亚马逊AWS官方博客
基于云原生构建的 HPC 平台演示
一、背景介绍
目前人工智能、生命科学、航天航空、气象石油和工业制造等应用领域对超强计算能力的需求呈井喷式增长,从最极端的神秘科学到最直接的实际问题,超级计算机在人类能力、环境和理解的提升和进步中发挥着至关重要的作用。高性能计算(HPC)是超级计算的代名词,是一种主要的探索手段,使用HPC所需的技能是多样且复杂的,而学习这样的技能并达到充分熟悉的程度,在正常实践中至少需要多年的学习和经验积累。
随着云计算的发展,HPC 的部署难度大幅度降低,与此同时HPC的形式也多种多样,有依赖于Slurm, SGE, PBS等作业调度及资源管理系统的HPC,也有结合云原生技术发展出来的托管服务如AWS Batch,不仅无需运维管理底层硬件,还能依托于全球云资源构建更大规模、硬件资源更多样的HPC集群,并且依然可以结合OpenMP或MPI构建我们的并行应用。
本文对真实的企业应用场景进行抽象,围绕AWS托管服务,基于CDK构建了完整的HPC平台,以批处理作业为示例,让终端用户能够通过web页面进行任务的提交,触发相应的Serverless工作流来调度数据拆分、批量计算、消息提醒等任务,为了更好的示例效果,本文的工作流涉及Serial、Parallel、Map、Choice等多种调度逻辑和复杂嵌套关系,根据任务对算力的要求采用了AWS Lambda、AWS Batch以演示如何与多种算力进行结合,最终结果存储在S3中,并集成了数据生命周期管理,此外基于云原生的理念,所有的计算环境我们均采用容器化方式实现,方案中也构建了CI/CD Pipeline,让用户能够通过提交代码自动化更新应用环境。
二、架构概述
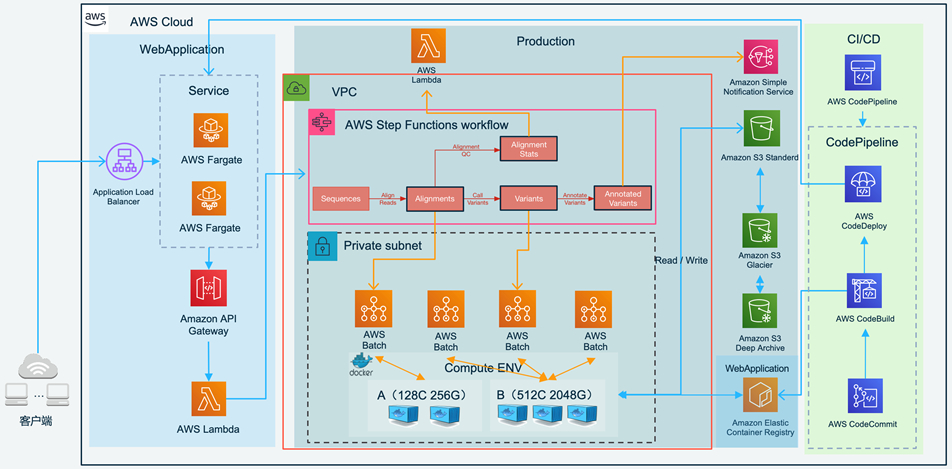
a) 前端应用
左侧 WebApplication Stack 部分为前端应用,用户任务提交,用户可指定输入、输出位置以及任务拆分等相关参数,表单提交后会同步调用后端API启动工作流进行计算任务调度。该应用采用Flask构建并运行在AWS Fargate之上,为保证高可用由AWS ALB代理多个容器并根据负载弹性伸缩,容器会通过环境变量动态获取后端API Endpoint。
b) HPC 资源管理及调度
中间Production Stack部分为任务调度及HPC计算平台,用户提交的任务参数经过lambda解析会传递给Step function状态机执行对应的工作流,工作流中包含了多种任务逻辑如Parallel、Map、Choice等以及他们之间的复杂嵌套,具体任务根据计算类型分别运行在AWS Lambda(轻量级任务)和AWS Batch(重量级任务)之上,两者计算过程中均会与S3进行数据读写交互。
c) 工作流逻辑

如上图所示,为了尽可能的演示serverless workflow工具的使用,示例采用了比较简单的数据处理逻辑,蓝色线为任务输入,黄色为输出。
Start State 输入为Json格式,包含输入、每个任务需要处理的文本行数(假设input.tsv总行数为10万行,拆分参数为1万行)。
String_Split State 会调用API提交计算任务到AWS Batch,该任务创建S3项目目录,并将文本文件拆分为10个文件,存储拆分后文件及文件列表在S3指定位置。
Job_Map State 会调用AWS Lambda读取文件列表,构建新的JSON作为后续任务的输入,包含每个子任务与其需要处理的文件。
String_Repeat 和String_Reverse State是并行的Map任务(上图左侧绿色框),均接收Job_Map的输出作为输入,根据输入的任务数组元素数量,创建对应的10个Map子任务,每个Map子任务对应一个Batch Job,如10个String_Repeat子任务分别对拆分后的文件1,2,3…10中的文本进行Repeat操作,而String_Reverse会进行Reverse操作,输出结果会添加repeat/reverse前缀。
Map任务的所有子任务均结束后,会触发对应String_Repeat_Merge/String_Reverse_Merge任务,对上述结果进行合并。
所有合并任务完成后会触发Check_Output,会调用Lambda检查S3文件大小,并构造消息提醒Json输出。
Notification State会将Check_Output结果作为消息体发送给对应SNS Topic,。
Is_Complete State是Choice任务,会判断消息体中的OutputStatus字段,若为FAILED则调用Failed任务,若为SUCCESSED则结束整个工作流。
Failed State是wait任务,会延迟5s后重新调用Job_Map, 在实际应用场景中我们可对原始参数进行微调后重新调用分析流程,此处并未做任务参数修改。
对于每个任务传参的细节可参考CDK代码,此外在基因测序、新药研发等领域常见的workflow流程均可使用该服务进行编排,后续会在其它文章中给出详细示例。
d) 数据存储
持久化数据均存储在S3中,该S3桶配置了生命周期策略,如下:
Standard —30 days—> S3 Glacier
—120 days—> S3 Deep Archive
—365 days—> Expiration
e) CI/CD Pipeline
整个架构中包含两条流水线,均采用AWS Code系列构建。
1)负责构建和更新计算任务所需要的容器镜像
该流水线负责对提交的代码进行docker build,并推送镜像至ECR镜像仓库,覆盖Latest版本,在AWS Batch环境中会引用EC2启动模板,该模板会默认引用不同容器的最新版本镜像。
2)负责构建并滚动更新AWS Fargate 中运行的前端服务
该流水线除了对提交的代码进行docker build外,会通过AWS CodeBuild 滚动更新 AWS Fargate 上运行的前端服务。
三、平台部署
注:整套环境建议在Global区域(如弗吉尼亚北部、新加坡等)进行测试,由于中国区缺少AWS CodePipeline服务,暂时无法部署CICDPipeline Stack,可手动build对应镜像并推送至ECR。
a) 创建必要的Role及User
该实验需要如下权限策略,需要创建对应策略与角色,在实验环境安全情况下也可使AdministratorAccess或PowerUserAccess创建role,后续所有操作需要在附加该Role的EC2中进行,本地用户需要创建IAM User。
b) 初始化环境
- 启动配置为t3.small的EC2,选择Amazon Linux2镜像,配置admin role

- 登录EC2并配置CDK依赖环境

- Clone代码仓库配置库环境

- 修改环境变量,配置项目参数如下:
- 查看cdk stack,配置cdk部署环境
cdk ls

cdk bootstrap

c) HPC平台部署
- 部署Serverless编排及后端HPC资源
cdk deploy Production-${UserName}

- 部署过程中会收到SNS订阅邮件,点击确认订阅

d) 前端应用部署
cdk deploy WebApplication-${UserName}


e) 部署自动化流水线
- 部署CICD流水线
- 国内区域无法部署,需删除Code pipeline相关方法
#注:部署完成后需要手动更新
-
- 海外区域部署方法
cdk deploy CICDPipeline-${UserName}

f) 获取下述信息
通过deploy命令输出Codecommit地址,Web地址并记录
cdk deploy –all
 change picture
change picture四、通过CICD部署应用并测试
a) 配置CodeCommit认证
b) 前端应用部署
- 克隆代码仓库
- 修改buildspec.yml文件中的username及account-id


c) 后端应用部署
- 克隆代码仓库
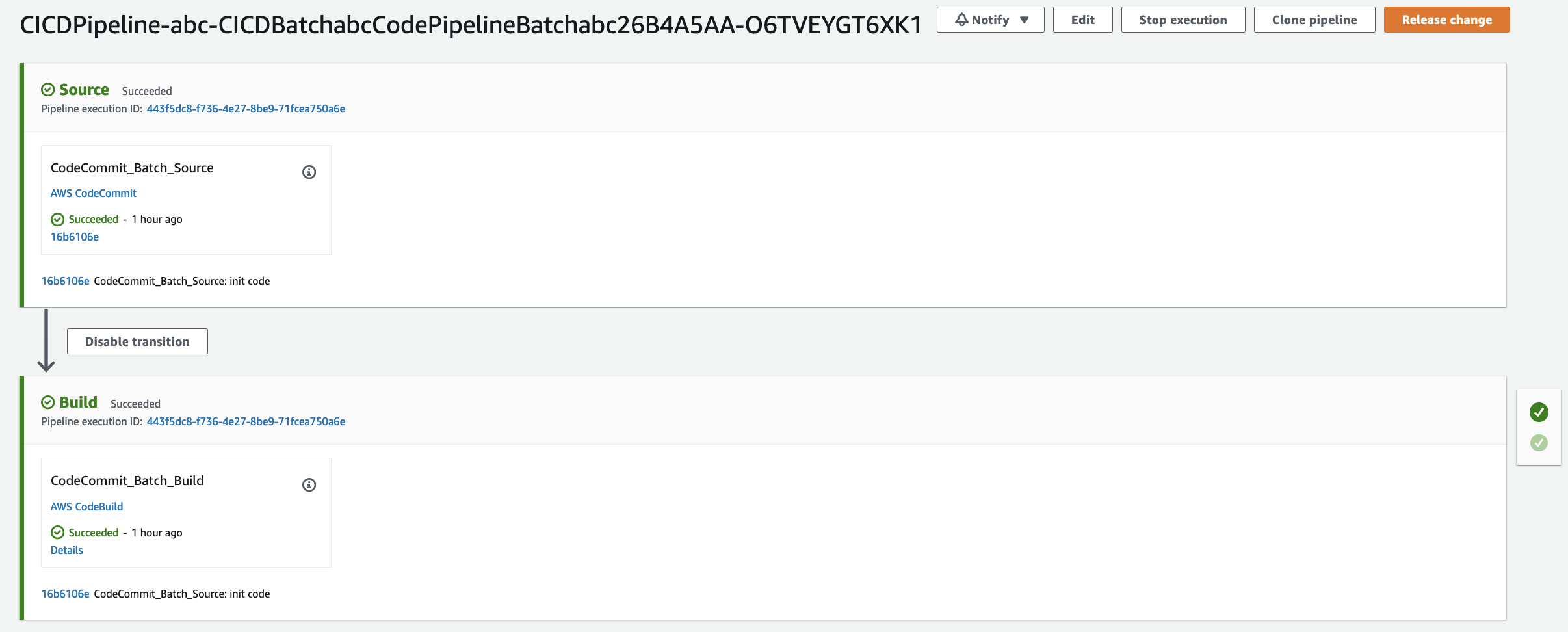
五、测试数据处理流程
a) 上传测试数据到S3 bucket

