亚马逊AWS官方博客
下一代 SageMaker Notebook – 现具有内置数据准备、实时协作和 Notebook 自动化功能
2019 年,我们推出了首个数据科学与机器学习(ML)的全集成式开发环境(IDE):Amazon SageMaker Studio。SageMaker Studio 让您可以访问完全托管式 Jupyter Notebook,这些 Notebook 与专用工具集成,能够执行所有 ML 步骤,从准备数据到训练和调试模型、跟踪实验、部署和监控模型以及管理管道。
今天,我很高兴地宣布推出下一代 Amazon SageMaker Notebooks,它能够提高整个 ML 开发工作流的效率。您现在可以使用内置的数据准备功能在几分钟内提高数据质量,与团队实时编辑相同的 Notebook ,并自动将 Notebook 代码转换为生产就绪型作业。
下面我们来看看有哪些新功能!
用于简化数据准备的 Notebook 新功能
新的内置数据准备功能由 Amazon SageMaker Data Wrangler 提供支持,可在 SageMaker Studio Notebook 中使用。 SageMaker Studio Notebook 在 Pandas DataFrame 之上自动生成关键可视化图表,可帮助您了解数据分布并识别数据质量问题,例如缺失值、无效数据和异常值。您还可以为 ML 模型选择目标列并生成特定于 ML 的见解,例如不平衡类或高相关列。然后您会收到有关解决问题需进行的数据转换的建议。您可以直接在用户界面中应用数据转换,SageMaker Studio Notebook 会自动在 Notebook 单元格中生成相应的转换代码,您可以使用这些代码再次运行数据准备管道。
