亚马逊AWS官方博客
使用可视化工具加载 Amazon Redshift 数仓数据完成机器学习数据准备和模型快速验证
数据仓库是现代化数据战略中生成指标报表、提供实时数据查询和分析的重要工具之一,是众多企业和公司数据分析师的不二之选。Amazon Redshift是亚马逊云科技推出的一个完全托管、可扩展的云数据仓库,成千上万的客户依靠 Amazon Redshift 分析从 TB级到 PB 级的数据并运行复杂的查询工作,数据分析师可通过它提供的快速、简单和安全的大规模分析能力来加快数据挖掘的时间。Amazon Redshift 提供了众多高级分析组件,使得跨数据库、数据湖、数据仓库和第三方数据集来进行数据洞察和探索成为了可能。
随着近几年机器学习技术的发展和快速演进,模型和算法的应用门槛逐步降低,有众多数据分析团队在已有的大数据分析体系的基础之上,尝试使用机器学习模型去解决实际的生产问题,如对于商品需求量、销售量的时间序列预测,对于已有客户群体的高低价值、付费意愿预测,客户留存、流失预测,受信、交易的风险预测等。由于已有的相关历史数据本身也作为日常指标报表、交互式即席查询等大数据应用场景来使用,往往会存放在如Amazon Redshift等数据仓库之中,为了能够快速进行机器学习实验和验证,需要使用有效的工具加载Amazon Redshift中的数据表,完成后续的数据探索和建模。
Amazon SageMaker是亚马逊云科技推出的云上机器学习平台,它提供了从数据标记、数据处理、模型训练、推理、监控等机器学习端到端的功能组件,使得机器学习开发者无需关注底层基础设施的运维工作,更加轻松地完成算法开发和模型工程化应用。这其中,Data Wrangler是基于Amazon SageMaker Studio的一项重要组件,它以低代码的方式提供了一套完整的面向机器学习建模的数据可视化处理操作界面,目前支持加载来自对象存储S3、数据仓库Redshift、即席查询服务Athena以及第三方数据源中的结构化数据,并提供了300多种常见的数据加工控件以及统计分析工具,使得数据分析师可以快速、直观地对数仓中的数据表完成机器学习建模的数据准备和快速验证工作,几乎无需编写预处理代码,十分方便和易用。
接下来,本文会为您展示一个简单的2分类预测的机器学习场景,通过加载存放于数据仓库Amazon Redshift中的银行客户画像和业务行为特征,来完成建模前特征的快速准备和预测是否办理存款业务模型的快速验证。
目前,亚马逊云科技的北京(cn-north-1)、宁夏(cn-northwest-1)和海外众多区域均提供了Amazon Redshift和Amazon SageMaker服务,本文选择宁夏区域(cn-northwest-1)来部署和展示相关方案,您也可以根据数据和环境的需要选择相应区域来开展实践。
1. 构建Amazon Redshift数仓集群并加载示例数据集
如果您需要从0至1搭建一个Redshift集群,您可以参考该教程来创建一个实验集群资源。
集群创建完毕后,您可以在本地终端运行以下脚本,下载、解压示例数据集并上传到S3。
您可以在通过以下命令查看数据集是否已经正确上传到s3的指定路径中:
$ aws s3 ls s3://<your-own-bucket>/<your-own-path>/

接下来,我们通过Amazon Redshift控制台中的 Query Editor来构建数据表,进入集群的详情页,点击右上角的Query cluster,进入在线查询编辑器界面。

在编辑器界面,点击“Connect to database”,输入database名称和用户名,点击“Connect”。

创建Schema,点击“RUN”:
CREATE SCHEMA sch_bank_deposit AUTHORIZATION awsuser;

在左侧选择刚创建的schema,创建数据表,点击“RUN”:
在Editor左侧的列表中,我们创建好了数据表,并将存放于S3上的数据集Load到该表中。

我们可以开启一个新的Query,查询表中的客户画像数据:
select * from sch_bank_deposit.t_bank_deposit limit 10;

至此,我们在Redshift中完成了建模数据集的加载,接下来我们需要使用SageMaker来完成面向机器学习模型训练的数据加工工作。
2. 使用SageMaker Data Wrangler加载Redshift数据集并完成可视化数据加工
首先,我们要启动SageMaker Studio,它是云上第一个端到端的机器学习实验和生产平台,它包含的众多组件方便我们进行算法开发和模型迭代,而无需关注底层资源构建和维护。请参考该教程来启动一个SageMaker Studio开发环境。
构建完成后,点击当前Users列表中指定用户的Studio环境,进入开发界面。
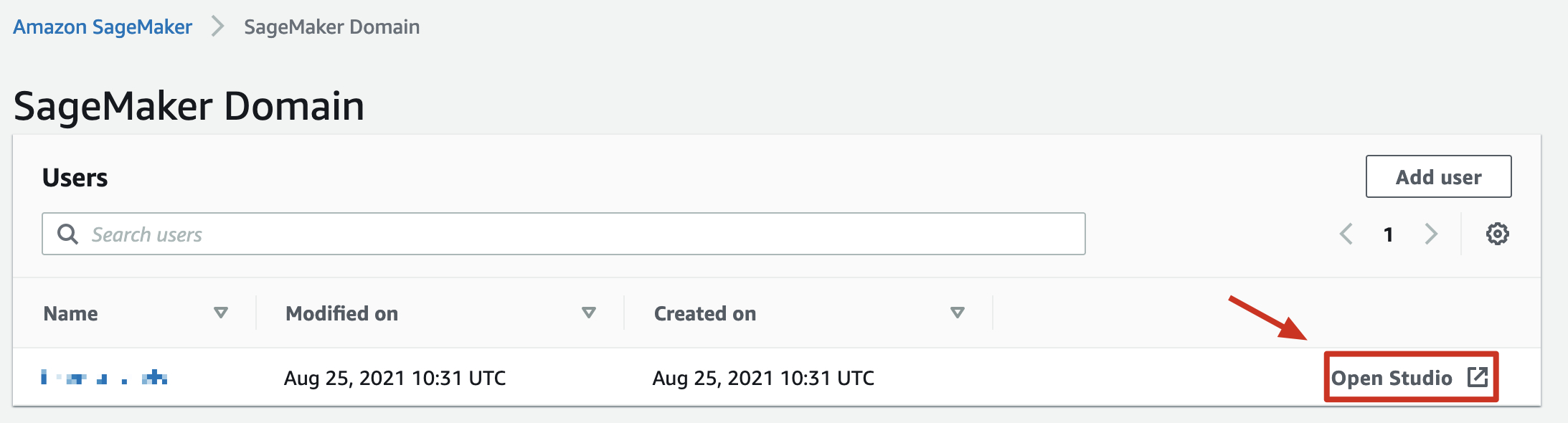
点击左侧插件栏中的“SageMaker Resources”,下拉列表中选择“Data Wrangler”,进入可视化数据开发的界面,选择“New Flow”创建一个新的工作流程,在右侧的操作界面选择“Add data source”,选择“Amazon Redshift”。
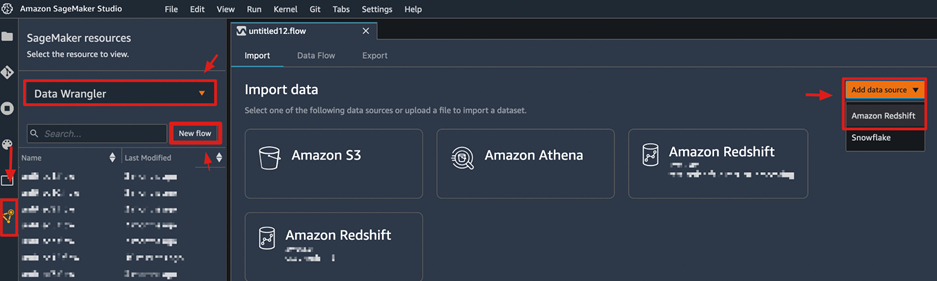
在连接配置界面中填写相关信息,选择“Connect”,这里的IAM role需要具备访问相应s3桶的权限。
在查询界面中,选择数据表所在的Schema,可以在右侧看到包含的表名称,您也可以使用该编辑器来查询数据,完成后可以点击“Import”导入想要加工的数据集。

接下来会跳转到数据流画布,默认会有“Source”和“Data types”两个节点,数据源就是我们制定的Redshift数据表,我们点击右侧加号,“Add transform”,开始可视化数据加工的操作。

