AWS Storage Blog
Data Migration Best Practices with AWS Snowball Edge
AWS Snowball Edge enables petabyte-scale offline data migrations from on-premises storage (SAN, NAS, parallel file systems) or databases into Amazon S3. AWS Snowball Edge is part of the AWS Snow Family and the greater AWS portfolio of data transfer services that can be used for data migration. The AWS portfolio of data transfer services also includes AWS DataSync for fast online transfers. Usable network bandwidth is a key consideration when choosing between using online or offline transfer mechanisms. For instance, transferring 1PB of data over a dedicated 500 Mbps network connection takes approximately 8 months, which may exceed a migration project’s timeline. Snowball Edge provides a fast mechanism for large migrations when network bandwidth to AWS is limited and data volumes are large.
The Snowball Edge service uses a ruggedized storage and edge computing device to enable customers to physically ship data to AWS in a secure and reliable manner, reducing the need for network bandwidth. In this blog post, we share the best practices that our customers are using to achieve an efficient and cost-effective migration with Snowball Edge.
Overview
Figure 1 illustrates the architecture commonly used for migrating data from on-premises data sources such as NAS arrays, databases, data warehouses, or other storage systems to AWS using Snowball Edge. The Snowball Edge Storage Optimized (SBE -SO) device has a raw storage capacity of 100 TB with a built-in Amazon S3 compatible endpoint, Amazon EC2 compute, and block storage capabilities.

Figure 1: Snowball Edge Data Migration Architecture
This architecture uses a temporary “staging workstation.” The workstation mounts the data source using the NFS or SMB protocol. For migrations of data from Hadoop (HDFS/QFS) or other file systems, this architecture enables the use of native connectors and libraries on the staging workstation to mount the data source. Once you mount the data source, use the AWS Command Line Interface (CLI) commands (copy and sync) to transfer your data into the Snowball Edge, as shown here: aws s3 cp -r /nfs/directoryX s3://mybucket/. The AWS CLI version specified in the Snowball Edge Developer Guide can read/write/edit objects through the Snowball Edge S3 adaptor interface on the device’s storage. The Snowball Edge S3 adaptor interface implements a subset of the Amazon S3 REST API actions, with a complete list of supported operations in the AWS Snowball Edge Developer Guide.
This architecture can be modified to transfer data directly to the S3 interface when the operation is supported by the application platform. For example, data warehouse solutions such as Teradata, have a tool called TD Export/FastExport to copy data directly to a S3 bucket in Snowball Edge. This architecture does not need a staging workstation. The Snowball Edge Client will still be needed for management functions such as unlocking, monitoring capacity, etc.
Because the Snowball Edge Amazon S3 adaptor implements a subset of the standard S3 API, some API calls from third-party tools may not work. For instance, the Hadoop DistCp (distributed copy) command cannot be used directly with Snowball Edge at this time. However, Hadoop (HDFS and QFS) data can still be copied to the S3 adaptor after mounting it on a staging workstation.
Anytime a direct export feature is used for the data transfer, it is necessary to validate functionality and performance. It is also important to check available utilities and tools during the planning stage. A number of migration, backup and recovery, and archive software providers in the Amazon Partner Network (APN) support Snowball Edge as a target storage for their applications. This also eliminates the need for custom scripting. These tools can be used with Snowball Edge for data transfer. Please see the list of partner tools later in this blog post.
Many AWS customers follow a prescriptive process which enable them to complete large migrations successfully. We review this process in the following section. Also, we dive deep into the planning, validation, and optimization aspects of the migration to ensure you are adequately prepared for your migration project.
