亚马逊AWS官方博客
通过 Amazon SageMaker JumpStart 在基础模型中使用检索式增强生成实现问答
近日,我们宣布推出示例 notebook,这些 notebook 通过 Amazon SageMaker JumpStart 在大型语言模型(LLM)中使用基于检索式增强生成(RAG)的方法来演示问答任务。通过在 LLM 中使用 RAG 生成文本,您可以将特定的外部数据作为上下文的一部分提供给 LLM,从而生成特定领域的文本输出。
JumpStart 是一个机器学习(ML)中心,有助于您加快机器学习之旅。JumpStart 提供了许多预训练的语言模型(称为基础模型),有助于您执行文章摘要、问题解答、对话生成和图像生成等任务。
在这篇文章中,我们将说明 RAG 及其优势,并演示如何快速使用示例 notebook,通过 Jumpstart 在 LLM 中使用 RAG 实现来解决问答任务。我们将演示两种方法:
- 如何利用开源 LangChain 库和 Amazon SageMaker 端点用几行代码解决问题
- 如何使用 SageMaker KNN 算法,利用 SageMaker 端点对大规模数据进行语义搜索
LLM 与限制
LLM 在大量非结构化数据上进行了训练,非常适合生成一般文本。LLM 可以通过在庞大的自然语言数据语料库上训练参数来存储事实知识。
使用现成的预训练 LLM 有一些限制:
- 这种模型通常是离线训练的,因此模型与最新信息无关(例如,2011-2018 年训练的聊天机器人没有关于 COVID-19 的信息)。
- 这种模型仅通过查询参数中存储的信息进行预测,导致可解释性较差。
- 这种模型主要是在一般领域的语料库上进行训练,因此在特定领域的任务中效果较差。在某些情况下,您希望模型根据特定数据而不是通用数据生成文本。例如,医疗保险公司可能希望自己的问答机器人使用企业文档存储库或数据库中存储的最新信息来回答问题,这样答案就会准确无误,并能反映公司独特的业务规则。
目前,在 LLM 中引用特定数据有两种常用方法:
- 在模型提示中插入数据作为上下文,以此提供模型在创建结果时可以使用的信息
- 通过提供包含提示和完成对的文件对模型进行微调
基于上下文的方法所面临的挑战是,模型的上下文大小有限,将所有文档作为上下文纳入模型的上下文大小可能不合适。根据所使用的模型,如果上下文较大,还可能需要额外费用。
就微调方法而言,生成格式正确的信息既费时又费钱。此外,如果用于微调的外部数据经常变化,就意味着需要经常进行微调和再训练,才能得出准确的结果。频繁的训练会影响产品上市速度,并增加整体解决方案的成本。
为了证明这些限制,我们使用了 LLM Flan T5 XXL 模型,并提出了以下问题:
您将获得以下输出:
如您所见,响应并不准确。正确答案应该是所有 SageMaker 实例都支持 Managed Spot Training。
我们尝试了同样的问题,但在提问的同时传递了更多的上下文信息:
这次我们得到了以下响应:
响应较好,但仍不准确。但是,在实际生产使用案例中,用户可能会发送各种查询,为了提供准确的响应,您可能希望将全部或大部分可用信息作为静态上下文的一部分,以创建准确的响应。因此,使用这种方法,我们可能会遇到上下文大小限制的约束,因为即使与所提问题无关的信息也会作为上下文的一部分发送。这时,您可以使用基于 RAG 的方法,为用户的查询创建可扩展的准确响应。
检索式增强生成
为了解决我们讨论过的限制,我们可以将检索式增强生成(RAG)与 LLM 一起使用。RAG 可从语言模型外部检索数据(非参数),并通过在上下文中添加相关检索数据来增强提示。RAG 模型是 Lewis 等人于 2020 年提出的一种模型,其中参数存储器是预训练的 seq2seq 模型,非参数存储器是 Wikipedia 的密集矢量索引,可通过预训练的神经检索器进行访问。
在 RAG 中,外部数据可以来自多个数据源,如文档存储库、数据库或 API。第一步是转换文档和用户查询的格式,以便进行比较和相关性搜索。为了使相关性搜索的格式具有可比性,我们使用嵌入式语言模型将文档集合(知识库)和用户提交的查询转换为数字表示。嵌入本质上是文本中概念的数字表示。接下来,根据用户查询的嵌入,通过在嵌入空间中进行相似性搜索,在文档集合中识别出相关文本。然后,在用户提供的提示中附加搜索到的相关文本,并添加到上下文中。现在,提示被发送到 LLM,由于上下文中除了原始提示信息外,还有相关的外部数据,因此模型的输出是相关和准确的。
要维护参考文档的最新信息,可以异步更新文档并更新文档的嵌入表示形式。这样,更新后的文档将用于生成未来问题的答案,以提供准确的响应。
下图显示了将 RAG 与 LLM 配合使用的概念流程。
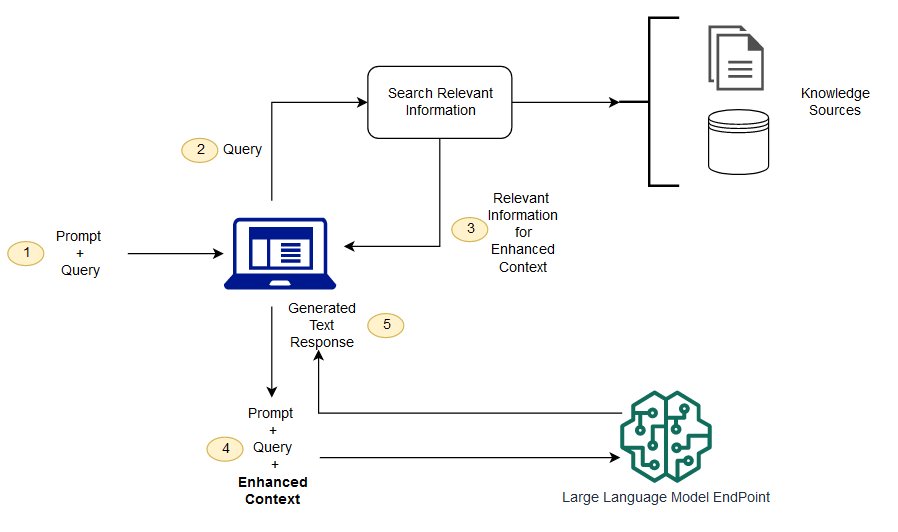
在这篇文章中,我们将演示如何通过以下步骤实现一个问答应用程序:
- 使用 SageMaker GPT-J-6B 嵌入模型为知识库中的每个文档生成嵌入内容。
- 根据用户查询,识别出最相关的前 K 个文档。
- 对于您的查询,使用相同的嵌入模型生成查询的嵌入内容。
- 使用内存中 FAISS 搜索在嵌入空间中搜索最相关的前 K 个文档的索引。
- 使用索引检索相应的文档。
- 使用检索到的相关文档作为提示和问题的上下文,并将该上下文发送给 SageMaker LLM 以生成响应。
我们演示了以下方法:
- 如何利用 SageMaker LLM、嵌入式端点和开源库 LangChain 在几行代码内完成问答任务。特别是,我们使用了两个 SageMaker 端点,分别用于 LLM(Flan T5 XXL)和嵌入模型(GPT-J 6B),使用的矢量数据库是内存中的 FAISS。有关更多详细信息,请参阅 GitHub 存储库。
- 如果内存中的 FAISS 不适合您的大型数据集,我们会为您提供 SageMaker KNN 算法来执行语义搜索,该算法也使用 FAISS 作为底层搜索算法。有关详细信息,请参阅 GitHub 存储库。
下图描述了解决方案架构。

使用 LangChain 的基于 JumpStart RAG 的实现 notebook
LangChain 是一个开源框架,用于开发由语言模型支持的应用程序。LangChain 为许多不同的 LLM 提供了通用接口。该框架还能让开发人员更轻松地将各种 LLM 链接起来,构建功能强大的应用程序。LangChain 为内存提供了一个标准接口,并提供了一系列内存实现,以便在代理或链调用之间保持状态。
LangChain 还有许多其他实用功能,可以提高开发人员的工作效率。这些功能包括:使用提示模板中的变量协助自定义提示的提示模板、用于构建端到端应用程序的代理、用于链中搜索和检索步骤的索引等等。要进一步了解 LangChain 的功能,请参阅 LangChain 文档。
创建 LLM 模型
第一步,部署您选择的 JumpStart LLM 模型。在本演示中,我们使用的是 Jumpstart Flan T5 XXL 模型端点。有关部署说明,请参阅 Amazon SageMaker JumpStart 中的 Flan-T5 根基模型零样本提示。根据您的使用案例,您还可以部署其他经过指令调整的模型,如 Flan T5 UL2 或 BloomZ 7B1。有关详细信息,请参阅示例 notebook。
要将 SageMaker LLM 端点与 LangChain 一起使用,我们需要使用 langchain.llms.sagemaker_endpoint.SagemakerEndpoint,此项抽象了 SageMaker LLM 端点。我们需要对请求和响应有效载荷进行转换,如下面的 LangChain SageMaker 集成代码所示。请注意,您可能需要根据您选择使用的 LLM 模型的 content_type 和 accepts 格式来调整 ContentHandler 中的代码。
创建嵌入模型
接下来,我们需要准备好嵌入式模型。我们将 GPT-J 6B 模型部署为嵌入模型。如果使用的是 JumpStart 嵌入模型,则需要自定义 LangChain SageMaker 端点嵌入类,并转换模型请求和响应,以便与 LangChain 集成。有关详细实现,请参阅 GitHub 存储库。
使用 LangChain 文档加载器加载特定领域的文档并创建索引
我们使用 LangChain 中的 CSVLoader 软件包将 CSV 格式的文档加载到文档加载器中:
接下来,我们使用 TextSplitter 预处理数据以进行嵌入,并使用 SageMaker 嵌入模型 GPT-J -6B 创建嵌入内容。我们将嵌入内容存储在 FAISS 矢量存储中以创建索引。我们利用该索引来查找语义上与用户查询相似的相关文档。
下面的代码显示了 LangChain 中的 VectorstoreIndexCreator 类是如何通过几行代码完成所有这些步骤的,从而使用 RAG 创建简洁的问答实现:
