亚马逊AWS官方博客
PB 级 HDFS 格式数据迁移到 Amazon S3 数据湖最佳实践
用户场景
大量的企业客户使用 Hadoop 分布式文件系统 (HDFS) 作为本地 Hadoop 应用程序的存储库。随着数据源的增加,存储新连接数据的需求也在增长,越来越多的客户使用Amazon S3数据湖存储库,以获得更安全、可扩展、敏捷且经济高效的解决方案。
对于无法以高速传输到 AWS 的 HDFS 迁移,AWS 提供了 AWS Snowball Edge 服务。使用 AWS Snowball Edge 进行 HDFS 迁移的最佳实践是使用中间暂存机进行文件传输。这篇博文详细介绍了在这种场景下如何进行高效迁移。
AWS Snowball Edge支持从本地存储(SAN、NAS、并行文件系统)或数据库到Amazon S3 的PB 级离线数据迁移。AWS Snowball Edge 是AWS Snow 系列以及可用于数据迁移的更大 AWS 数据传输服务组合的一部分。AWS 数据传输服务组合还包括 AWS DataSync 用于快速在线传输。在使用在线或离线传输机制之间进行选择时,可用网络带宽是一个关键考虑因素。例如,通过专用的 500 Mbps 网络连接传输 1PB 数据大约需要 8 个月,这可能会超过迁移项目的时间表。当到 AWS 的网络带宽有限且数据量很大时,Snowball Edge 为大规模迁移提供了一种快速机制。
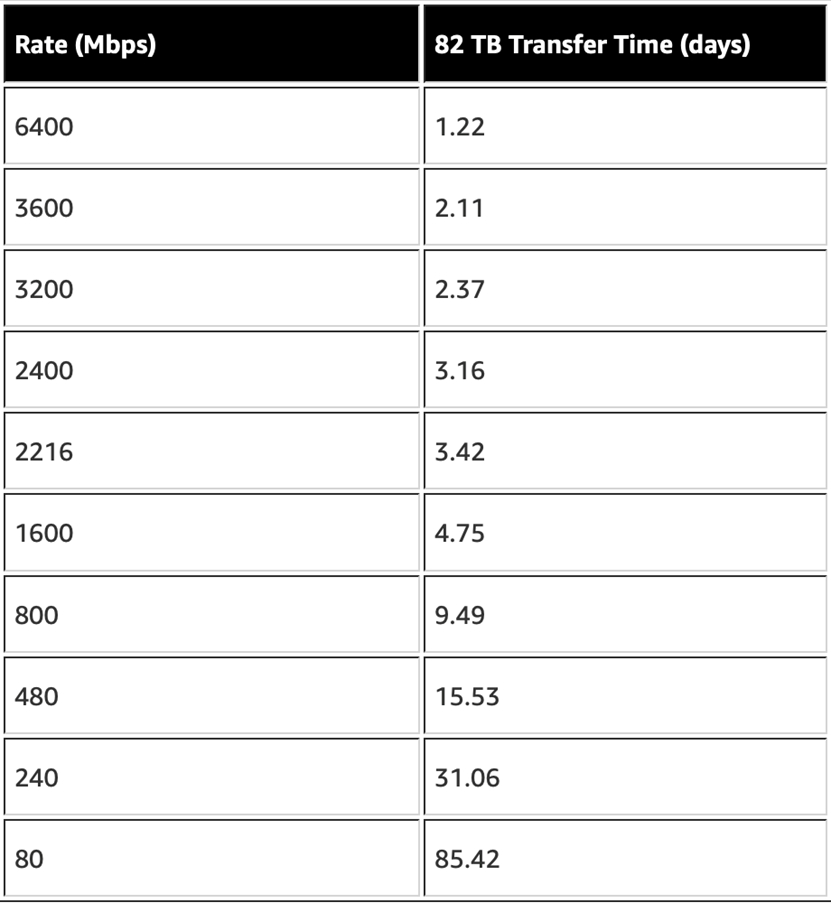
如果您在将本地复制到 Amazon S3 时遇到任何网络限制,AWS Snowball Edge 可为您提供安全复制、批量传输文件和执行边缘计算的能力。使用 AWS Snowball Edge 传输超过 10 TB 的数据可能比其他任何东西都更能优化成本。下面的图 2 根据下降的网络传输速率估计了传输时间。将此与您的 Snowball Edge 时间线进行比较时,每个 Snowball Edge 从作业订单到 S3 中可用的数据大约需要 15 天。

迁移步骤
以下步骤将引导您了解如何使用带有 AWS Snowball Edge 的临时机器将 HDFS 文件迁移到 Amazon S3:
- 准备中间暂存机
- 测试复制性能
- 将文件复制到设备
- 验证文件传输
第 1 步:准备中间暂存机
以下部分详细介绍了如何设置中间暂存机。作为最佳实践,Hadoop 文件传输到 AWS Snowball Edge 使用将 HDFS 挂载到本地文件系统的中间暂存机器。挂载 HDFS 允许您将其作为本地文件系统与其交互。然后,临时机器用于从 HDFS 进行高吞吐量并行读取并写入 AWS Snowball Edge。您可以在下面看到图 3 中的工作流程。
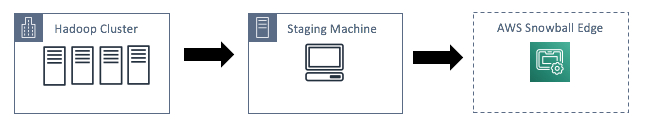
- 注意:如果使用多台临时机器,每台机器都必须将 HDFS 作为本地文件系统挂载。
暂存机的当前指南至少需要四个内核、32 GB 内存和快速磁盘访问,以优化您的吞吐量。中间暂存机可以是具有 10G 位网络上行链路的虚拟机 (VM) 或裸机主机。它甚至可以是部署在 Snowball Edge 上的 AMI。据观察,在执行大型复制操作时,裸机主机会提供更好的性能。
中间暂存机设置
- 安装AWS CLI。
- 为您的 Hadoop 集群配置一个可挂载的 HDFS。安装和配置“用户空间文件系统”(FUSE)作为 HDFS 的接口。
- 将 FUSE 接口挂载到中间暂存机并测试您对 HDFS 作为本地文件系统的访问。挂载的接口允许您作为本地文件系统与 HDFS 交互。
第 2 步:测试复制性能
以下部分探讨了提高整体和测试复制性能。在吞吐量方面,单个复制或同步操作不足以传输大型数据集。为了提高传输速率,应该探索数据分区和并行复制选项。
对于大型数据传输,我们建议将您的数据划分为多个不同的部分。对文件传输进行分段允许并行传输或一次传输一个分区。如果发生复制失败,对识别的段进行故障排除可以更快地解决问题。只查看失败的部分,而不是查看整个数据集。并行传输支持多次写入 AWS Snowball Edge 以提高性能。
