亚马逊AWS官方博客
条条大路通罗马 —— 使用redis-py访问Amazon ElastiCache for redis集群
一.前言
什么是 Redis?
Redis是一个非常流行的开源(BSD 许可)内存型数据库,通常用作数据库、缓存或消息代理。 为了达到最佳性能,Redis使用内存数据集。根据用户场景,Redis可以通过定期将数据集转储到磁盘,或者将每个指令附加到日志来持久化您的数据。
什么是Redis集群?
Redis可以以两种模式运行:启用集群模式和禁用集群模式。禁用集群模式后,Redis集群有一个保存了整个数据集的主节点,而启用集群模式后,数据集被拆分为多个主节点,称为“分片”(Shards)。每个分片由一个主分片和零或多个副本组成。使用多个分片,能存储比单节点容纳的大得多的数据集,且可通过使用多个节点来增加集群的吞吐量。
在集群模式下,Redis为每个键分配一个哈希槽来分布其数据,散列槽是一个0到16383(共 16384个)范围内的整数,使用CRC函数计算。每个分片负责处理哈希槽的子集。例如,如果有两个分片,第一个可能处理哈希槽0-8191,第二个可能处理哈希槽8192-16383。用户可随时向Redis集群添加更多的分片,但每个哈希槽只能由一个分片处理。
ElastiCache for Redis
Amazon ElastiCache是一种Web服务,即托管的分布式内存数据库。它提供了一种高性能、可扩展且经济高效的缓存解决方案,可有效消除部署和管理分布式缓存数据库的复杂性。ElastiCache支持所谓集群模式和非集群模式,具体可参照下图:

Amazon ElastiCache for Redis的特性如下:
- 自动检测节点故障并从中恢复。
- 最高支持多达500个分片(启用集群模式)。
- 与其他AWS服务集成,例如Amazon EC2、Amazon CloudWatch、AWS CloudTrail和 Amazon SNS。
- 可通过主实例和只读副本的数据同步获得高可用性,当出现问题时可以自动故障转移到只读副本。
- 可以通过使用AWS Identity and Access Management定义权限来控制对ElastiCache for Redis集群的访问。
- 通过使用Global Datastore for Redis功能,可以跨AWS区域进行完全托管、快速、可靠和安全的复制。使用此功能,您可以为ElastiCache for Redis创建跨区域只读副本集群,以实现跨AWS区域的低延迟读取和灾难恢复。
- 数据分层功能,除了将数据存储在内存中之外,还通过在每个节点中使用低成本的SSD为 Redis提供了一种高性价比方案。它非常适合定期访问20%的整体数据集的工作负载,且在访问SSD上的数据时可以容忍额外延迟的应用程序。有关详细信息,请参阅官网的数据分层。