使用索引搜索相关上下文并将上下文传递给 LLM 模型
接下来,在创建的索引上使用查询方法,并传递用户的问题和 SageMaker 端点 LLM。LangChain 会选择最接近的前四个文档(K=4),并传递从文档中提取的相关上下文,以生成准确的响应。请参阅以下代码:
我们在 Flan T5 XXL 中使用基于 RAG 的方法得到以下查询响应:
与我们之前演示的使用其他方法得到的响应相比,该响应看起来更准确,之前使用的方法没有上下文或静态上下文,而这些上下文可能并不总是相关的。
使用 SageMaker 和 LangChain 实现具有更多定制的 RAG 的替代方法
在本节中,我们将向您展示使用 SageMaker 和 LangChain 实现 RAG 的另一种方法。这种方法可以灵活地为文档中的相关性搜索配置 top K 参数。这种方法还允许您使用提示模板的 LangChain 功能,让您可以轻松地对提示创建进行参数化,而不是对提示进行硬编码。
在下面的代码中,我们显式地使用 FAISS,利用 SageMaker GPT-J-6B 嵌入模型为知识库中的每个文档生成嵌入。然后,我们根据用户查询找出最相关的前 K(K=3)个文档。
接下来,我们使用一个提示模板,并将该模板与 SageMaker LLM 相链接:
我们使用 LangChain 链将找到的前三个(K=3)相关文档作为上下文发送给提示:
通过这种 RAG 实现方法,我们能够利用 LangChain 提示模板的额外灵活性,并使用 top K 超参数自定义相关性匹配搜索的文档数量。
使用 SageMaker KNN 的基于 JumpStart RAG 的实现 notebook
在本节中,我们使用 KNN 算法实现基于 RAG 的方法来查找相关文档,以创建增强的上下文。在这种方法中,我们没有使用 LangChain,而是使用了相同的数据集 Amazon SageMaker FAQ 作为知识文档,嵌入了 GPT-J-6B 和 LLM Flan T5 XXL 模型,就像我们在之前的 LangChain 方法中所做的那样。
如果您有一个大型数据集,SageMaker KNN 算法可以为您提供有效的语义搜索。SageMaker KNN 算法也使用 FAISS 作为底层搜索算法。此解决方案的 notebook 可以在 GitHub 上找到。
首先,我们以与上一节相同的方式部署 LLM Flan T5 XXL 和 GPT-J 6B 嵌入模型。对于知识数据库中的每条记录,我们使用 GPT-J 嵌入模型生成一个嵌入矢量。
接下来,我们使用 SageMaker KNN 训练作业为知识数据的嵌入编制索引。用于编制数据索引的底层算法是 FAISS。我们想找到最相关的前五个文档,因此将 TOP_K 变量设置为 5。我们为 KNN 算法创建估计器,运行训练作业,并部署 KNN 模型来查找与查询匹配的前五个文档的索引。请参阅以下代码:
接下来,我们使用 GPT-J-6B 嵌入模型创建查询的嵌入表示,该模型曾用于创建知识库文档的嵌入:
然后,我们使用 KNN 端点,并将查询的嵌入信息传递给 KNN 端点,以获取前 K 个最相关文档的索引。我们使用索引来检索相应的文本文档。接下来,我们将文档连接起来,确保不超过允许的最大上下文长度。请参阅以下代码:
现在到了最后一步,我们将查询、提示和包含相关文档中文本的上下文结合起来,并将这些信息传递给文本生成 LLM Flan T5 XXL 模型以生成答案。
我们在 Flan T5 XXL 中使用基于 RAG 的方法得到以下查询响应:
清理
确保在不使用此 notebook 中创建的端点时删除这些端点,以避免再次产生费用。
总结
在这篇文章中,我们演示了使用两种方法(LangChain 和内置的 KNN 算法),在 LLM 中实现基于 RAG 的方法来完成问答任务。基于 RAG 的方法通过动态提供通过搜索文档列表创建的相关上下文,优化了使用 Flan T5 XXL 生成文本的准确性。
您可以在 SageMaker 中按原样使用这些 notebook,也可以根据自己的需要进行定制。要进行定制,您可以在知识库中使用自己的文档集,使用 OpenSearch 等其他相关性搜索实现,以及使用 JumpStart 上提供的其他嵌入模型和文本生成 LLM。
我们期待着看到您使用基于 RAG 的方法在 JumpStart 上构建什么!