使用内置数据准备功能
首先,使用 pip 命令安装并导入 sagemaker_datawrangler 以及 pandas Python 程序包。然后,下载要分析的数据集到 Notebook 工作目录,并使用 pandas 读取该数据集。
import pandas as pd
import sagemaker_datawrangler
!aws s3 cp s3://<您的 S3 存储桶>/data.csv .
df = pd.read_csv("data.csv")
现在,当您显示 DataFrame 时,它会自动在每列的顶部显示关键数据可视化图表和数据见解、检测数据质量问题,并就如何提高数据质量提供解决方案建议。当您选择一个列作为 ML 预测的目标列时,您会收到特定于目标的见解和警告,例如目标中存在混合的数据类型(对于回归用例)或每个类的实例太少(对于分类用例)。
在此示例中,我使用的是电子商务女装评价数据集,其中包含客户对女装的评价和评分。此数据集是从 Kaggle 获得的,并已被 Amazon 修改以添加合成数据质量问题。

您可以查看提高数据质量所需数据转换的建议,并直接在用户界面中应用它们。如需所有支持的数据转换的列表,请查看文档。应用数据转换后,SageMaker Studio Notebook 会自动生成代码,以在另一个 Notebook 单元格中重现这些数据准备步骤。
对于本例,我选择将 Rating(评分)作为目标列。Target column insights(目标列见解)部分显示了一个高优先级警告,表示此列每个类的实例过少;并显示了一个中等优先级警告,表示类之间太不平衡。让我们按照建议删除罕见的目标值并删除缺失值。我还将遵循针对某些特征列的建议,删除 Review Text(评价文本)列中的缺失值并删除 Division Name(分类名称)列。
应用转换后,Notebook 会生成以下代码:
# 由 sagemaker_datawrangler 生成的 Pandas 代码
output_df = df.copy(deep=True)
# 删除 Rating(评分)列中的罕见目标值以解决警告“每个类的实例过少”的代码
rare_target_labels_to_drop = ['-100', '100']
output_df = output_df[~output_df['Rating'].isin(rare_target_labels_to_drop)]
# 删除 Rating(评分)列中的缺失值以解决警告“缺失值”的代码
output_df = output_df[output_df['Rating'].notnull()]
# 删除 Review Text(评价文本)列中的缺失值以解决警告“缺失值”的代码
output_df = output_df[output_df['Review Text'].notnull()]
# 删除 Division Name(分类名称)列以解决警告“缺失值”的代码
output_df=output_df.drop(columns=['Division Name'])我现在可以根据需要查看和修改代码,或者将这一数据转换集成到我的 ML 开发工作流中。