关于 redis-py
目前业界有许多中编程语言的客户端,可用来连接到Redis集群。在本文中,我们将介绍一个基于Python的客户端 redis-py,以及介绍如何使用此客户端来访问Redis集群和非集群中的数据。
redis-py由Andy McCurdy发起的开源项目,目前已经被Redis官方收录,尽管redis-py维护得很好,但一直以来它缺乏对集群模式的支持,因此Python用户不得不选择另外一个开源项目redis-py-cluster,该项目由Grokzen开发,基于antirez的redis-rb-cluster。基于此现状,AWS积极与支持redis-py的开源社区展开合作,为该客户端添加了集群模式支持。即redis-py现在已原生支持集群模式,这意味着您可以使用redis-py与Redis Cluster交互,而无需安装任何第三方库。此特性在4.1.0-rc1中发布。

二.功能测试
1. 前置准备
此系列Redis文章中,已经有其他文章介绍过使用AWS控制台来创建ElastiCache集群等相关操作,本文则会描述如何通过AWS CLI来创建ElastiCache集群。
找到一台Linux服务器,安装Python3、pip、redis-py、AWS CLI程序,并且完成AWS CLI的配置,具体可以参考这里。安装完成后执行aws configure list,检查配置的完成。

2. 搭建测试环境
2.1 创建子网组
在创建ElastiCache集群之前,需要先创建子网组(Subnet Group),所谓子网组是VPC子网(通常是私有)的集合,ElastiCache集群将运行在这些子网中。使用AWS CLI创建ElastiCache的子网组,指令如下:
参数解释:
–cache-subnet-group-name:子网组名称
–cache-subnet-group-description:子网组描述
–subnet-ids:子网id,可填写多个,如果要开启多可用区(Multi-AZ)功能,请至少填写两个在不同可用区的子网id。
2.2 创建ElastiCache集群
使用AWS CLI命令行创建一个开启TLS和auth的ElastiCache集群,分为3个shards,每个shard由1个主节点和1个读副本节点组成,共6节点,实例类型为cache.t3.micro,版本为6.2.5,指令如下:
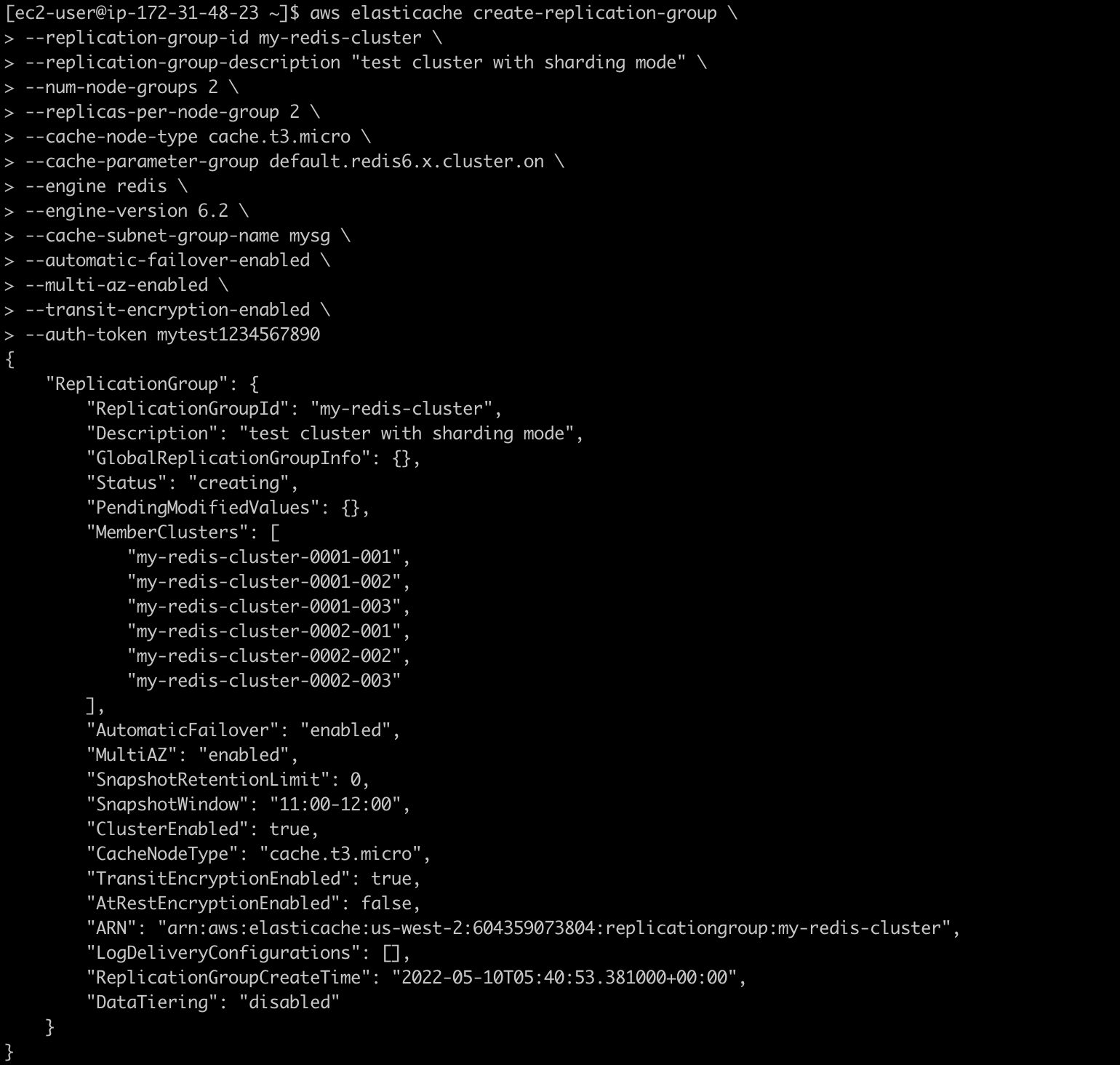
参数解释:
–replication-group-id:集群id
–replication-group-description:集群描述
–num-node-groups:shard数量
–replicas-per-node-group:每个shard中的读副本数量
–cache-node-type:节点机型
–cache-parameter-group:参数组
–engine:缓存引擎类型
–engine-version:缓存版本
–cache-subnet-group-name:子网组名称
–automatic-failover-enabled:启用故障转移
–multi-az-enabled:启用多可用区
–transit-encryption-enabled:启用传输中加密,必须与访问密码同时开启
–auth-token:访问密码,必须与传输中加密同时开启,密码规则为:
- 长度必须至少为16个字符且不超过128个字符。
- 允许的特殊字符是为!、&、#、$、^、<、>和-。
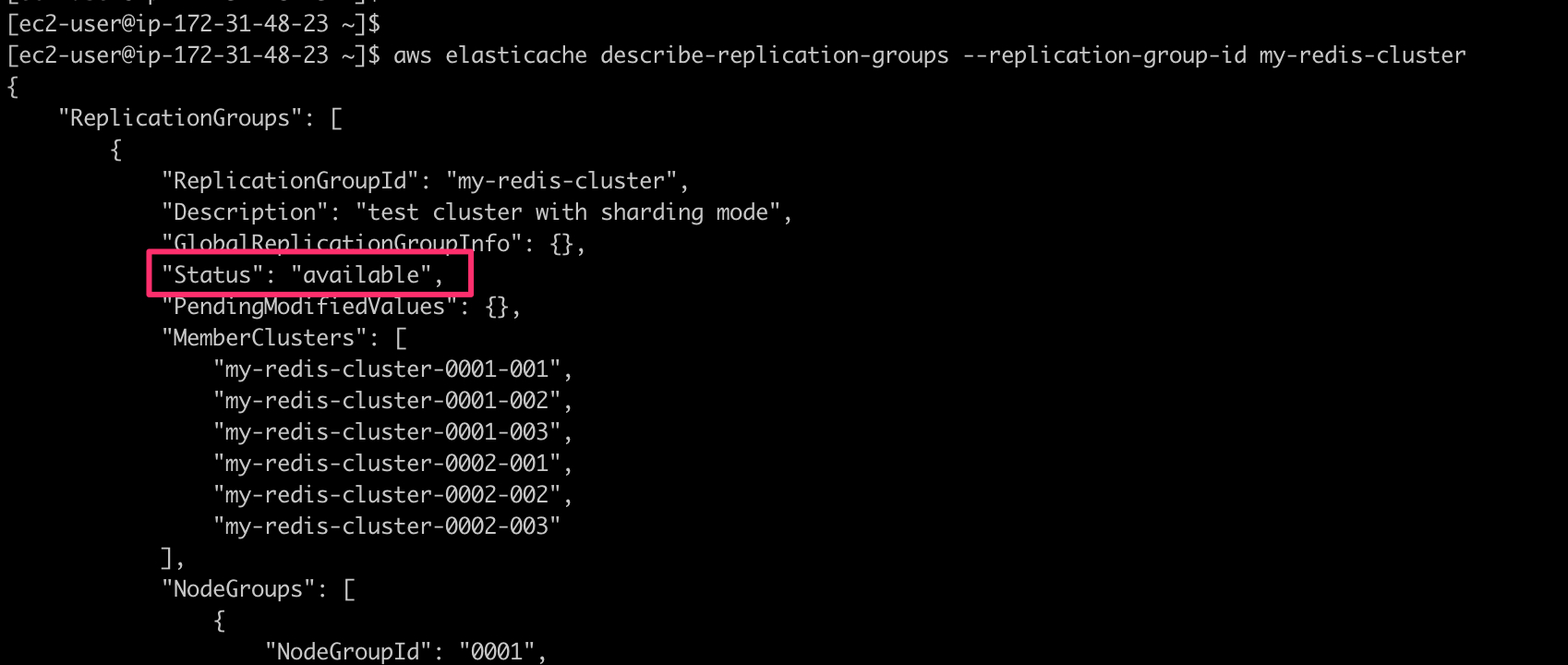
通过如下指令,反复查看集群状态,当状态由creating变为available时,则代表此ElastiCache集群创建完毕。
创建不开启TLS以及Auth的ElastiCache集群方法同上,去掉上述指令中的–transit-encryption-enabled和–auth-token两个参数即可,具体的创建过程不再复述。
2.3 创建ElastiCache Python客户端
ElastiCache集群提供了一个ConfigurationEndpoint,基于redis-py的客户端可连接到此Endpoint,来与ElastiCache集群交互,查找ConfigurationEndpoint节点的指令如下:

记录Address以及Port,供Python客户端使用;连接到开启TLS的ElastiCache集群Python客户端的代码如下:
请注意:
- 上述客户端代码基于redis-py,是用来连接ElastiCache集群类型实例的,对于ElastiCache非集群类型实例,此代码无法正常工作。
- 上述客户端代码是用来连接到开启了TLS和Auth的ElastiCache集群的,如果要求连接到未开启TLS和Auth的ElastiCache集群,请在代码中去掉ssl和password两个参数。
- 代码中没有指定数据库(db)编号,因为ElastiCache集群仅支持一个数据库,且该数据库的分配编号始终为0。
- 代码中将ElastiCache集群中ConfigurationEndpoint节点的IP/端口信息传递给客户端的构造函数,但其实可以选择集群中的任何节点。redis-py是所谓的smart客户端,其初始化流程会自动发现集群中的所有其他节点,并且能够知道哪些节是主节点,哪些是读副本。
2.4 使用ElastiCache Python客户端
常用指令
在成功连接到ElastiCache集群后,我们就可以与ElastiCache进行一些交互了,例如简单的set、get操作,具体示例代码如下:
Multi keys指令
redis-py支持集群模式下的multi-key指令,如mset和mget,但需要确保所有key都被hash到同一个槽(slot),否则将会触发RedisClusterException。Redis官方为此实现了一个称为hash tags的概念,可用于强制将这些键存储在同一个哈希槽中,具体示例如下所示:
由上述示例,可以看到hash tags强制键存储在同一个哈希槽中的实现方式为,当key中包含 {} 的时候,不对整个key做hash,而只对 {} 包括的字符串做hash。
注意:hash tags可以让不同的key拥有相同的hash值,从而分配在同一个哈希槽里;但是hash tags可能会带来集群数据分配不均的问题,需要:(1)调整不同节点中哈希槽的数量,使数据分布尽量均匀;(2)避免对热点数据使用hash tags导致的分布不均。
Cluster Pipeline
当向ElastiCache服务器发送指令时,需要等待命令到达服务器并等待响应的返回。这称为往返时间 (RTT)。当有很多指令想要执行,可以生成一个指令列表,一次性执行发送,然后收到一个响应列表,其中响应的顺序对应于请求的顺序。这样我们只为整个指令列表产生一个 、RTT,从而提升批量指令执行的性能,即所谓Pipeline。redis-py支持集群模式下的Pipeline,客户端示例代码如下:
Pipelines指令流程如下:
- 每个被缓存的pipeline指令都被分配到对应的Redis shard节点。
- 客户端向所有节点发送缓冲的指令。所有的指令都是并行发送到节点的,所以不需要在发送下一个指令之前等待上一个指令的Response。
- 客户端等待所有节点的Response。
- 所有节点的Response会被排序,对应于请求时的顺序,并最终返回给客户端。
- 注意:RedisCluster pipelines当前只支持基于key的指令,而不支持管理指令。
redis-py连接池
在集群模式下,redis-py客户端在其内部为每一个Shard都创建了一个Redis实例。这些Redis实例都维护了一个连接池,并允许客户端与Shard通信时重用连接以降低性能损耗。
Read Only模式
默认情况下,ElastiCache集群的所有读写请求都只在主节点上进行,而读副本节点是热备(Standby),只同步主节点的数据,不处理任何读请求,其作用主要是出现异常情况下的故障转移,如果有接收到读请求,读副本会向请求的客户端返回MOVE指令的响应。通过在构建RedisCluster的时候设置read_from_replicas=True参数,启用ReadOnly模式,可以让读副本也能处理读请求,来分担主节点上的读压力。需要注意的是,由于ElastiCache集群主副之间的数据复制是异步的,存在一定延迟,故开启读副本ReadOnly模式可能会导致客户端读取到脏数据。示例代码如下:
另外值得一提的是,redis-py支持使用指定目标节点的方式与ElastiCache集群交互,如可指定所有节点、主节点、读副本节点等;注意此功能仅限于非key-based的指令,具体如下述代码所示:
三.故障转移测试
本章描述ElastiCache集群的故障转移测试,主要关注在故障转移期间,ElastiCache集群和redis-py的相关表现,比如影响到的数据范围、故障转移耗费的时长、客户端是否能自动重连等问题。
测试环境配置:
ElastiCache集群:
- ElastiCache版本:6.2.5
- Multi-AZ:Enabled
- Auto-failover:Enabled
- Node type:cache.t3.small
客户端:
- EC2:Amazon Linux 2
- Python版本:3.8.5
- redis-py版本:4.3.1
测试代码:
下述代码通过redis-py连接到ElastiCache集群,并且开启ReadOnly模式,并且为了减少自动恢复的时间,设置异常retry的次数为1。然后在循环中不停写入和读取数据,每次读写间隔300毫秒。
测试场景设计:
由于1 Shard场景没有实际意义,故本测试主要覆盖2/3/4个Shards,每个Shard包含1 Primary + 2 Read Replica的场景,具体如下表格所示:
| Shards | Nodes | |
| 场景1 | 2 | 1 Primary + 2 Read Replica / Shard |
| 场景2 | 3 | 1 Primary + 2 Read Replica / Shard |
| 场景3 | 4 | 1 Primary + 2 Read Replica / Shard |
验证过程:
场景1:2 shards with 1 Primary + 2 Read Replica / Shard
测试结论:
在Shard 1中执行Test Failover,主副切换过程会经历30秒左右(多轮测试结果),在此期间Shard 1不可用;另外此时整个集群状态为fail,即Shard 2也不可用。
测试过程:
执行下述命令,触发Shard 1的Failover:
参数解释:
–replication-group-id:表示ElastiCache集群的id
–node-group-id:表示第几个shard,其值为类似”0001″、”0002″、”0003″。

当Failover被触发后,可执行如下指令查看整个Failover过程中的事件:
aws elasticache describe-events –duration 180
参数解释:
–duration:代表查询最近时间内的事件,单位为分钟。

这里从下至上详细解释下截图中的各个事件:
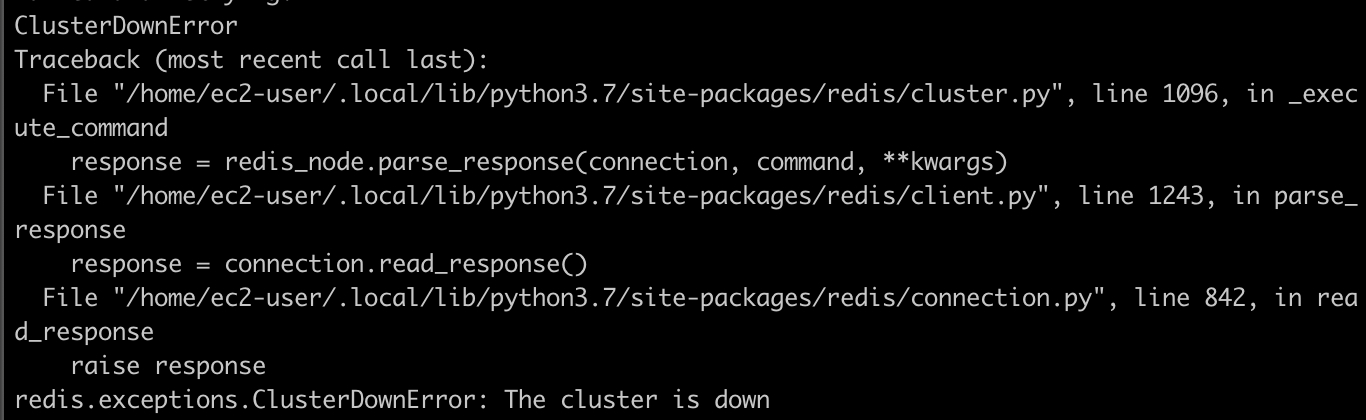
- 10点13分32秒,ElastiCache集群Shard 1的Failover动作被触发,从此时间点开始,Shard 1不可用。
此时测试脚本报错Cluster is Down,如下图,与Shard 1不可用的状态吻合。
使用redis-cli登录ElastiCache集群执行cluster info指令,可以看到此时集群的状态变为fail,如下图所示,此状态代表整个集群不可用,即Shard 2也不可用。

- 10点14分59秒,Failover动作执行完毕,可以看到读副本my-redis-cluster-0001-003被提升为了主节点。直到此时间点,Shard 1恢复可用。
此时测试脚本恢复正常,如下图,与Shard 1变为可用的状态吻合。

使用redis-cli登录ElastiCache集群执行cluster info指令,可以看到此时ElastiCache集群的状态变为ok,如下图所示,整个集群恢复可用,即Shard 2也恢复可用。

- 10点17分23秒,之前的主节点my-redis-cluster-0001-002被设置为读副本,开始从主节点复制数据。
- 10点25分4秒,my-redis-cluster-0001-002节点数据恢复结束。直到此时间点,该节点恢复可用,整个集群完全恢复正常。
在集群为2 Shards场景下的Failover测试过程中,在步骤1和步骤2之间,为什么整个集群不可用,这里笔者经过仔细研究,发现原因如下,首先介绍Failover主副切换的具体步骤:
- Replica发现自己的Master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播Failover Request信息
- 其他节点收到该信息,但只有集群中其他Shard的master能响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试Failover的Replica收集FAILOVER_AUTH_ACK
- 收到超过半数的Master回复后,Replica开始执行Failover,变为新的Master
- 清理复制链路,重置集群拓扑结构信息
- 向集群内所有节点广播
这里可以看到步骤5中,Failover的执行需要集群中其他Shard超过半数的Master投票确认,但集群中只有2个Shard,即只有2个Master,此时没有超过半数的Master可以给出投票了。
进一步猜测,整个集群不可用,是否与此时集群中没有超过半数的活跃Master相关?通过翻看Redis代码,https://github.com/redis/redis/blob/6.2/src/cluster.c 中的clusterFailoverReplaceYourMaster函数即为Failover的实现,其中有调用到函数clusterUpdateState,即对应上述步骤6的动作,进入此函数,看到代码实现为活跃Master数小于集群Master半数时,会将整个集群状态设置为Fail,具体如下图:

至此,原因找到,即Failover触发后,集群会更新拓扑结构,当发现活跃Master数小于集群Master半数时,便将整个集群设置为Fail不可用,此时集群不接受读写请求,直到Failover完成,新Master重新上线,集群恢复可用。
另外,Redis官方建议Redis集群的创建,至少需要3个Master(3 Shards),想必就是基于上述原因,故请大家尽量和保证在生产环境中的ElastiCache集群至少有3个Master (3 Shards),保证在Failover的时候,不会引起整个集群不可用。
场景2:3 shards with 1 Primary + 2 Read Replica / Shard
测试结论:
在Shard 1中执行Test Failover,主副切换过程会经历30秒左右(多轮测试结果),在此期间Shard 1不可用;其他Shard仍然可用。
测试过程:
执行下述命令,触发Shard 1的Failover,具体可参照场景1中的描述。
当Failover被触发后,可执行如下指令查看整个Failover过程中的事件,具体如下图:
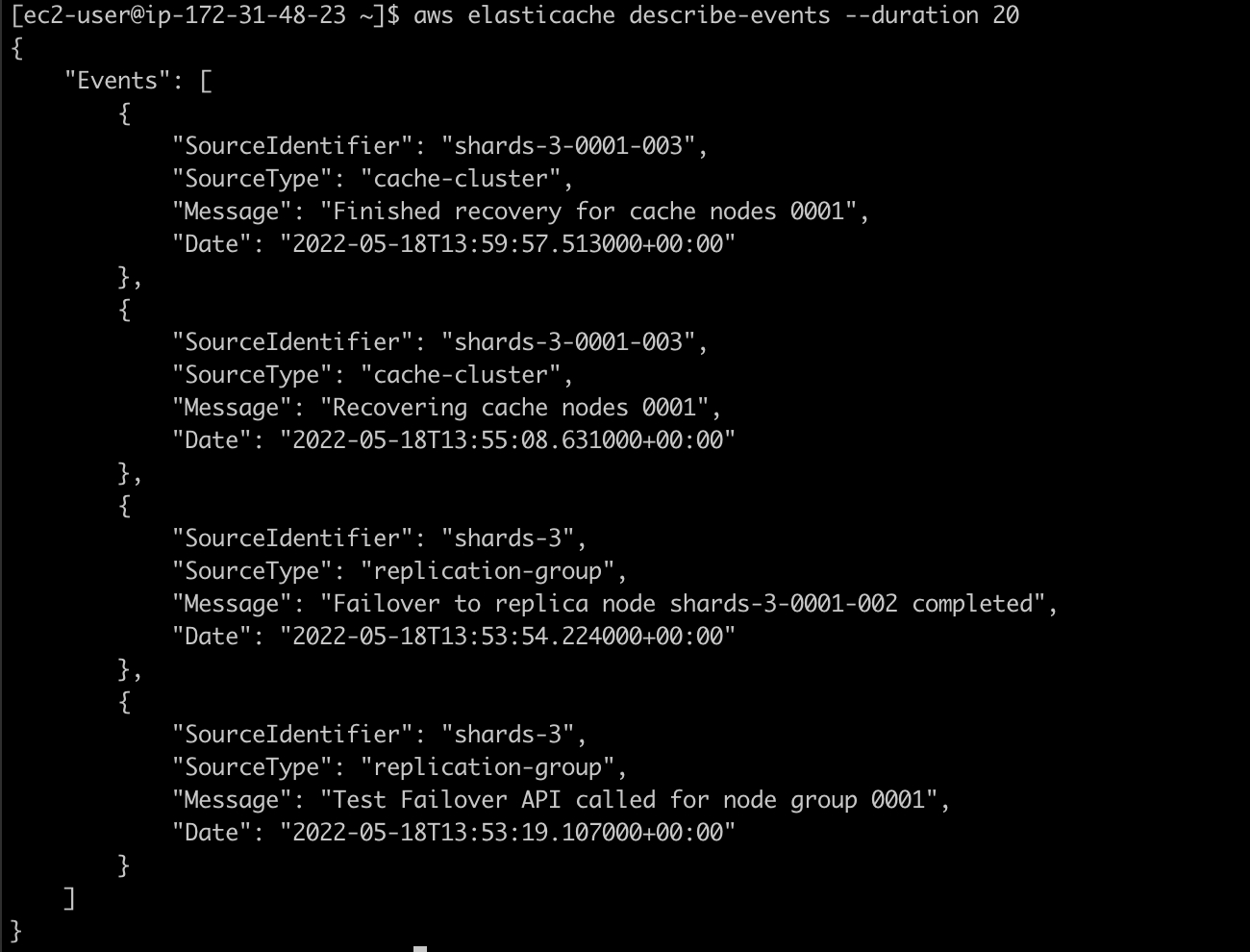
- 13点53分19秒,ElastiCache集群Shard 1的Failover动作被触发,从此时间点开始,Shard 1不可用,而其他Shards可用。
- 13点53分54秒,Failover动作执行完毕,可以看到读副本shards-3-0001-002被提升为了主节点。直到此时间点,Shard 1恢复可用。
- 13点55分08秒,之前的主节点shards-3-0001-003被设置为读副本,开始从主节点复制数据。
- 13点59分57秒,shards-3-0001-002节点数据恢复结束。直到此时间点,该节点恢复可用,整个集群完全恢复正常。
场景3:4 shards with 1 Primary + 2 Read Replica / Shard
测试结论:
在Shard 1中执行Test Failover,主副切换过程会经历30秒左右(多轮测试结果),在此期间Shard 1不可用;其他Shard仍然可用。
测试过程:
场景3的测试过程与场景2类似,此处就不在复述。
四.总结
本文带领大家了解了如何在ElastiCache启用集群模式的情况下使用redis-py,我们还研究了Multi-Key、Pipeline等指令在集群下的工作模式,以及在集群Failover下的表现,您也可以移步redis-py的github,以了解更多的使用细节。
相关博客
- 条条大路通罗马 — 使用 redisson 连接 Amazon ElastiCache for redis 集群:https://aws.amazon.com/cn/blogs/china/connecting-amazon-elasticache-for-redis-cluster-using-redisson/
- 条条大路通罗马 — 使用 go-redis 连接 Amazon ElastiCache for Redis 集群:https://aws.amazon.com/cn/blogs/china/all-roads-lead-to-rome-use-go-redis-to-connect-amazon-elasticache-for-redis-cluster/
- 条条大路通罗马 — 使用 Hiredis-cluster 连接 Amazon ElastiCache for Redis 集群:https://aws.amazon.com/cn/blogs/china/all-roads-to-rome-series-connect-amazon-elasticache-for-redis-cluster-with-hiredis-cluster/
- 条条大路通罗马 — 如何在.NET 程序中使用 StackExchange.Redis 操作 Amazon ElastiCache for Redis:https://aws.amazon.com/cn/blogs/china/all-roads-lead-to-rome-how-to-use-stackexchange-redis-to-operate-amazon-elasticache-for-redis-in-net-program/
- 条条大路通罗马 — 使用 Jedis 访问 Amazon ElastiCache for Redis 集群:https://aws.amazon.com/cn/blogs/china/accessing-an-amazon-elasticache-for-redis-cluster-using-jedis/