亚马逊AWS官方博客
利用Trusted Advisor和架构完善框架审核达到成本优化
在亚马逊云计算的 架构完善框架中, 成本优化是框架的六大支柱之一。 利用成本优化中定义的设计准则和最佳实践,来协助客户构建工作负载。 所谓成本优化,既要能够达到服务的商业目标,同时又能实现有效的成本支出。 亚马逊云计算主控台中的Well-Architected Tool,主要基于设计准则以及最佳实践的选项,协助架构设计人员进行架构完善审核 (Well-Architected Framework Review, WAFR或称W-A Review)在持续改善的过程中,有系统的记载潜在的风险,并持续进行架构改善。 在WAFR的过程中,利用观测工具或是自动化收集,并利用环境中的数据来进行决策 ,以减少主观性造成的偏差,更快地确定架构改善的方向。 要有效的参照这些数据资料,您可以利用亚马逊云计算中的Trusted Advisor。 本文将探讨如何利用Trusted Advisor运行数据驱动型方法,实现成本优化。
在架构完善审核中的成本优化
在WAFR的过程中,每一条设计准则都设评核问题来涵盖相对应的范畴,用于探索当下的架构状态。 经由这些问答讨论,以来确保客户在每个领域都能采用云计算架构的最佳实践。 一旦在审核过程中找到任何架构设计中的潜在风险,都可记载在审核记录中,在亚马逊云计算的海外区域用户可以直接使用账户中的Well-Architected Tool。 将这些评核结果与最佳实践进行比较,便可以针对当下的架构进行改善,以消除潜在的风险。
当然,对于改善成本结构来说也是一样。 在此我们举来一个评核工具内的问题作为例子∶
COST 6, “选择资源类型大小和数量时,如何满足成本目标? “。
这个问题背后隐含的意义,是为了确保计算资源使用最佳的类型,正确的规模大小以及适当的 数量。 以此,可以支持商业目标所需的性能级别,同时又能让成本花费在精简不被浪费的 水平 。
从更高的维度来看,成本设计准则「采用消费模型」(Adopt a Consumption Model) 就是这个问题的理论基础。 在花费模型当中,明确的定义了用户应该采用「具有经济效益资源」– 意即采用高效能 与低成本更好的云计算资源。 当我们能够遵从设计准则、找到正确定义,就能够真正落实最佳实践中描述的正确地调整资源规模( Right Sizing) 。

图∶由框架支柱、设计准则、定义、问题导引到最佳实践的具体内容。
在进行Well-Architected Framework Review时,涵盖到架构设计中的某些区块,需要在当下收集准确的资料及数据, 用于未来改善的基准线(Baseline)。例如在Lambda 函数计算资源下,若要达到正确地调整资源规模, 意味着可以选择函数内存的成本花费作为优化的选项∶
- 因此需要监视Lambda函数在一段时间内的利用率
- 并将其与分配的总内存进行比较。
- 预配置过多内存空间,意味着您正在为未使用的资源付费,造成支出浪费。
- 配置太少则会对函数性能产生负面影响。
这意味着,在没有这些利用数据点来提供参照的情况下,WAFR讨论一但开始偏差,偏向空泛的讨论而没有明确的佐証,会 无法直接找到明确的改善方案。 例如,需要等到配置相对应的监控机制才能进行下一步,或是误以为目前的配置是正确有效的。
使用Trusted Advisor 提供的见解进行数据驱动的审查
在亚马逊云计算的环境当中,如果我们想要对Lambda函数的内存使用率进行观测,Amazon CloudWatch 通常都是第一个我们想要参照的观测服务。 用人工的方式来解读I这些观测数据背后的意义通常需要很长的时间,同时也需要有足够的经验或是对于系统有足够的理解。 在这样的情况下,有效的利用Trusted Advisor 提供的信息去解读数据背后的意义,能够有效转化成架构改善的解法方案。 这些数据信息将为您架构决策提供确切的指引,协助您更快地解决问题。 以这个Lambda 函数的例子来说,依照 Trusted Advisor 当中 Compute Optimizer 提供的检验中, 我们可以看到有以下两个项目与函数的内存大小有关∶
- 预配置过多(Over-provisioned) 的 Lambda 和函数内存大小
