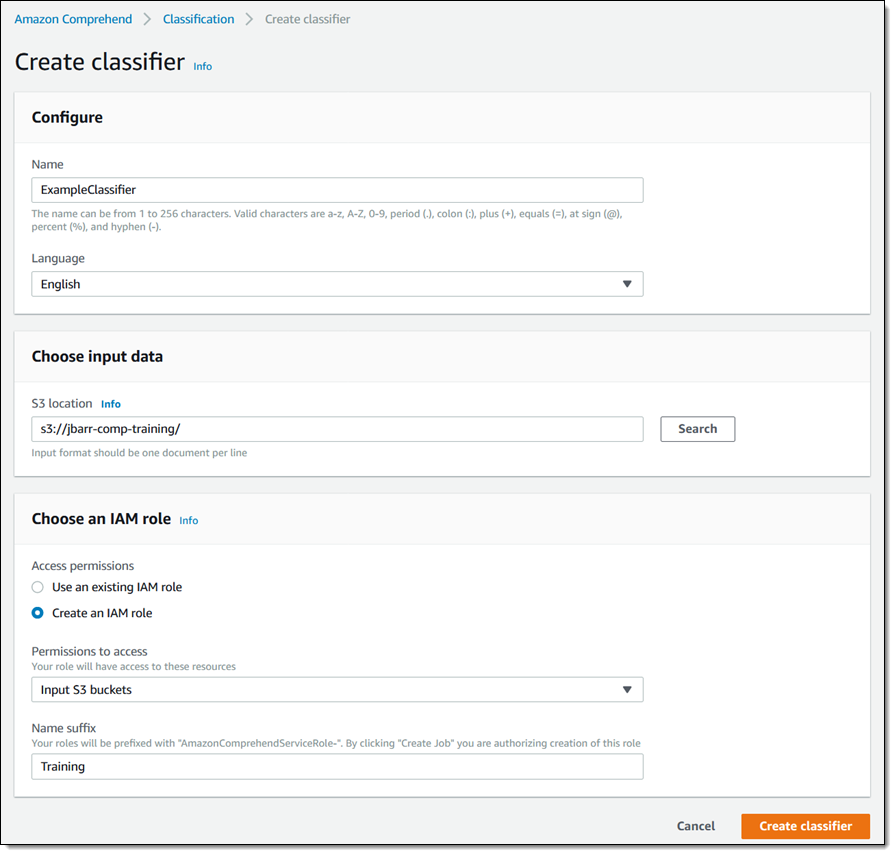
训练将会立即开始:
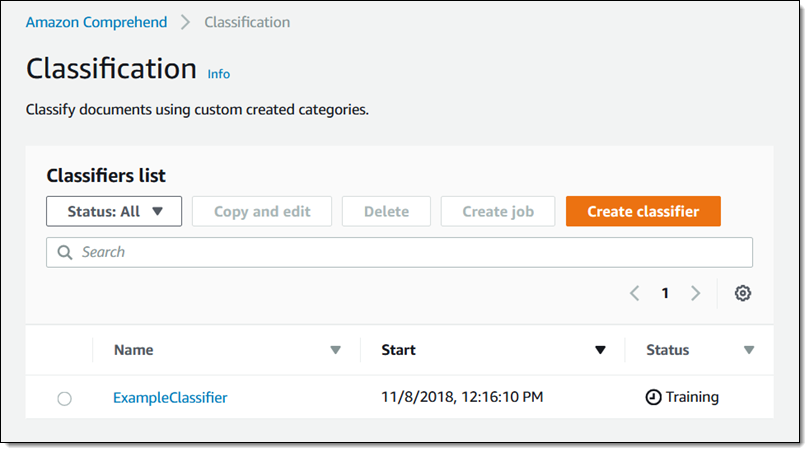
状态将会在几分钟内变为 Trained ,现在我已经做好准备,可以创建一个分析作业来对一些文本进行分类,其中一些文本可能含有脏话:
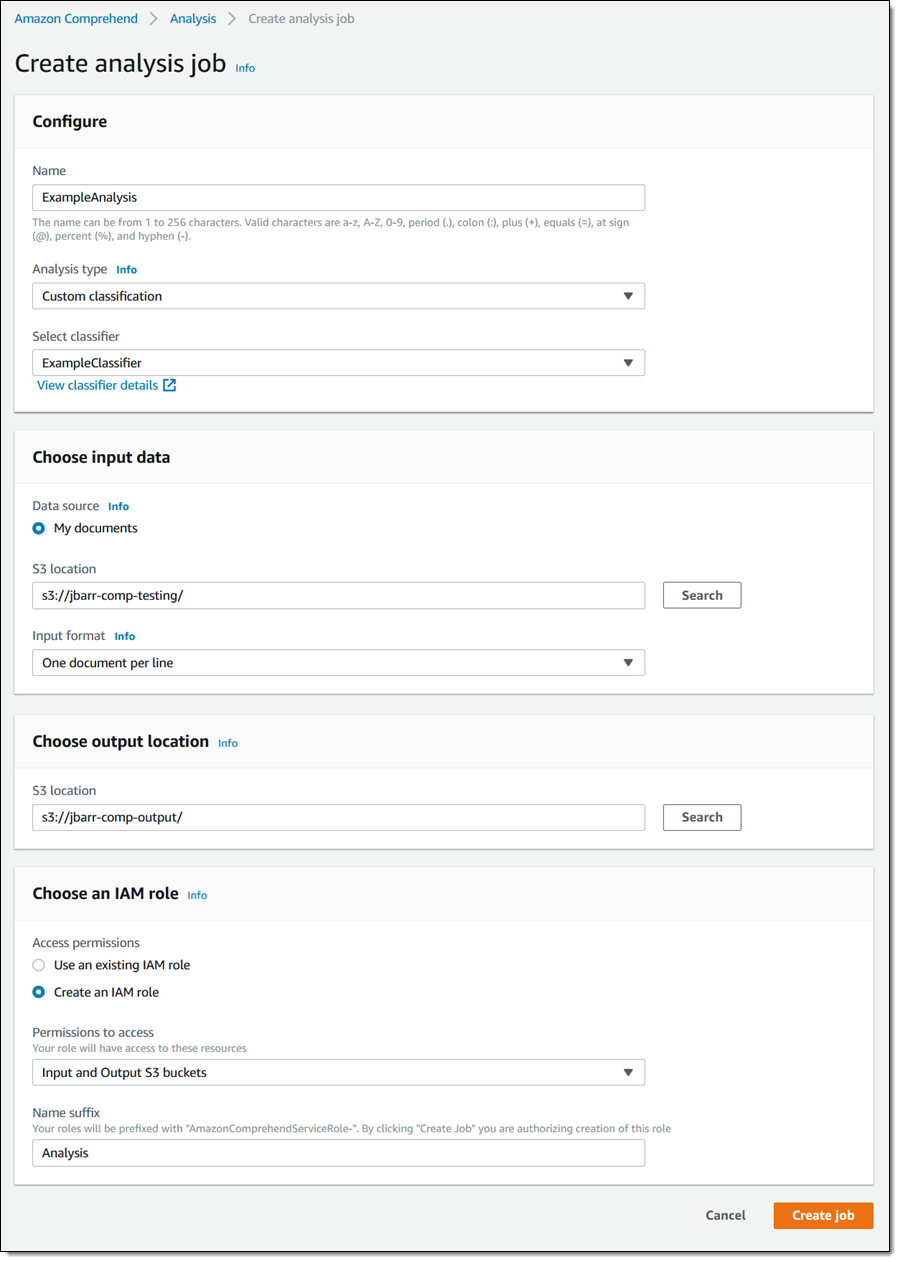
我将此文本放入另一个 S3 存储桶,在控制台中单击 分析 ,然后单击 Create job 。然后我会为作业命名,“Analysis type”选择“Custom classification”,然后选择我刚刚创建的分类器。我还会选择输入存储桶(上述文件)以及将用于接收结果的另一个存储桶,根据新创建的分类器分类,然后单击 Create job 继续(重要安全提示:如果您使用同一个 S3 存储桶来存储源和目标,请务必通过名称来引用输入文件):
作业会立即开始,只需几分钟就会完成:
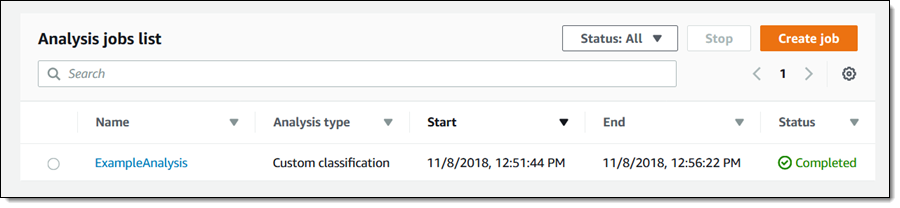 结果将存储在我在创建作业时选择的 S3 存储桶中:
结果将存储在我在创建作业时选择的 S3 存储桶中:
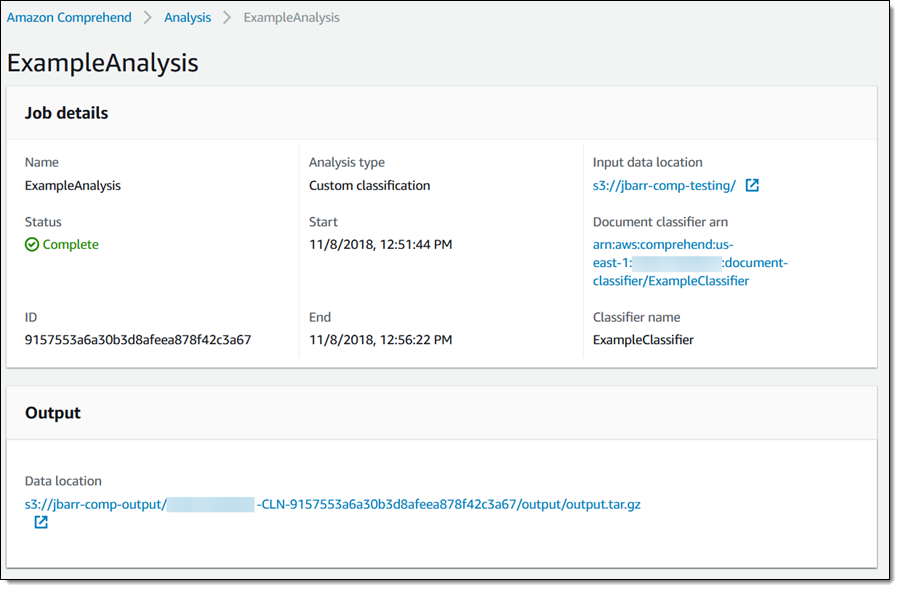
每行输出都对应输入文件中的一个文档:

下面是一行的详细显示:
可以看出,新推出的分类服务十分强大,使用非常方便。我可以在分钟内得到十分有用的高质量结果,无需任何机器学习的知识。
此外,您还可以使用 Amazon Comprehend CLI 和 Amazon Comprehend API 来训练和测试模型。
现已推出
Amazon Comprehend 分类服务现已在所有提供 Comprehend 的区域开放。