Migration Process
Illustrated below (Figure 2) is the high-level process for a large data migration using Snowball Edge:
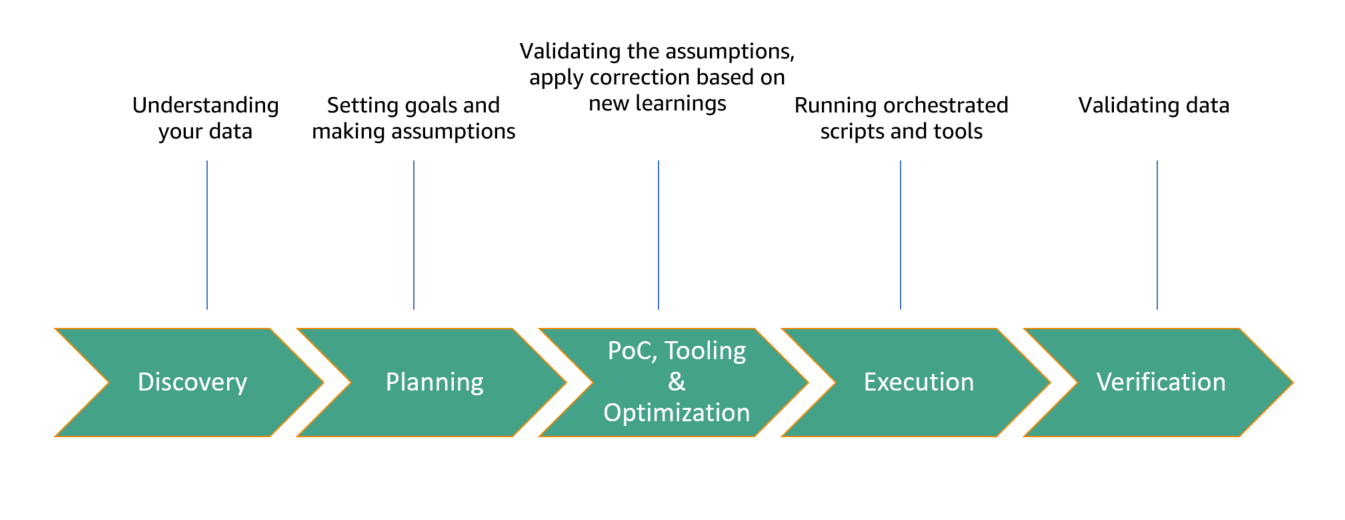
Figure 2: Snowball Edge Data Migration Process
Discovery is the first phase, with the goal of identifying the data; where it is located, how it can be accessed, how it is consumed, and access patterns expected during the migration. This phase will also reveal network topology, average file sizes, file system protocols, performance, etc. You must also consider the timelines, such as when the data is needed in AWS.
The Planning phase will enable you to establish target timelines, assess the existing infrastructure, determine the available resources for developing and managing tools, and define the needs for post-migration tasks. You must plan for post-migration processing, data lifecycling, and cost optimization.
The Proof of Concept (PoC), Tooling, and Optimization phase is key to ensuring your transfer goals are achieved. We recommend using a single Snowball Edge to evaluate the end-to-end process. This will help you gain insights into the data transfer, identify possible impediments, and optimize the tools for a cost optimized migration. We review this in more detail in the following section.
The Execution phase requires some overhead to ensure the workflow stays intact. In this phase the Snowball Edge orders and deliveries must be aligned with the workflow. You may be able to accelerate the migration schedule once you have mastered the process.
The Validation phase is the final stage where your data is now in Amazon S3. Here you can perform additional validations for data integrity with S3 Integrity Check. This is needed to ensure that the data is transferred without any modifications. The validations can be done fully, partially, or by using random sampling across all files transferred. While the data copied during the initial data transfer to Snowball Edge is validated natively on Snowball Edge, it may be necessary to run this additional integrity check between the source file and the S3 object for compliance.
For large migrations, it is recommended that you engage your AWS account team while planning. This will help us to align the right information and resources for your success.
Snowball Edge Migration Proof of Concept (PoC), Tooling, and Optimization
In this phase, obtain a single Snowball Edge and install it in your network. Provision a single staging workstation with the recommended Snowball client and AWS CLI. Connect the data source and perform transfer operations using AWS CLI. Some optimizations in your network, such as switch and firewall configuration, may be necessary at this phase. You may also have to explore which of the three connectivity options (RJ45, SFP, QFSP) will provide you with the best performance.
For management, orchestration, and data ingest, you may have to develop some basic scripts. The scripting may vary based on the data source and environment. For bulk data transfers that run parallel operations, a large number of Snowball Edges will be used. The pricing for Snowball Edge devices is based on the number of days you keep the device. Running this PoC and applying the learnings will reduce the cost of the migration.
One goal during this phase is to achieve the best data transfer performance between the on-premises source and Snowball Edge. For example, if you achieve a transfer speed of around 1.6 Gbps, transferring 85 TiB data can be copied within 5 days. Some customers have seen higher transfer rates of around 3.2 Gbps when file sizes of 5 MB and above are transferred. Please keep in mind that this is an ideal situation where the network, staging workstation, and the on-premises source are optimized.
