亚马逊AWS官方博客
全球规模计算 – 9.95 PFLOPS,位列 TOP500 榜单第 41 位
天气预报、基因组测序、地理分析、计算流体动力学 (CFD) 和其他类型的高性能计算 (HPC) 工作负载有赖于大量的计算能力。这些工作负载通常涉及峰值和大量并行,并且常用于实现结果的时间十分重要的情形。
旧方法
政府、资金雄厚的研究机构和“财富 500 强”公司投资数千万美元开发超级计算机,试图获得竞争优势。构建一台先进的超级计算机不仅需要专业知识、多年的规划,还需要对架构和实施的长期承诺。建成后,超级计算机必须一直保持繁忙才能证明投资的合理性,导致任务需要在队列中等待很长时间。添加容量和利用新技术不仅成本高昂,而且可能造成破坏性后果。
新方法
现在可以在云中构建虚拟超级计算机了! 与其花费十年或更长时间内投入数千万美元,不如只获取所需资源,解决问题并释放资源。您可以在需要时获得所需的计算能力,并且仅在需要时才获得。您无需将问题强加于可用资源,而是弄清楚您需要多少资源,获取这些资源,并尽可能以最自然、最迅速的方式解决问题。您无需对单处理器架构进行长达十年的投资,并且在新技术可用时,您可以轻松采用。无需长期投资,即可进行任何规模的实验,从而获得使用新兴技术(例如 GPU 和用于机器学习训练和推理的专用硬件)的经验。
Top500 竞赛
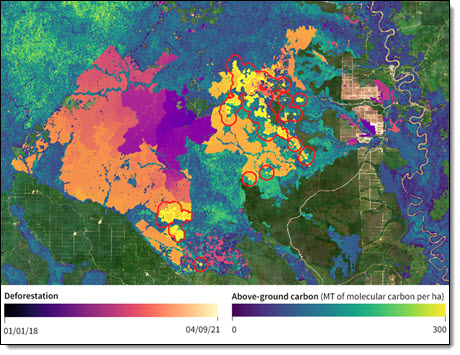 Descartes Labs 对婆罗洲加里曼丹某区域历史森林砍伐和森林碳损失估计进行了光学和雷达卫星影像分析。
Descartes Labs 对婆罗洲加里曼丹某区域历史森林砍伐和森林碳损失估计进行了光学和雷达卫星影像分析。
Amazon Web Services 客户 Descartes Labs 使用 HPC 探索世界,处理来自地面、水中和太空传感器的海量数据。该公司从一开始就是一家基于云的公司,专注于通常涉及 PB 级数据的地理空间应用程序。
首席技术官兼联合创始人 Mike Warren 告诉我,他们的愿望是永远不会受到计算能力的限制。在职业生涯早期,Mike 从事宇宙模拟工作,构建了多个集群和超级计算机,包括 Loki、Avalon 和 Space Simulator。Mike 是最早使用商用硬件构建集群的人之一,并在此过程中学到了很多东西。
从 Los Alamos National Lab 退休后,Mike 与他人共同创立了 Descartes Labs.2019 年,Descartes Labs 使用 Amazon Web Services 参加了 TOP500 竞赛,得分为 1.93 PFLOPS,在 2019 年 6 月的 TOP500 榜单上排名第 136 位。这次比赛使用了 C5 实例集群上的 41,472 个核心。值得注意的是,Mike 告诉我,他们在没有 EC2 团队的任何帮助或协调的情况下参加了这次比赛(因为 Descartes Labs 经常为他们的客户运行这种规模的生产任务,他们的账户已经有足够高的服务配额)。要了解有关本次比赛的更多信息,请阅读 Thunder from the Cloud: 40,000 Cores Running in Concert on Amazon Web Services 。这是该故事中我最喜欢的一段:
我们被授予访问 Amazon Web Services 美国东部 1 区域的一组节点的权限,从公司信用卡中收取大约 5,000 美元。HPC 民主化的潜力是显而易见的,因为以这种速度运行定制硬件的成本可能接近 2000 到 3000 万美元。更不用说 6 到 12 个月的等待时间了。
这次比赛成功后,Mike 和他的团队决定为 2021 年制定一个更有意义的计划,目标是 7.5 PFLOPS。该团队与 EC2 团队合作,在 6 月初获得了为期 48 小时的 EC2 按需容量预留。每次只使用 1024 个实例的小型尝试后,他们准备好了进行计算。他们启动了 4,096 个 EC2 实例(C5、C5d、R5、R5D、M5 和 M5d),共计 172,692 个核心。结果如下:
- Rmax – 9.95 PFLOPS。实现的实际表现:每秒将近 10 万亿次浮点运算。
- Rpeak – 15.11 PFLOPS。理论上的峰值表现。
- HPL 效率 – 65.87%。Rmax 与 Rpeak 的比率,或硬件利用率的衡量标准。
- N:7,864,320。这是为了执行 Top500 基准测试而转换的矩阵大小。N2 约为 61.84 万亿。
- P x Q:64 x 128。这是计算的参数,表示处理网格。
本次计算在 2021 年 6 月的 TOP500 榜单中位列第 41 位,在短短两年内性能提升了 417%。与其他基于 CPU 的计算相比,本次计算位于第 20 位。基于 GPU 的计算当然令人印象深刻,但将它们分开排名可以最好地进行比较。
Mike 和他的团队对结果非常满意,并相信该计算展现出了云对于任何规模的 HPC 任务的力量和价值。Mike 指出,在 1993 年占据榜首位置的 Thinking Machines CM-5(曾在《侏罗纪公园》中客串)实际上比单个 Amazon Web Services 核心还慢!
本次计算于 6 月 4 日太平洋标准时间上午 11:56 结束。24 分钟后,于下午 12:20,集群已关闭,所有实例都已停止。这就是按需超级计算的力量!
想象一下 Beowulf Cluster
回顾 Slashdot 早期,每篇引用当时令人印象深刻的硬件的帖子都必然会包含对“想象一下 Beowulf 集群”效果的评论。 今天,您可以轻松想象(然后启动)几乎任何规模的集群,并用来满足您的大规模计算需求。
如果您有可以使用 Amazon Web Services 云的速度和灵活性解决的超级计算问题,现在是时候发挥您的想象力了! 以下是一些可帮助您入门的资源:
- Amazon Web Services 高性能计算 (HPC) 页面。
- Amazon HPC 资源。
- Amazon HPC 博客。
- AmazonHPC 研讨会。
- Amazon ParallelCluster。
- Amazon 高性能计算能力合作伙伴。
恭喜!
在此祝贺 Mike 和他的 Descartes Labs 团队取得了这一惊人的成就! 几十年来,Mike 一直致力于向世界证明,可以使用大规模的商品硬件和软件构建超级计算机,并且他已经用事实做出了证明。

要了解有关此次比赛和 Descartes Labs 的更多信息,请阅读 Descartes Labs Achieves #41 in TOP500 with Cloud-based Supercomputing Demonstration Powered by Amazon, Signaling New Era for Geospatial Data Analysis at Scale(Descartes Labs 凭借 Amazon Web Services 支持的云计算超级计算演示在 TOP500 榜单中排名第 41 位,这标志着大规模地理空间数据分析的新时代)。
– Jeff;