- 预配置不足(Under-provisioned)的 Lambda 和函数内存大小
很明显的,对于Lambda函数的内存空间,配置过多或是过少都有可能造成不必要的费用支出。 内存配置过小,可能会造成函数在执行的时间变长,有时甚至会造成函数执行错误或失败; 但相对来说却也比较容易被察觉。 预配置过多的空间则变得不容易被察觉到,除非我们针对每一个函数的空间利用率进行细部的观测与比较。 下图就是Compute Optimizer自动监控 Lambda 函数的利用率,根据观测数据所提出的建议内容,同时也包括了不同面向的参照∶
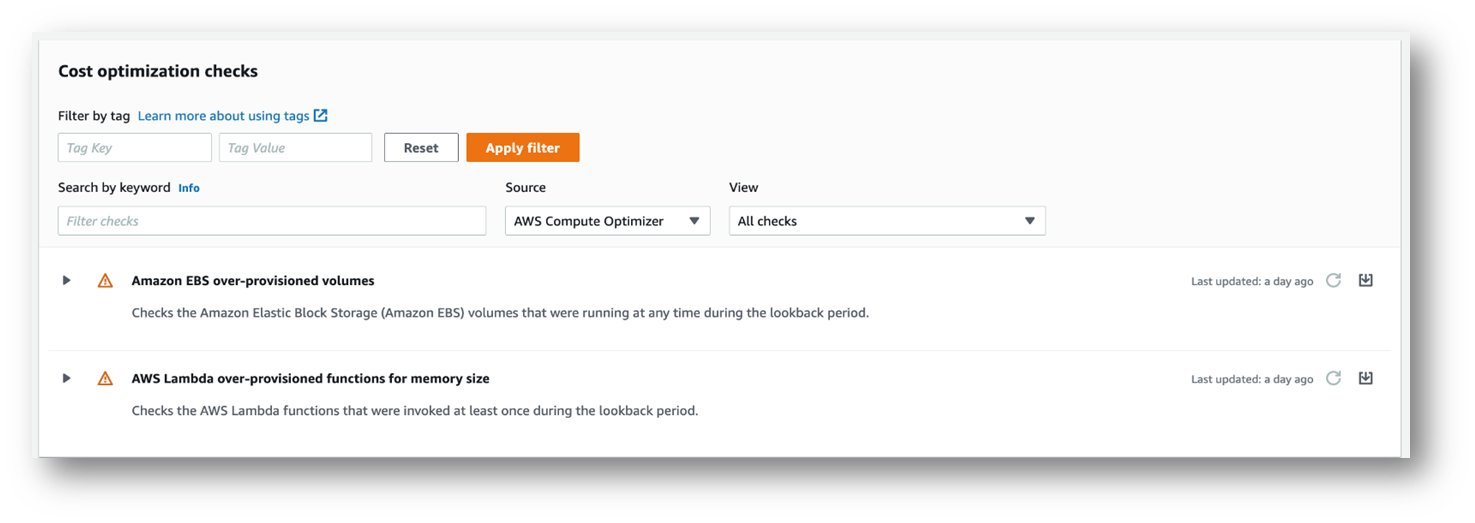
图∶经由Trusted Advisor列出的自动检验项目,指出Lambda函数的内存大小需要调整。
- 这个函数的内存空间目前配置为1 GB
- 过去的纪录显示最大的空间使用为 819MB
- 建议调整的内存空间大小为 900MB, 基于历史最大值外加了 10% 的空间
- 调整后的函数预估会增加200ms的运行时间
- 建议调整后的空间大小以及运行时间估计能减少1%~15.7% 的花费支出
基于以上这些讯息,针对 Lambda 函数内存的讨论就变得相对明确。 在架构调整上面我们不需要再回到观测建置或数据收集的阶段。此时只需要考虑到缩小后的内存能正常运行,再考虑到达加的执行时间是否在可以接受的范围,讨论的主轴就会相对有效率。 当然,建议讯息里面也明确指出能节省的数字,这也会是一个推动架构改善的重要推力。
采用数据驱动的WAFR,您将能够将架构改善更推近到您的预期结果。 使用上述 Lambda 函数内存大小的示例,您可以有效的得到内存大小的配置建议,明确的指出有效的修正解决方案。利用账户内建的观测服务所得的数据,或是第三方所得到的观测信息,都能有效的加速架构改善。例如使用 Lambda 和 Event Bridge 等服务对接并生成报表以供解读。借此,我们可以在进行 WAFR 之前就先直接将所需的参数数据直接导入,在进行讨论的时候可以直接参照可见的数据内容。
善用评核中的里程碑、管理迭代进度
借由WAFR进行成本优化,主要预期每一次的评核及改善周期中逐渐修正成本结构,尽可能消除任何不必要的支出。 在工作负载逐步进行改善的过程中,您希望确保所做的改进被修复的潜在风险可以被清楚的理解,以可视化的报告或是文字记载作为参照。 您可以在项目周期中设定一定时间作为检查点 (Check Point),海外区域的用戶利用Well-Architected Tool中內建的里程碑(Milestones)机制来纪录每一次评核时的定点快照(Snapshot)。 通过里程碑,您将能够记录WAFR在每一个周期之间的信息,当下被侦测到的 高度风险和中等风险问题(HRI / MRI)的总数。 随着改善周期的推进,您将能够通过查看被修复(Remediation)的HRI / MRI数量来衡量您的进度。 当您看到在成本优化支柱的HRI / MRI数字减少时,您的架构设计即逐渐往成本优化前进。

图∶在WAFR中, 不同的里程碑之间的架构改善过程
结论:
在过去的文章我们曾分享如何利用架构完善框架协助成本优化。 如今您可以由此扩展,以数据驱动审核的方式、先延展到Trusted Advisor所支持的 自动成本优化检查项目。 更可以延伸涵盖工作负载中的不同领域,例如Trusted Advisor同时也涵盖了其他性能、安全性、容错能力和资源服务配额等项目。 在最新的亚马逊云计算的 架构完善框架则是涵盖六大支柱,即成本优化、卓越运营、安全性、可靠性、性能效率和可持续性。 两者之间的重叠性非常高,因此,利用Trusted Advisor提供的各项信息用作WAFR的参照,能够协助在您在云计算架构设计上更快速有效的采用最佳实践。
架构完善框架协助云端架构师建置安全、高效能、有弹性又有效率的各种应用程序和工作负载基础设施。 以六大架构支柱为基础,即卓越运营、安全性、可靠性、性能达成效率、成本优化和可持续发展,架构完善框架为客户与合作伙伴提供一致的方法来评估架构,以及实现可扩展的设计。 如果您需要我们的帮助,可以联系客户团队。