关于作者
 Xin Huang 博士是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的高级应用科学家。他专注于开发可扩展的机器学习算法。他的研究兴趣是自然语言处理、表格数据的可解释深度学习以及非参数时空聚类的稳健分析。他曾在 ACL、ICDM、KDD Conference 和 Royal Statistical Society: Series A 上发表过多篇论文。
Xin Huang 博士是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的高级应用科学家。他专注于开发可扩展的机器学习算法。他的研究兴趣是自然语言处理、表格数据的可解释深度学习以及非参数时空聚类的稳健分析。他曾在 ACL、ICDM、KDD Conference 和 Royal Statistical Society: Series A 上发表过多篇论文。
 Rachna Chadha 是 AWS 战略客户部的人工智能/机器学习首席解决方案架构师。Rachna 是一位乐观主义者,她相信以合乎道德和负责任的方式使用人工智能可以改善未来社会,带来经济和社会繁荣。在业余时间,Rachna 喜欢与家人共度时光、徒步旅行和听音乐。
Rachna Chadha 是 AWS 战略客户部的人工智能/机器学习首席解决方案架构师。Rachna 是一位乐观主义者,她相信以合乎道德和负责任的方式使用人工智能可以改善未来社会,带来经济和社会繁荣。在业余时间,Rachna 喜欢与家人共度时光、徒步旅行和听音乐。
 Kyle Ulrich 博士是 Amazon SageMaker 内置算法团队的应用科学家。他的研究兴趣包括可扩展的机器学习算法、计算机视觉、时间序列、非参贝叶斯和高斯过程。他在杜克大学获得博士学位,曾在 NeurIPS、Cell 和 Neuron 上发表过论文。
Kyle Ulrich 博士是 Amazon SageMaker 内置算法团队的应用科学家。他的研究兴趣包括可扩展的机器学习算法、计算机视觉、时间序列、非参贝叶斯和高斯过程。他在杜克大学获得博士学位,曾在 NeurIPS、Cell 和 Neuron 上发表过论文。
 Hemant Singh 是一名机器学习工程师,拥有 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法方面的经验。他在库兰特数学科学学院获得硕士学位,在印度理工学院德里分校获得理工学士学位。他在研究自然语言处理、计算机视觉和时间序列分析领域的各种机器学习问题方面拥有丰富的经验。
Hemant Singh 是一名机器学习工程师,拥有 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法方面的经验。他在库兰特数学科学学院获得硕士学位,在印度理工学院德里分校获得理工学士学位。他在研究自然语言处理、计算机视觉和时间序列分析领域的各种机器学习问题方面拥有丰富的经验。
 Manas Dadarkar 是一名软件开发经理,负责 Amazon Forecast 服务的工程设计。他热衷于机器学习的应用,以及让所有人都能轻松采用机器学习技术并将机器学习部署到生产环境中。工作之余,他有多种兴趣爱好,包括旅游、阅读以及与朋友和家人共度时光。
Manas Dadarkar 是一名软件开发经理,负责 Amazon Forecast 服务的工程设计。他热衷于机器学习的应用,以及让所有人都能轻松采用机器学习技术并将机器学习部署到生产环境中。工作之余,他有多种兴趣爱好,包括旅游、阅读以及与朋友和家人共度时光。
 Ashish Khetan 博士是 Amazon SageMaker 内置算法的高级应用科学家,协助开发机器学习算法。他在伊利诺伊大学厄巴纳-香槟分校获得博士学位。他是机器学习和统计推理领域的活跃研究者,曾在 NeurIPS、ICML、ICLR、JMLR、ACL 和 EMNLP 会议上发表过多篇论文。
Ashish Khetan 博士是 Amazon SageMaker 内置算法的高级应用科学家,协助开发机器学习算法。他在伊利诺伊大学厄巴纳-香槟分校获得博士学位。他是机器学习和统计推理领域的活跃研究者,曾在 NeurIPS、ICML、ICLR、JMLR、ACL 和 EMNLP 会议上发表过多篇论文。