- 注意:客户使用 GNU parallel 与多个 worker 进行并行传输。并行操作的数量取决于网络带宽、数据源性能和延迟。
一旦设置了临时机器并计划了段,请测试复制操作吞吐量。成功传输到 Snowball Edge 的 HDFS 能够实现 1.6-2.4 Gbps 的吞吐量。性能因硬件、网络和文件大小而异。
下面列出了一个简单的复制命令:
aws s3 cp /path/to/<file> s3://bucket/prefix/<file> --endpoint http://<SNOWBALL_EDGE IP>:8080 -–profile <profile-name>
- 打开一个终端并运行 aws s3 cp
- 记录传输速率(例如 400 Mbps)。
- 通过继续添加带有 aws s3 cp 的终端来并行化复制功能——在每次测试后评估性能。您会看到性能的上限,其中添加终端可能会对您的吞吐量产生负面影响。
- 添加终端性能(终端 1 @ 400 Mbps 和终端 2 @ 400 Mbps)。在此示例中,您以 800 Mbps 进行传输。有关提高性能、目标网络延迟、暂存机器增强、文件大小优化以及通过 FUSE 挂载确保 HDFS 读取率的更多信息。此外,请查看数据迁移的最佳实践。
第 3 步:将文件复制到设备
完成性能测试和优化后,准备命令以将文件并行复制到 Snowball Edge 设备。这些命令应该在中间暂存机上运行。例如,以下命令对指定路径内的所有文件执行递归复制,并将它们写入 AWS Snowball Edge 终端节点。
下面列出了递归复制命令:
aws s3 cp /path/to/mounted/hdfs s3://bucket_name --recursive --endpoint http://<SNOWBALL_EDGE IP>:8080 -–profile <profile-name>
除了并行运行传输之外,将较小的文件(小于 5 MB)一起批处理有助于提高吞吐量。默认情况下,Snowball Edge 在每次复制操作期间使用 256 位加密对所有数据进行加密。加密过程的开销可能会导致传输较小文件期间出现延迟。批处理较小的文件有助于提高传输性能。我们建议在单个存档中将对象与最多 10,000 个其他文件一起批处理。在传输操作期间,启用导入 Amazon S3 的档案的自动提取。
下面列出了批处理和复制文件的命令:
第 4 步:验证文件传输
完成将文件传输到 AWS Snowball Edge 之后,在将设备运回 AWS 之前,还有一个重要步骤。这验证了您的所有文件都可以成功导入到 Amazon S3。
使用 aws s3 ls 命令列出 AWS Snowball Edge 设备上的所有对象。拥有复制到设备的对象清单后,您可以轻松地将其与来自源位置的文件进行比较。使用此方法来识别任何未传输的文件。
如果存在任何验证错误,则文件不会写入设备。查看一些常见的验证错误。
验证后,断开设备并将其发回 AWS。AWS 收到 AWS Snowball Edge 后,会将数据导入 Amazon S3。发生这种情况时,您可以导航到 AWS 管理控制台中的作业完成报告。该报告提供了该工作的概述。
如果需要对导入作业进行额外验证,您可以启用 S3 清单。您还可以在 S3 存储桶和用于导入的前缀上使用 Amazon S3 同步。S3 清单生成一个 csv 文件,您可以将其与您在本地迁移的源文件进行比较。运行 aws s3 sync 递归地将新的和更新的文件从源目录复制到目标。该命令同步目录和 S3 前缀。
- 注意:要使用同步命令进行验证,您必须能够从客户端连接到 Internet。
结论
随着您本地数据和 Hadoop 环境的增长,AWS Snowball Edge 可用于加速您的 Amazon S3 数据湖迁移之旅。对于网络带宽有限且不合理的 Hadoop 迁移,AWS 提供了 AWS Snowball Edge 服务。Amazon S3 为您的历史数据和不断增长的数据提供了更安全、可扩展且更具成本效益的存储解决方案。
了解更多: