亚马逊AWS官方博客
消除复杂性以提高业务绩效:Bridgewater Associates 如何在 AWS 上构建安全、可扩展且基于 Spark 的研究服务
Bridgewater 的核心使命是通过分析市场驱动因素来理解世界的运作方式,并将这种理解转化为高质量的投资组合,为我们的客户提供投资建议。在 Bridgewater Technology 内,我们努力使我们的研究人员在他们最擅长的领域尽可能提高工作效率:建立对全球市场的基本理解。这意味着不再需要处理底层 IT 基础设施,而是专注于构建和改进他们的投资理念。
在这篇博文中,我们从四个方面考察了我们的专有服务。我们探讨面临哪些业务挑战,如何达到高安全标准,如何进行扩展以满足业务需求,以及如何以经济高效的方式完成所有这些工作。
挑战
我们的研究人员对开发和测试其投资逻辑所需的计算需求在不断增长。计算能力的持续和积极增长是我们最初决定迁移到公有云的驱动力。
利用 AWS Cloud 的规模,我们可以生成投资信号和对世界趋势的看法,而这在本地是不可能做到的。当我们第一次将此分析工作负载迁移到 AWS 时,我们在 Amazon Elastic Compute Cloud(Amazon EC2)以及Elastic Load Balancing、AWS Auto Scaling 和 Amazon Simple Storage Service(Amazon S3)等其他服务上进行了构建以提供核心功能。不久之后,我们迁移到了 AWS Nitro System,完成作业的速度提高了 20%,这使我们的研究团队能够更快地迭代他们的投资想法。
两年前我们开始了进一步的发展,当时我们采用 Apache Spark 作为投资逻辑执行服务的底层计算引擎。这有助于简化我们的分析管道,消除重复,并与我们为研究人员开发的许多插件脱钩。我们没有自己运行 Apache Spark,而是选择 Amazon EMR 作为托管的 Spark 平台。但是,我们很快发现 Amazon EMR on EC2 并不适合我们想要的使用方式。例如,我们无法预测研究人员何时提交作业,因此为了避免让研究人员等待创建和引导全新 EMR 集群,我们使用了长期 EMR 集群,这迫使许多不同的作业在同一个集群上运行。但由于单个 EMR 集群只能存在于单个可用区中,因此我们的集群被限制为只能在该可用区中启动实例。在我们运营规模庞大的情况下,各可用区开始用尽我们所需的实例容量来满足我们的需求。尽管我们可以跨不同的可用区启动许多不同的集群,但这将使我们在较高的级别处理作业调度,而这正是使用 Amazon EMR 和 Spark 的重点。此外,为了尽可能提高成本效益,我们希望根据需求不断扩展集群中的节点数量,因此,我们每天要处理数千个节点。这种持续不断的节点变动会导致作业失败,并给我们的团队带来额外的运营开销。
我们向 AWS 提出了这些疑虑,AWS 带头推动解决这些问题。AWS 与我们密切合作,以了解我们的使用案例和作业失败的影响,并坚持不懈地与我们合作以解决这些挑战。我们与 Amazon EMR 团队合作,将问题缩小到我们的积极扩展模式,这项服务当时无法处理该问题。在短短几个月的时间里,Amazon EMR 团队对扩展机制进行了多项服务改进,以满足我们以及许多其他 AWS 客户的需求。
在与 Amazon EMR 团队就这些问题密切合作的同时,AWS 团队向我们通报了 Amazon EMR on EKS 的开发情况,这是一项托管服务,使我们能够在 Amazon Elastic Kubernetes Service(Amazon EKS)上运行 Spark 工作负载。Amazon EKS 是 Bridgewater 各业务部门的战略平台,在使用 EMR on EKS 对我们的工作负载进行概念验证之后,很明显,该平台更适合我们的使用案例,更符合我们的战略方向。迁移到 EMR on EKS 后,我们现在可以利用多个可用区的容量,提高应对 EMR 集群问题或更广泛服务事件的弹性,同时仍能达到我们的高安全标准。
安全
我们服务的另一个重要方面是确保其保持适当的安全态势。除其他担忧外,Bridgewater 严格划分了获得不同投资理念的途径,我们必须防范恶意内部人员试图窃取我们知识产权或以其他方式损害 Bridgewater 的可能性。为了在速度和安全性之间取得平衡,我们设计了安全控制措施来防御潜在的恶意作业,同时使我们的研究人员能够快速迭代他们的代码。Spark 的 Kubernetes 后端设计使这变得更加复杂。在我们的例子中,Spark 驱动程序正在运行任意且不受信任的代码,必须授予 Kubernetes 基于角色的访问控制(RBAC)权限才能创建 Kubernetes 容器组(pod)。创建容器组(pod)的能力非常强大,可能会导致权限升级。
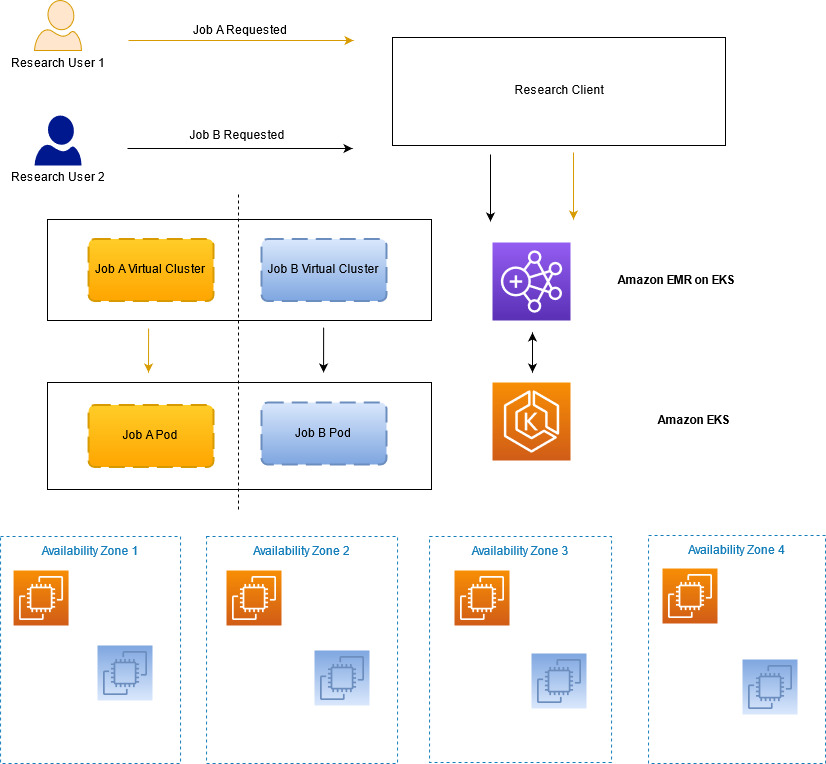
我们的第一层隔离是在其自身的 Kubernetes 命名空间中运行每项作业(因此也可以在其自身的 EMR on EKS 虚拟集群中运行每项作业)。当作业准备提交时,系统会创建名称空间和虚拟集群,并在作业完成时删除。这可以防止一项作业直接干扰另一项作业,但仍有其他媒介需要防御。例如,Spark 驱动程序不应使用以 root 身份运行的容器创建容器组(pod),也不应从未经批准的库获取映像。为此,我们首先调查了 PodSecurityPolicies。但是,它们无法解决我们所有的使用案例(例如限制容器映像的提取位置),并且它们当前正被弃用,最终将被删除。我们转而使用 Open Policy Agent(OPA)Gatekeeper,它提供了一种灵活的方法来用代码编写策略,从而可以执行更复杂的授权决策,并允许我们实施所需的控制套件。我们还与 AWS 服务团队合作,进一步加深了防御措施,例如确保 EMR on EKS 创建的所有容器组(pod)丢弃了所有 Linux 功能,然后我们可以通过 Gatekeeper 强制执行这些功能。
下图说明了我们如何在研究服务中维持所需的作业分离。
扩展
我们向 Spark on Amazon EMR 转变进而演变到 EMR on EKS 的最大动机之一是,通过根据需求积极扩展来提高资源利用效率。我们对市场和经济的基本因果关系的理解得益于我们系统化的高性能计算 Spark 网格。我们运行模拟的规模不断扩大,需要一种能够纵向扩展并满足未来几年可预见的业务需求的架构。
我们的平台运行两种类型的作业:临时交互式作业和计划的批处理作业。每种类型的作业都有其自身的扩展复杂性,并且都受益于向 EMR on EKS 的演变。可以在整个工作时间内随时提交临时作业,而模拟则确定需要多少计算容量。例如,一项特定作业可能需要一个 EC2 实例或 100 个 EC2 实例。这可能意味着需要在几分钟内启动或关闭数百个 EC2 实例。计划的批处理作业会通过预先确定的模拟全天定期运行,这同样意味着需要启动或关闭数百个 EC2 实例。总的来说,在几分钟内扩展和缩减数百个 EC2 实例是很常见的,我们需要一种能够满足这些业务要求的解决方案。
对于这个具体问题,我们需要一种能够以每分钟数百个 EC2 实例的速度处理积极扩展事件的解决方案。此外,当以这种规模运行时,使实例类型多样化并将作业分散在多个可用区非常重要。EMR on EKS 使我们能够在跨多个可用区的 EKS 集群上运行完全托管的 Spark 作业,并提供为 Amazon EKS 选择一组异构实例类型的选项。使单个 EKS 集群跨多个可用区,这样我们便能利用整个区域的计算容量,从而提高此工作负载的实例多样性和可用性。由于 Spark 作业在 Amazon EKS 上的容器中运行,因此我们可以轻松地在 EKS 集群内交换实例类型,或在同一集群中运行不同类型的实例。凭借这些功能,我们能够定期将生产服务扩展到大约 1,600 个 EC2 实例,峰值时总共有 25,000 个核心,每天运行 3,000 项作业。
最后,在 2021 年底,我们进行了一些扩展测试,以了解我们服务的实际限制。我们很高兴地告诉大家,在计算和模拟运行方面,我们能够将服务规模扩大到正常日常规模的三倍。此练习证实,我们将能够满足不断增长的业务需求,而无需为此投入额外的工程资源。
成本管理
除了显著提高扩展能力之外,我们还能够设计出极具成本效益的解决方案。在 EMR on EKS 之前,对于 Spark 作业,我们提供两种选项:要么在 Amazon EC2 上自我管理,要么使用 Amazon EMR on EC2。在 Amazon EC2 上自我管理意味着我们需要管理在节点上调度作业的复杂性,管理 Spark 集群本身,并开发一个单独的应用程序,以便在 Spark 作业运行以扩展工作负载时预置和停止 EC2 实例。Amazon EMR on EC2 提供托管服务,用于在 Amazon EC2 上运行 Spark 工作负载。但是,对于像我们这样需要在多个可用区运行并且已在 Kubernetes 上拥有技术足迹的客户来说,EMR on EKS 更有意义。
迁移到 EMR on EKS 使我们能够在提交作业时动态扩展,从而节省大量成本。模拟能力在几分钟的范围内大小合适;其他解决方案无法做到这一点。此外,我们对 Amazon EC2 Compute Savings Plans 的投资可以节约成本并能灵活满足需求;我们只需指定在特定区域承诺的计算小时数,其余部分交由 AWS 处理即可。您可以在 Amazon EKS 上的 Amazon EMR 中阅读有关 EMR on EKS 的成本效益的更多信息,可使 Spark 工作负载的成本降低多达 61%,性能提升多达 68%。
未来前景
尽管我们目前正在满足关键用户的需求,但我们已将对未来服务的几项改进列为优先事项。首先,我们计划用 Karpenter 替换 Kubernetes 集群自动扩缩程序。鉴于我们积极而频繁的计算扩展,我们发现使用集群自动扩缩程序可能会意外停止某些作业。我们每天大约经历六次这种情况。我们预计 Karpenter 将大大减少这种失效模式的发生。要了解有关 Karpenter 的更多信息,请查看 Karpenter 简介 — 开源高性能 Kubernetes 集群自动扩缩程序。
其次,我们将目前在 EC2 上运行的几项补充服务移至 EKS。这将提高我们为业务部署有意义改进的能力,并提高对服务事件的应变能力。
最后,我们正在做出长期努力,以提高对区域服务事件的应变能力。我们正在探索将业务扩展到其他 AWS 区域,这将使我们能够提高服务可用性并保持容量暴增。
结论
我们与 AWS 团队密切合作,在 AWS 上开发了安全、可扩展且成本优化的服务,使我们的研究人员能够生成更大、更复杂的投资理念,而不必担心 IT 基础设施。我们的服务在多个可用区中以接近满负荷的利用率运行基于 SPARK 的模拟,而无需担心构建或维护调度平台。最后,通过大规模使用本机 AWS 构造创建作业分离,我们能够达到并超越我们的安全基准。这给了我们极大的信心,相信我们的任务关键型数据在 AWS Cloud 中是安全的。
通过与 AWS 的密切合作,Bridgewater 有望在未来几年内预见并满足我们研究人员的严格要求;这在我们的旧数据中心或之前的架构中是无法实现的。我们的总裁兼首席技术官 Igor Tsyganskiy 最近与 AWS 就这种合作关系进行了详细交谈。有关本次讨论的视频,请查看 Merging Business and Tech – Bridgewater’s Guide to Drive Agility。
致谢
- Igor Tsyganskiy,Bridgewater 总裁兼首席技术官
- Aaron Linsky,Bridgewater 高级产品经理
- Gopinathan Kannan,Amazon Web Services 高级工程经理
- Vaibhav Sabharwal,Amazon Web Services 客户解决方案高级经理
- Joseph Marques,Amazon Web Services 高级首席工程师
- David Brown,Amazon Web Services EC2 副总裁
关于作者
 Sergei Dubinin 是 Bridgewater 的工程经理。他热衷于构建适合在生产环境中安全、稳定和高性能使用的大数据处理系统。
Sergei Dubinin 是 Bridgewater 的工程经理。他热衷于构建适合在生产环境中安全、稳定和高性能使用的大数据处理系统。
 Oleksandr Ierenkov 是 EPAM Systems 的解决方案架构师。他专注于帮助 Bridgewater 将内部分布式系统迁移到 Kubernetes 上的微服务和各种 AWS 托管服务,致力于提高运营效率。Oleksandr 是乌克兰语,相当于 Alexander。
Oleksandr Ierenkov 是 EPAM Systems 的解决方案架构师。他专注于帮助 Bridgewater 将内部分布式系统迁移到 Kubernetes 上的微服务和各种 AWS 托管服务,致力于提高运营效率。Oleksandr 是乌克兰语,相当于 Alexander。
 Anthony Pasquariello 是 AWS 驻纽约市的高级解决方案架构师。他专门为我们的高级企业客户提供现代化和安全服务。Anthony 喜欢撰写和谈论与云相关的所有内容。他拥有电气与计算机工程学士和硕士学位,目前正在攻读工商管理硕士学位。
Anthony Pasquariello 是 AWS 驻纽约市的高级解决方案架构师。他专门为我们的高级企业客户提供现代化和安全服务。Anthony 喜欢撰写和谈论与云相关的所有内容。他拥有电气与计算机工程学士和硕士学位,目前正在攻读工商管理硕士学位。
 Illia Popov 是 EPAM Systems 的技术主管。自 2018 年以来,Illia 一直与 Bridgewater 合作,积极规划和实施向 EMR on EKS 的迁移。他很高兴能够与 AWS 密切合作,通过调整托管服务,继续为 Bridgewater 创造价值。
Illia Popov 是 EPAM Systems 的技术主管。自 2018 年以来,Illia 一直与 Bridgewater 合作,积极规划和实施向 EMR on EKS 的迁移。他很高兴能够与 AWS 密切合作,通过调整托管服务,继续为 Bridgewater 创造价值。
 Peter Sideris 是AWS 高级技术客户经理。他与我们的一些规模庞大、结构复杂的客户合作,确保他们在 AWS Cloud 中取得成功。Peter 喜欢与家人共叙天伦,养护海洋珊瑚礁,并以多种身份自愿为美国童子军服务。
Peter Sideris 是AWS 高级技术客户经理。他与我们的一些规模庞大、结构复杂的客户合作,确保他们在 AWS Cloud 中取得成功。Peter 喜欢与家人共叙天伦,养护海洋珊瑚礁,并以多种身份自愿为美国童子军服务。
 Joel Thompson 是 Bridgewater Associates 的架构师,在过去的 13 年里,他曾担任过各种技术职务,包括负责在 Bridgewater 为 AWS 的早期采用搭建一些基础。他热衷于解决复杂问题,以安全地为企业创造价值。工作之余,Joel 喜爱滑雪,参与创办了 fwd:cloudsec 云安全会议,并喜欢与亲朋好友一起旅行。
Joel Thompson 是 Bridgewater Associates 的架构师,在过去的 13 年里,他曾担任过各种技术职务,包括负责在 Bridgewater 为 AWS 的早期采用搭建一些基础。他热衷于解决复杂问题,以安全地为企业创造价值。工作之余,Joel 喜爱滑雪,参与创办了 fwd:cloudsec 云安全会议,并喜欢与亲朋好友一起旅行。