点击“Add step”,使用内置的工具依次添加数据处理步骤
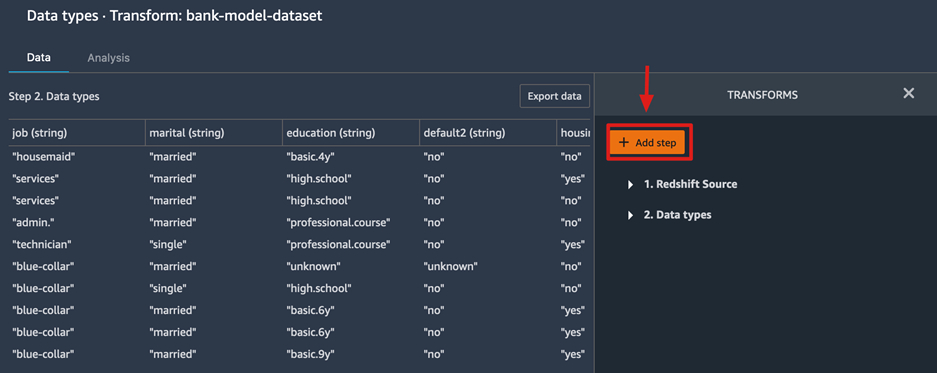
首先,模型的输入需要数值型数据,我们把已知的分类型特征通过编码转换为数值类型,这里我们选择简单的one hot encoding方法来实现,如对于婚姻状态“marital”特征,点击“Encode categorical”,

在控件中选择“one hot encode”,源特征列“Marital”,无效值处理机制“Keep”,输出方法是生成新列,点击“Preview”:

将数据集拉到最后,出现了4个新列,分别使用0/1标记了婚姻状态特征,检查无误后,点击“Add”正式提交该操作方法。

可以看到step列表中添加了一个新的步骤,同时左侧原来的分类型特征“marital”自动被丢弃掉。

同理,对于特征“education”、“default2”、“contact”、“poutcome”进行相同的one hot处理,这里不再赘述。
另外,对于“housing”、“loan”、“y”(为label列,表示是否完成了定期存款),为“yes/no”二分类数据类型,我们可以选择“Ordinal Encode”方式,直接以0/1方式覆盖原有特征。

此外,对于“job”特征,我们希望使用一个新的特征来代替,该特征区分当前客户是否有稳定工作,对于该类附带有相对复杂逻辑的加工方法,Data Wrangler提供了一个自定义方式,您可以提供一个基于pandas、PySpark(SQL)的代码片段,来进行数据加工。我们选择“Custom transform”:

选择Python(Pandas),在文本框中,添加一段基于pandas的逻辑,其中当前的数据集用”df”来表示,您可以直接使用。如下图,我们根据Job的具体值,添加了一个新的特征“not_working”。点击“Add”添加。

对于其他特征:“Job”、“month”、“day_of_week”、“duration”, “emp_var_rate”, “cons_price_idx”, “cons_conf_idx”, “euribor3m”, “nr_employed”,我们直接使用“Manage Columns”中的“Drop column”来丢弃掉。

请注意,对于原始数据集的机器学习建模预处理有多种不同的策略或方法,本文仅通过一些常规方式来展现Data Wrangler的工具能力,您可以根据自己的思考和判断来优化数据集,如奇异值分析、异常值处理、缺失值处理、特征归一化等,进一步提升模型的准确程度。
3. 基于可视化加工后的数据完成模型快速验证
可视化数据加工完成后,我们可以利用SageMaker Data Wrangler提供的“快速建模”功能来实现基于当前状态数据集的模型验证。来辅助我们对不同预处理方法的评估。
点击Analysis选项卡,选择“Quick Model”,并选择当前建模的目标Label列“y”,点击“preview”,
很快,我们就可以看到,当前加工的数据集版本在baseline模型下的分布特征和二分类表现,图中给出二分类F1 Score的分数,以及特征重要性排名,您可以根据快速验证结果调整和优化处理方法,不断迭代进而高效完成数据集的加工方案。

当预处理的方案完成后,我们可以将低代码实现的处理步骤对全量数据集进行加工,您可以在以下4项中选择1项导出方案:1)选择使用SageMaker Processing Job运行该步骤列表,将全量的数据加工结果保存到S3;2)将该步骤以环节的方式导入到SageMaker自带的工作流中;3)导出Python代码;4)将数据导出到SageMaker内置的特征仓库中。所有的代码都是自动生成,无需您掌握或编写其中的细节,十分简易和高效。具体的解释请见该教程。导出后的全量处理数据可以用于后续的模型训练和调优。

4. 总结
越来越多的企业尝试使用机器学习技术来丰富数据分析的手段和方法,亚马逊云科技基于“智能湖仓”架构,通过一系列组件打通不同服务之间的数据连接,使得数据流转更加无缝和便捷,也以此将机器学习技术交付给更多数据开发者的手中,更可以使拥有大量数据资产的企业以极快的速度发挥数据的价值。