亚马逊AWS官方博客
在 Amazon SageMaker 内对深度学习训练中的 GPU 性能进行 I/O 优化
GPU能够显著加快深度学习的训练速度,有望将训练周期由几个礼拜缩短至数小时。但要全面发挥GPU资源的强大性能,我们还需要考量以下因素:
- 优化代码以保证底层硬件得到充分利用。
- 使用最新高性能库与GPU驱动程序。
- 优化I/O与网络操作,确保数据能够以与计算能力相匹配的速率被送至GPU处。
- 在多GPU或分布式训练期间,优化GPU之间的通信。
Amazon SageMaker是一项全托管服务,能够帮助开发人员与数据科学家快速、轻松地构建、训练并部署任意规模的机器学习(ML)模型。在本文中,我们将重点介绍在Amazon SageMaker上进行训练时,能够切实提高I/O以优化GPU性能的通用型技术。这些技术方法具有良好的普适性,不对基础设施或深度学习框架本身做出任何要求。通过优化I/O处理例程,整个GPU训练中的性能提升最多可提升至10倍水平。
基础知识
单一GPU每秒可执行万亿次浮点运算(TFLOPS),意味着其运算执行速度可达到普通CPU的10到1000倍。为了让GPU正常执行这些运算,数据必须被存放在GPU内存当中。将数据加载至GPU内存中的速度越快,运算执行速度也就越快。其中的挑战在于如何优化I/O或网络操作,保证GPU在计算当中不必反复等待数据的传入。
下图所示,为I/O优化架构。

将数据放置进GPU内存通常涉及以下操作步骤:
- 网络操作——从Amazon Simple Storage Service (Amazon S3)处下载数据。
- 磁盘I/O——将数据从本地磁盘读入CPU内存。这里的本地磁盘是指实例存储,相关存储容量位于物理接入主机的磁盘之上。 Amazon Elastic Block Store (Amazon EBS) 存储卷不属于本地资源,其中涉及网络操作步骤。
- 数据预处理——一般来说,数据预处理工作主要由CPU负责完成,包括转换或者调整大小等。这些操作可能包括将图像或文本转换为张量形式、或者调整图像大小等。
- 数据传输至GPU内存——将处理后的数据从CPU内存复制到GPU内存。
以下各节将对优化步骤做出具体讲解。
优化网络中的数据下载操作
在本节中,我们将介绍一些技巧,探讨如何通过网络操作(例如从Amazon S3处下载数据、使用Amazon EBS以及Amazon Elastic Files System(简称Amazon EFS)等文件系统)优化数据传输。
优化文件大小
大家能够以低成本将大量数据存储在Amazon S3当中,其中包括来自应用程序数据库的数据,例如通过ETL过程提取为JSON或CSV格式的图像文件。而Amazon SageMaker运行中的第一步,就是从Amazon S3处下载文件——这种默认输入模式被称为文件模式。
即使是并行下载或上传体积极小的多个文件,其速度也要低于总大小相同的少数较大文件。例如,如果您拥有200万个文件,单个文件的大小为5 KB(总大小 = 10 GB = 200万 x 5 x 1024 KB),则下载大量小型文件可能需要耗费几个小时。但如果这10 GB数据量来自2000个单个大小为5 MB的文件(总大小 = 10 GB = 2000 x 5 x 1024 x 1024 KB),那么下载只需要几分钟就能完成。假定用于大文件与小文件的总存储容量与用于数据传输的线程数量大致相同,同时假设传输块大小为128 KB,那么面对仅为5 KB的实际文件大小,每个传输块的实际数据传输量也将仅为5 KB——而非128 KB。
在另一方面,如果文件太大,则无法使用并行处理加快文件的数据上传或者下载速度——除非大家使用Amazon S3 range gets等选项并行下载多个不同的数据块。
通过MXNet RecordIO与TFRecord等格式,我们可以将多个图像文件压缩并密集打包至单一文件当中,从而避免这种性能浪费。例如,MXNet RecordIO在处理图像时会建议对多幅图像进行尺寸压缩,确保将至少一批图像容纳到CPU/GPU内存当中;另外,通过将多幅图像密集打包至单一文件中,我们也能彻底消除I/O操作中因小文件传输导致的传输瓶颈。
作为一项通行原则,最佳文件大小一般在1到128 MB之间。
适用于大型数据集Amazon SageMaker ShardedByS3Key Amazon S3数据分布
在分布式训练期间,大家还可以跨多个实例对超大规模数据集进行分片。您可以将S3DataDistributionType参数设置为ShardedByS3Key,轻松实现Amazon SageMaker训练工作的数据分片。在此模式下,如果Amazon S3输入数据集总计包含M个对象,而训练作业有N个实例,则每个实例都将处理M/N个对象。关于更多详细信息,请参阅S3DataSource。在这种用例下,各设备上的模型训练将只使用训练数据中的一个子集。
适用于大型数据集的Amazon SageMaker Pipe模式
相较于SageMaker文件模式,Pipe模式可帮助我们直接将大量数据从Amazon S3流式传输至您的训练实例,而无需先将其下载至本地磁盘。Pipe模式允许我们的代码直接访问数据,这就避免了先行完整下载对速度产生的影响。由于数据永远不会被下载至磁盘,且只在内存中保留相对较小的占用空间,因此该模式会持续不断地从Amazon S3处下载数据,这非常适用于处理CPU内存无法一次性容纳的超大规模数据集。要使用部分原始字节在流式传输带来的可用性优势,大家需要在代码中根据记录格式(例如CSV)对字节进行解码,并找到记录末尾部分将部分字节转换为逻辑记录。Amazon SageMaker TensorFlow就为文本文件及TFRecord等常见格式提供内置的Pipe模式数据集读取器。关于更多详细信息,请参阅Amazon SageMaker为TensorFLow容器提供批量转换功能与Pipe输入模式。如果您使用的框架或库不具备内置数据读取器,也可以使用ML-IO库或者编写您自己的数据读器,从而正常使用Pipe模式。
Pipe模式流传输带来的另一个结果,则是要求对数据进行重新整理,即通过ShuffleConfig重新整理manifest文件及augmented manifest文件中的Amazon S3键前缀匹配或行结果。如果文件体积很大,则不能依靠Amazon SageMaker完成重整;这里大家必须预取“N”个批次,并根据ML框架编写代码以实现数据重整。
如果可以直接将整个数据集放入CPU内存当中,那么文件模式的执行效率可能比Pipe模式更高。这是因为如果内存足以容纳整个数据集,则需要一次性将完整数据集下载至本地磁盘,再一次性将整个数据集加载至内存中,并在训练流程中的各个阶段反复从内存中读取数据。从内存中读取数据,在速度上往往远高于网络I/O,能够带来显著的性能提升。
在下一节中,我们将讨论如何处理超大规模数据集。
使用Amazon FSx for Lustre或Amazon EFS 处理大型数据集
对于超大型数据集,大家可以使用分布式文件系统以缩短Amazon S3的下载时间。
大家可以在Amazon SageMaker上使用Amazon FSx for Lustre以缩短启动时间,并将数据驻留在Amazon S3当中。关于更多详细信息,请参阅使用Amazon FSx for Lustre与Amazon EFS文件系统加快Amazon SageMaker上的训练速度。
在首次运行训练作业时,FSx for Lustre会自动从Amazon S3处复制数据,并将其交付至Amazon SageMaker。另外,大家也可以将相同的FSx for Lustre文件系统用于对Amazon SageMaker上的训练作业进行后续迭代,以防止重复下载使用频率较高的Amazon S3对象。从这个角度看,对于将训练数据集放置在Amazon S3中的训练工作、以及需要使用不同训练算法或参数多次运行训练作业才能得到最佳效果的工作流当中,FSx for Lustre具有非常显著的比较优势。
如果您已经在 Amazon Elastic File System (Amazon EFS) 上拥有训练数据,还可以将Amazon EFS与Amazon SageMaker结合使用。关于更多详细信息,请参阅使用Amazon FSx for Lustre与Amazon EFS文件系统加快Amazon SageMaker上的训练速度。
在使用这个选项时,请务必关注文件的大小。如果文件体积过小,由于传输块大小的限制,I/O性能可能因此受到影响。
配备本地NVMe SSD存储的Amazon SageMaker 实例
一部分Amazon SageMaker GPU实例(例如ml.p3dn.24xlarge 与 ml.g4dn)提供基于NVMe的本地SSD存储,用以替代EBS存储卷。例如,ml.p3dn.24xlarge实例就提供1.8 GB的本地NVMe SSD存储容量。使用基于NVMe的本地SSD存储,意味着在将训练数据从Amazon S3下载至本地磁盘之后,磁盘的I/O要远远快于Amazon S3或EBS存储卷等的网络资源读取速度。如此一来,只要训练数据的大小与本地NVMe存储相适应,即可大大加快训练速度。
优化数据加载与预处理
在上一节中,我们探讨了如何高效从Amazon S3等源处下载数据。在本节中,我们将讨论如何提高并行化程度,并尽可能精简常用函数以进一步增强数据加载效率。
使用多个工作程序执行数据加载与预处理
TensorFlow、MXNet Gluon以及PyTorch都提供用于并行加载数据的数据加载器库。在以下PyTorch示例中,增加工作程序的数量能够让更多工作程序并行处理数据条目。作为一项通行原则,我们可以将工作程序的数量扩展至CPU数量减1的水平。这通常代表每个程序对应一个进程,并充分发挥Python的多线处理能力,当然具体实现细节因框架而异。多处理机制的引入能够避免Python全局解释器锁(GIL)使用全部CPU进行完全并行,进而导致资源余量不足;但这同时也意味着内存利用率将与工作程序的数量等比例增加,因为每个进程都需要在内存中保留自己的对象副本。当大家开始增加工作程序数量时,可能会引发内存不足问题。在这种情况下,我们需要选择CPU内存容量更高的实例类型。
为了跟踪工作程序的运行效果,我们参考以下示例数据集。在这套数据集中,__get_item__操作的休眠时长为1秒,用于模拟读取下一条记录时的对应延迟:

在示例中,我们创建一个只包含一个工作程序的数据加载器实例:

在使用单一工作程序的情况下,大家会看到它在逐一检索各个条目,且每次检索之间的延迟(间隔)为1秒钟:
如果将该实例上的工作程序数量增加到3个,则该实例至少需要4个CPU以保证并行处理的顺畅执行,具体参见以下代码:

在示例数据集中,我们可以看到3个工作程序正尝试并行检索3个条目,且操作的完成时间大约为1秒钟。此后,继续检索接下来的3个条目:

在此演示noteobok示例中,我们使用Caltech-256数据集,其中包含约30600张图像。在Amazon SageMaker训练任务中,我们使用单一ml.p3.2xlarge实例,其中包含1个GPU与8个vCPU。在只使用1个工作程序的情况下,每轮处理周期约为260秒,期间由单一GPU每秒处理大约100张图像。而在7个工作程序的情况下,每轮处理周期为96秒,每秒能够处理约300张图像,相当于性能提高了3倍。
下图所示,为单一工作程序在峰值利用率为50%时捕捉到的 GPUUtilization指标。

下图所示,为多工作程序、平均资源利用率为95%时的 GPUUtilization指标。

对num_workers做出的细微调整能够进一步加快数据加载速度,缩短数据的等待时长,从而让GPU的训练速度得到提升。这表明优化数据加载器中的I/O性能,确实能够提高GPU资源利用率。
在单一GPU上完成优化调整之后,接下来大家应选择在多GPU或多主机分布式GPU上进行模型训练。因此,在实际进行分布式训练之前,首先要保证能够在单一GPU上获得最理想的资源利用率。
优化常用函数
尽可能减少资源成本高昂的操作,同时在可能的情况下(使用GPU或CPU)检索各个记录项以提高训练性能。大家可以通过多种方式优化常用函数,例如使用正确的数据结构。
在演示notebook示例中,我们这套简单的实现方案会加载图像文件并调整各个条目的大小,具体参见以下示例代码。我们通过预处理Caltech 256数据集来优化函数,包括提前调整图像大小并保存处理后的图像文件版本。其中__getitem__函数仅尝试对图像进行随机裁剪,这就让__getitem__函数变得非常精简。GPU用于等待CPU预处理数据的时间更短,数据也将更快被交付至GPU内存。具体参见以下代码:

仅仅凭借这一项简单的更改,我们就成功将每轮处理周期缩短至96秒,每秒处理的图像增长至300张,速度相当于单一工作程序处理未优化数据集时的3倍。另外,即使进一步增加工作程序的数量,GPU受到的影响也不大,因为数据加载过程不再构成性能瓶颈。
在某些情况下,大家可能需要不断增加工作程序数据并优化代码,借此实现GPU资源利用率最大化。
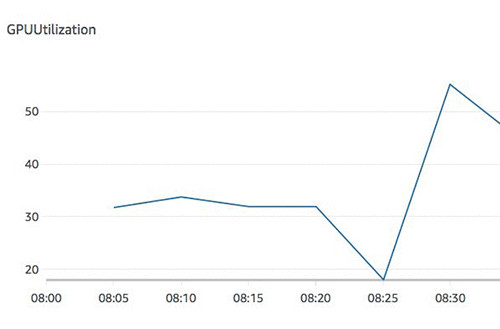
下图所示,为优化后数据集配合单一工作程序时的GPU资源利用率。

下图所示,为使用未优化数据集时的GPU资源利用率。
了解您的ML框架
不同深度学习框架中的数据加载库可以提供多种数据加载优化选项,TensorFlow数据加载器、MXNet以及PyTorch数据加载器都有相关功能。您应该探索最适合当前用例与取舍方向的数据加载器与库参数。其中部分相关选项包括:
- CPU固定内存——允许您加快从CPU(主机)内存到GPU(设备)内存的数据传输速度。之所以能够实现加速,是因为我们直接分配页面锁定(或者称固定)内存(而非先分配页面内存、再将数据从CPU分页内存传输至CPU固定内存、再到GPU内存)以实现性能提升。在PyTOrch与MXNet中,我们可以在数据加载器内启用CPU固定内存。这里的取舍在于,相较于分页内存,固定CPU内存机制更可能引发内存不足异常。
- Modin——这是一种轻量化并行处理数据框,允许大家以并行方式执行类似于Pandas数据框的操作,从而充分利用设备上的CPU资源。Modin可以使用多种不同类型的并行处理框架,包括Dask 与 Ray。
- CuPy——该开源矩阵库与NumPy类似,能够配合Python实现GPU计算加速。
以启发式方法找到I/O瓶颈
Amazon SageMaker能够立足训练阶段提供关于GPU、CPU以及磁盘利用率等多种Amazon CloudWatch指标。关于更多详细信息,请参阅使用Amazon CloudWatch监控Amazon SageMaker。
以下启发式方法,能够帮助大家通过各类开箱即用的指标发现关于I/O的各类性能问题:
- 如果您的训练作业启动时间很长,则代表大部分时间被用于数据下载。您应该了解从Amazon S3下载数据方面的优化方法,具体请参阅前文内容。
- 如果GPU利用率过低,但磁盘或者CPU的利用率过高,则代表数据加载或预处理可能正是引发瓶颈的根源。您可能需要在训练之前进行数据预处理;另外,大家也可以遵循前文建议优化各项常用函数。
- 如果数据集已经非常庞大,但GPU使用率低下且CPU与磁盘利用率一直很低(但不为零),则可能意味着当前代码未能充分利用基础设施资源。如果您发现CPU内存的利用率同样很低,那么最有效的快速解决办法可能是增加深度学习框架数据加载器API中的工作程序数量。
总结
到这里,相信大家已经了解了数据加载与处理如何影响GPU资源利用率,以及该如何通过解决I/O或与网络相关的瓶颈以提高GPU性能。在进一步讨论多GPU或者分布式模型训练等高级主题之前,我们应该首先解决这些最基本但也极为关键的瓶颈。
关于Amazon SageMaker使用方面的更多详细信息,请参考以下资源:
- Amazon SageMaker示例 – GitHub repo
- TensorFlow – 使用tf.data API实现性能提升
- MXNet – 设计用于深度学习的高效数据加载器
- PyTorch数据加载器– TORCH.UTILS.DATA