b) 页面提交任务


c) 在控制台查看AWS Step functions及AWS Batch任务调度


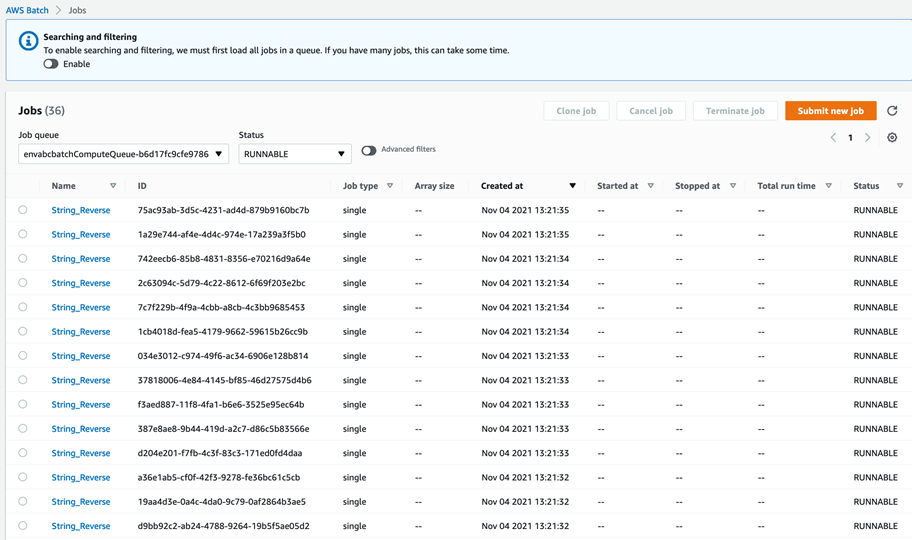
d) 分析完成后可在控制台或通过命令行检查结果



六、清理资源
a) 删除S3 bucket
b) 删除ECR
f
c) 删除stack
七、总结
该实验结合AWS Serverless及云原生的HPC服务,演示了相对完整的HPC业务场景,包括前端交互、任务自动化编排及调度、HPC计算与任务管理,以及CI/CD与基础设施代码化构建业务所需环境。对于较为成熟的业务流程,使用该架构可以大大降低运维难度与计算成本,并且提高资源利用率,保证业务的高可用与任务的全生命周期的监控。
八、参考
Amazon API Gateway官方文档:https://docs.aws.amazon.com/zh_cn/apigateway/?id=docs_gateway
AWS Lambda官方文档:https://docs.aws.amazon.com/zh_cn/lambda/?id=docs_gateway
Amazon S3官方文档:https://docs.aws.amazon.com/zh_cn/s3/?id=docs_gateway
Amazon SQS官方文档:https://docs.aws.amazon.com/zh_cn/sqs/?id=docs_gateway
Amazon DynamoDB官方文档:https://docs.aws.amazon.com/zh_cn/dynamodb/?id=docs_gateway
AWS Batch官方文档:https://docs.aws.amazon.com/zh_cn/batch/?id=docs_gateway
Amazon ECR官方文档:https://docs.aws.amazon.com/zh_cn/ecr/?id=docs_gateway
Amazon ECS官方文档:https://docs.aws.amazon.com/zh_cn/ecs/?id=docs_gateway
Amazon SNS官方文档:https://docs.aws.amazon.com/zh_cn/sns/?id=docs_gateway
AWS Step functions官方文档:https://docs.aws.amazon.com/zh_cn/step-functions/?id=docs_gateway
AWS Cloud Development Kit (CDK):https://docs.aws.amazon.com/zh_cn/cdk/?id=docs_gateway