引入共享空间以实现基于团队的共享和实时协作
SageMaker Studio 现在提供共享空间,为数据科学和 ML 团队提供一个工作空间,让他们可以在其中实时阅读、编辑和运行 Notebook ,以简化开发过程中的协作和沟通。共享空间提供一个共享的 Amazon EFS 目录,您可以利用该目录共享文件。您在共享空间中创建的所有可标记 SageMaker 资源都会自动得到标记,以帮助您组织和筛选与您在共享空间中处理的业务问题相关的 ML 资源,例如训练作业、实验和模型。这也有助于您使用 AWS Budgets 和 AWS Cost Explorer 成本管理服务等工具监控成本和规划预算。
不仅如此,您现在还可以在同一个 AWS 账户中创建多个 SageMaker 域,以限定访问范围并将隔离组织中不同团队或业务部门所使用的资源。接下来我会演示如何在 SageMaker 域中为用户创建共享空间。
使用共享空间
您可以使用 SageMaker 控制台或 AWS CLI 为 SageMaker 域创建共享空间。要开始使用 SageMaker 控制台,请转到 Domains(域),选择或创建一个新域,然后在 Domain details(域详细信息)页面上选择 Space management(空间管理)。然后,选择 Create(创建)并为共享空间命名。
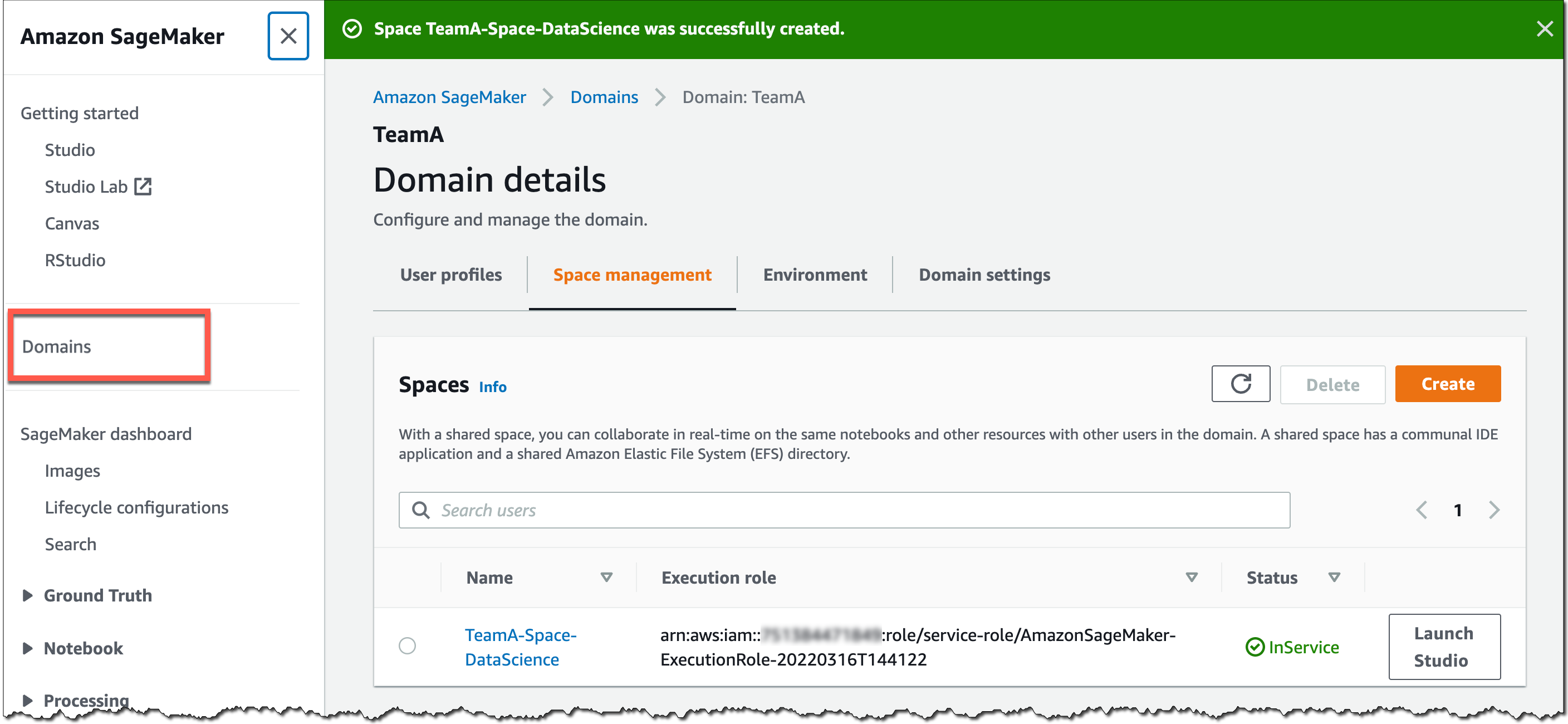
此 SageMaker 域中的用户现在可以通过其 SageMaker 域用户配置文件启动和加入该共享空间。
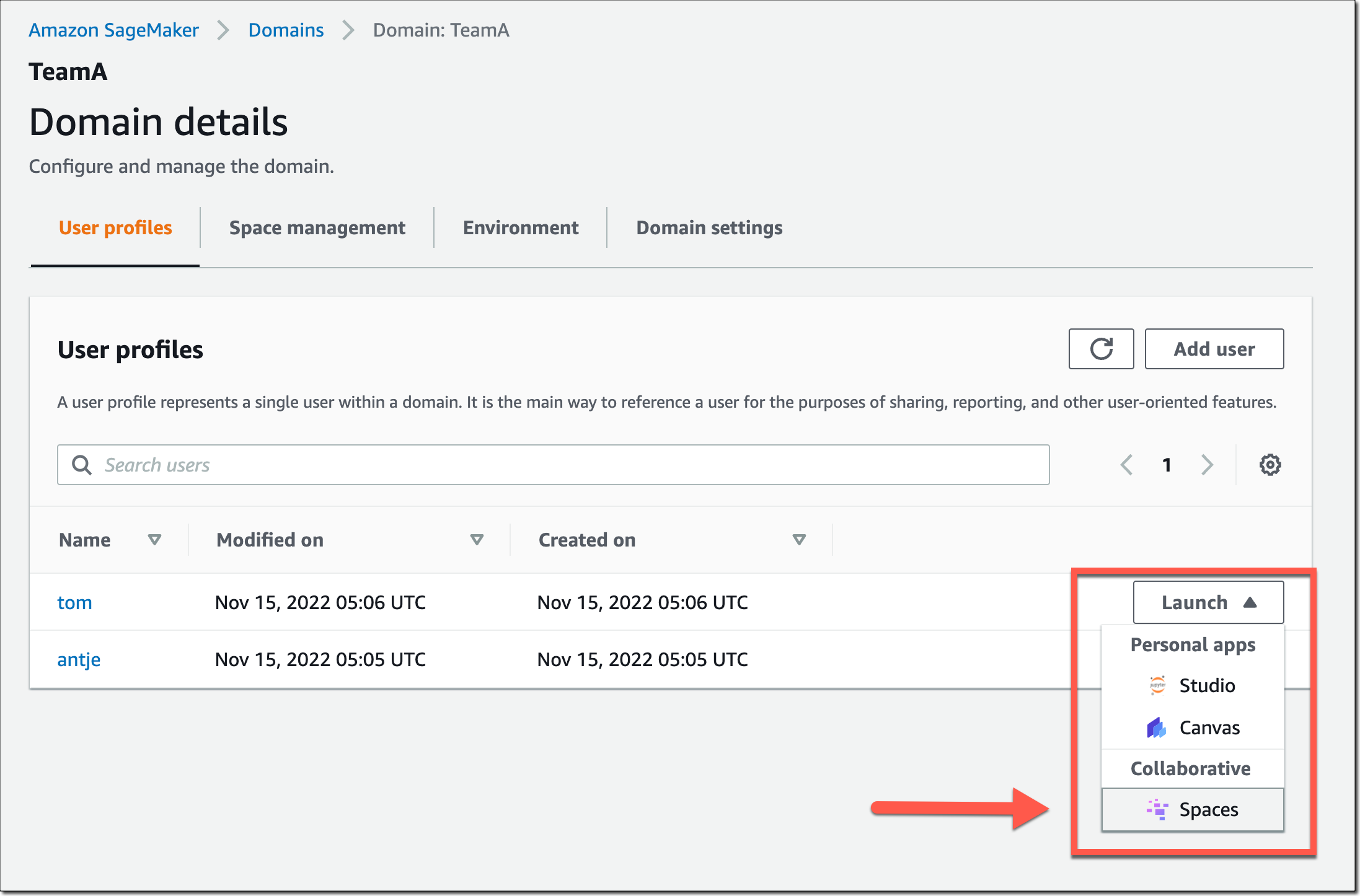
在共享空间中,选择左侧导航菜单中的新协作者图标。您现在可以看到当前还有谁在此空间中处于活动状态。以下屏幕截图显示左侧的用户 tom 正在编辑 Notebook 文件。在右侧,用户 antje 可以实时查看编辑内容,以及当前编辑该 Notebook 单元格的用户名注释。

新的 Notebook 功能可自动将 Notebook 代码转换为生产就绪型作业
您现在可以选择一个 Notebook 并将其自动化为可以在生产环境中运行的作业,而无需管理底层基础架构。当您创建 SageMaker Notebook 作业时,SageMaker Studio 会拍摄整个 Notebook 的快照,将其依赖项打包到容器中,构建基础架构,按照您定义的计划将该 Notebook 作为自动化作业运行,并在作业完成后解除预调配的基础架构。此 Notebook 功能现在也可在 SageMaker Studio Lab 中使用,这是我们的免费 ML 开发环境,可提供学习和试验 ML 所需的计算、存储和安全性。
使用 Notebook 功能自动化 Notebook
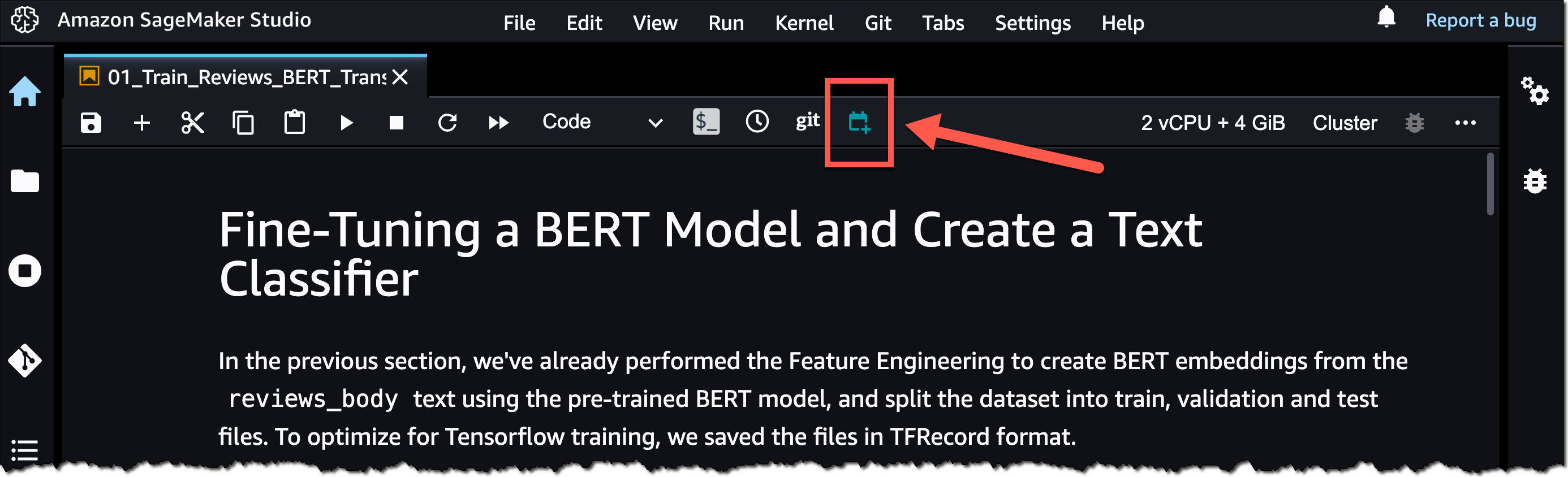
首先,在 SageMaker Studio 中打开一个 Notebook 文件。然后,右键单击该 Notebook 文件并选择 Create Notebook Job(创建 Notebook 作业)或选择创建 Notebook 作业图标,如以下屏幕截图突出显示所示。
为 Notebook Job(Notebook 作业)命名,检查输入文件位置,指定要使用的计算类型以及是立即运行作业还是按计划运行作业。然后选择 Create(创建)。
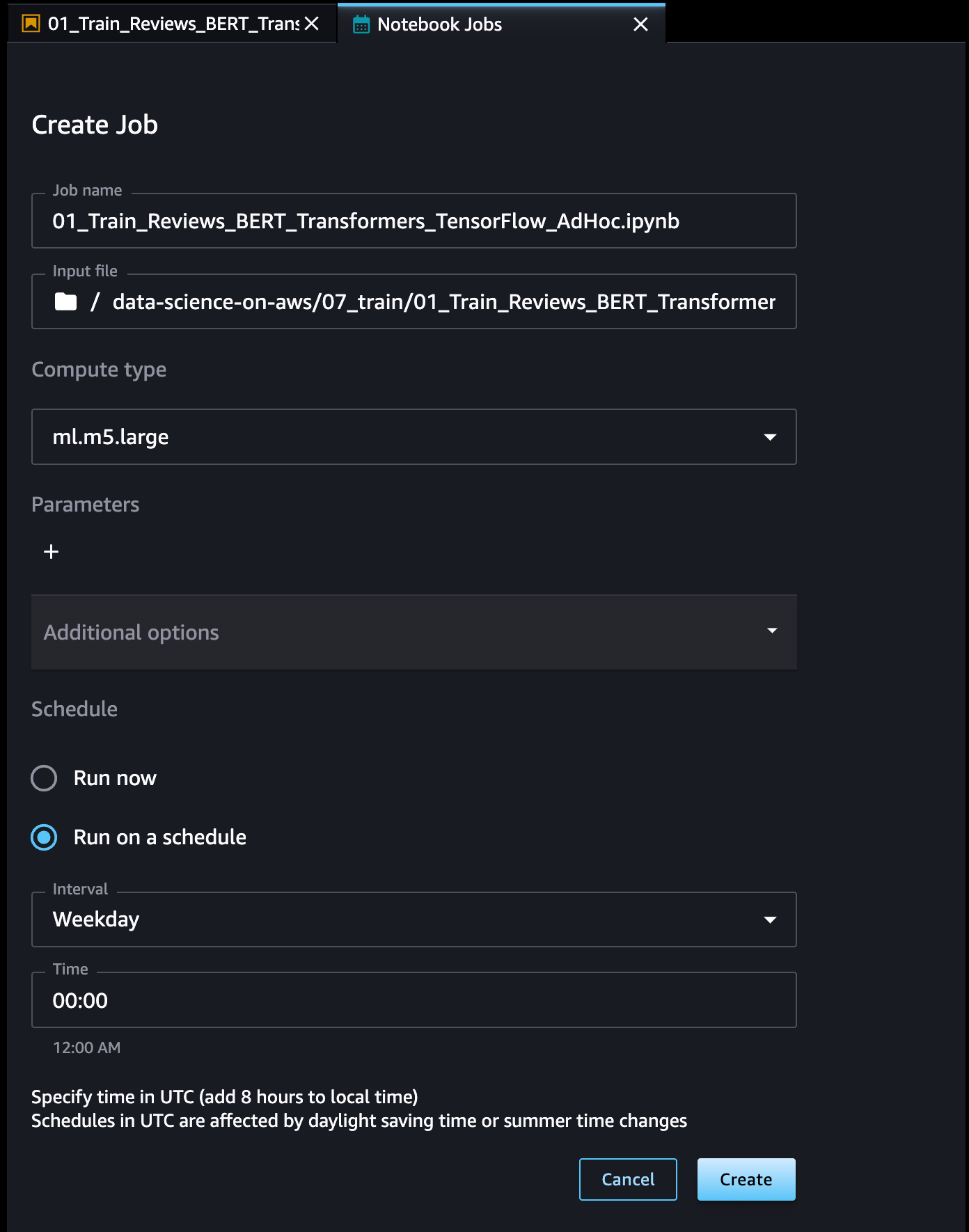
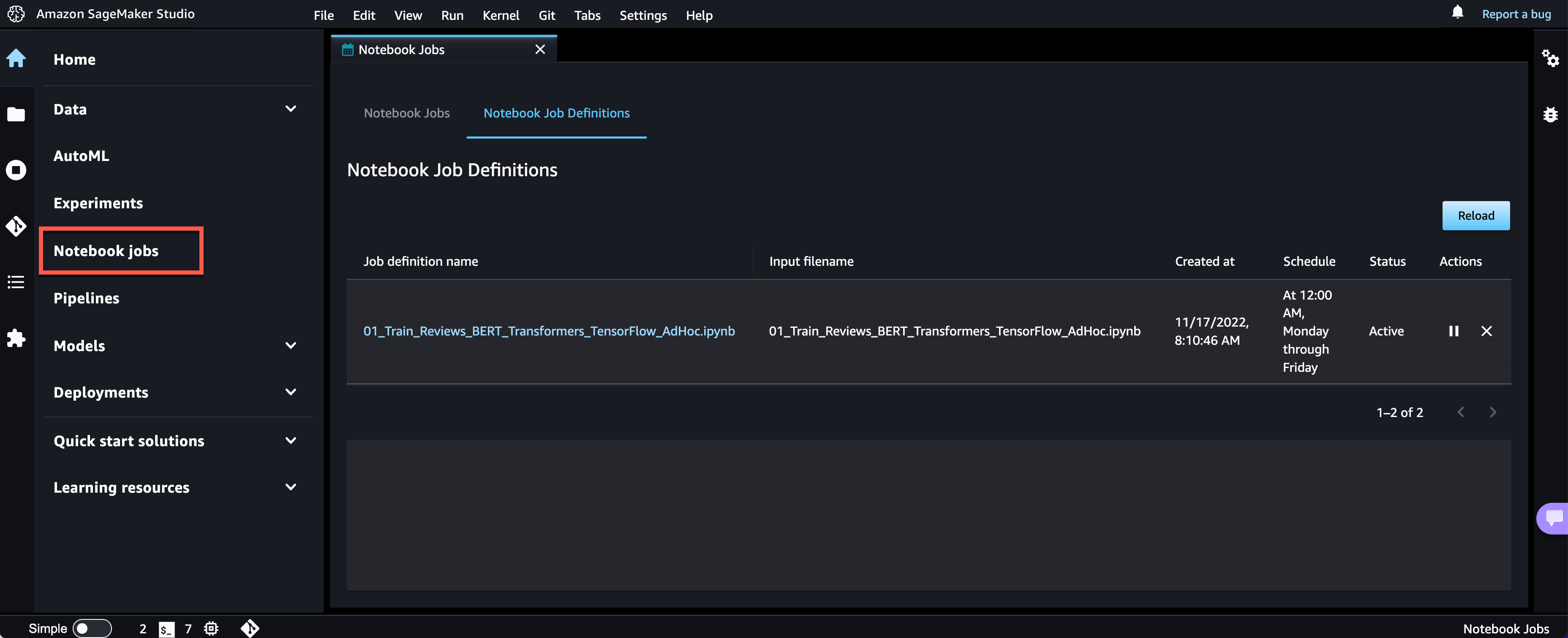
Notebook 作业已创建,您可以在用户界面中查看所有 Notebook 作业定义。
现已推出
新的 Amazon SageMaker Studio Notebook 功能现已在提供 Amazon SageMaker Studio 的所有 AWS 区域推出,AWS 中国区域除外。
在发布时,SageMaker Studio Notebook 和以下 Notebook 内核镜像支持由 SageMaker Data Wrangler 提供支持的内置数据准备功能:
- Python 3 (Data Science) with Python 3.7
- Python 3 (Data Science 2.0) with Python 3.8
- Python 3 (Data Science 3.0) with Python 3.10
- Spark Analytics 1.0 和 2.0
有关详细信息,请访问 Amazon SageMaker Notebook。
立即开始使用下一代 Amazon SageMaker Notebook 构建您的 ML 项目!
– Antje