We recommend the following aspects for your environment to achieve optimal transfer performance:
- The on-premises source storage system must have aggregate read throughput greater than or equal to the sum of the transfer rates you want for each Snowball Edge device you are writing to. If you have 3 Snowball Edge devices and are targeting 300 MBps per device, the aggregate throughput supported on the source storage system would be 900 MBps (7.2 Gbps). This is important as the source storage read performance can be a limiting factor.
- For the network requirements, the on-premises source storage should ideally be on the same subnet as the Staging Workstation and the Snowball Edge device. The network link should be greater than or equal to 10 Gbps, and ideally have less than 1 ms latency and zero packet loss.
- The Staging Workstation requires 4 cores, 32 GB of RAM, 10 GE or faster network interfaces, and have fast disk access. To ensure fast disk access when using a virtual machine environment, do not use NAS as the root partition for a VM-hosted workstation.
- The ideal file size is 5 MB or above for data transfer performance. In the event there are many smaller files in your source system, you should batch these into larger files > 5 MB. With AWS CLI, this functionality is not supported natively, so additional scripts would be needed to zip/gzip your smaller files into a larger file.
AWS CLI has two primary commands used in transferring data from the local file system to the Snowball Edge; copy and sync. Both commands discard the file attributes except the file size, which is mapped to the “content-size” Amazon S3 object attribute. In use cases where the standard POSIX metadata need to be stored, you add it to user-defined attributes in Amazon S3 objects with–metadata option. The following example shows how to store owner, group, creation time, and access time, during scripted transfers: aws s3 cp source-file s3://bucket-name --endpoint end-point-name --profile profile-name --metadata “owner=jon,group=foo,ctime=1569326676,atime=1569326777”
Figure 3 illustrates a summary of the tooling and optimization requirements and functionality as applied to the Snowball Edge Data migration architecture we are proposing.

Figure 3: Snowball Edge Data Migration Tooling and Optimization Summary
Once aggregate throughputs are determined, tooling is established, and the infrastructure is prepared, the next step is to order the desired number of Snowball Edge devices in the AWS Console. The goal is to use the optimized transfer speeds and tooling to determine the ingest timelines and align the Snowball Edge orders in order to optimize the data migration. As an example, for a migration of a 1 PB data lake, your PoC phase shows that the environment can support up to 5 Snowball Edge units concurrently with the maximum throughput per Snowball Edge at 1.6 Gbps. This scenario requires a total of 13 Snowball Edges split across 3 waves to migrate your full 1 PB to Amazon S3. The optimal schedule for each wave of Snowball Edge devices is every 6 days based on transfer speed and manpower at the data center site. It is important to communicate the schedule to your account team to ensure timely delivery, along with addressing additional support needs for your project.
Partner Solutions
Many customers already have software tools that support use cases around backup, disaster recovery, archival, and migrations, which may support Snowball Edge as a storage solution for data transfer. Such products vary in functionality and usage for a particular use case, but generally they can be used for transporting the data to the destination (Amazon S3). Below are AWS Partner Network storage partners that support Snowball/Snowball Edge, at the time of this post.
| APN Partner | Software & Version | Use Cases Supported | Snowball/Snowball Edge Support | References |
| Cohesity | DataPlatform | Backup & Restore, Archive, Disaster Recovery | -Snowball
-Snowball Edge |
Website |
| Commvault | Commvault V11 SP6+ | Backup & Restore, Archive, Disaster Recovery | -Snowball
-Snowball Edge |
Documentation |
| Druva | Druva Phoenix | Backup & Restore, Archive, Disaster Recovery | -Snowball Edge | Documentation |
| Iron Mountain | Data Restoration & Migration Service | Backup & Restore, Archive | -Snowball
-Snowball Edge |
Documentation |
| MSP360 (formerly CloudBerry Lab) | CloudBerry Backup | Backup & Restore, Archive | -Snowball Edge | Documentation |
| Pixspan | PixMover v3.7.0 | Migration | -Snowball Edge | Documentation |
| Veritas | NetBackup 8.2+ | Backup & Restore, Archive, Disaster Recovery | -Snowball
-Snowball Edge |
Documentation |
| WANdisco | Fusion 2.12+ | Archive, Disaster Recovery, Migration | -Snowball
-Snowball Edge |
Documentation |
Learn more: