亚马逊AWS官方博客
Western Digital HDD 云级模拟 – 250 万个 HPC 任务,4 万个 EC2 Spot 实例
本月早些时候,我的同事 Bala Thekkedath 发表了一篇关于超大规模 HPC 的文章,探讨了 AWS 客户 Western Digital 如何基于 AWS 构建云级 HPC 集群,并利用它来模拟其新一代硬盘驱动器 (HDD) 即将采用的磁头中的关键组成部分。
那篇文章中描述的模拟包含了超过 250 万个任务,而且在一个包含百万个 vCPU 的 Amazon EC2 集群上仅用 8 个小时就完成了运行。正如 Bala 在他的文章中分享的一样,Western Digital 的大部分模拟工作都围绕着评估构成 HDD 的技术和解决方案的不同组合的需求。工程师专注于将更多数据塞进同一空间,从而提高存储容量并在此过程中提高传输速度。通过模拟材料、能级和转速的数百万种组合,他们可实现最高的密度和最快的读写速度。更快获得结果的能力使他们能够制定出更好的决策,并让他们比以往更快地将新产品推向市场。
下图以直观的方式展示了 Western Digital 的能量辅助式记录过程。最上面的条纹代表磁力;中间一条代表增加的能量(热量);最下面一条代表借助磁力和热量的组合写入介质的实际数据:

我最近与我的同事以及 Western Digital 和 Univa 的团队进行了交流,正是这些团队的协作努力才让这次创纪录的运行成为现实。我的目标是详细了解他们如何为这次运行做好准备、他们总结出的经验教训,并与大家分享这些信息,以供您在准备好运行自己的大规模作业时借鉴。
提升
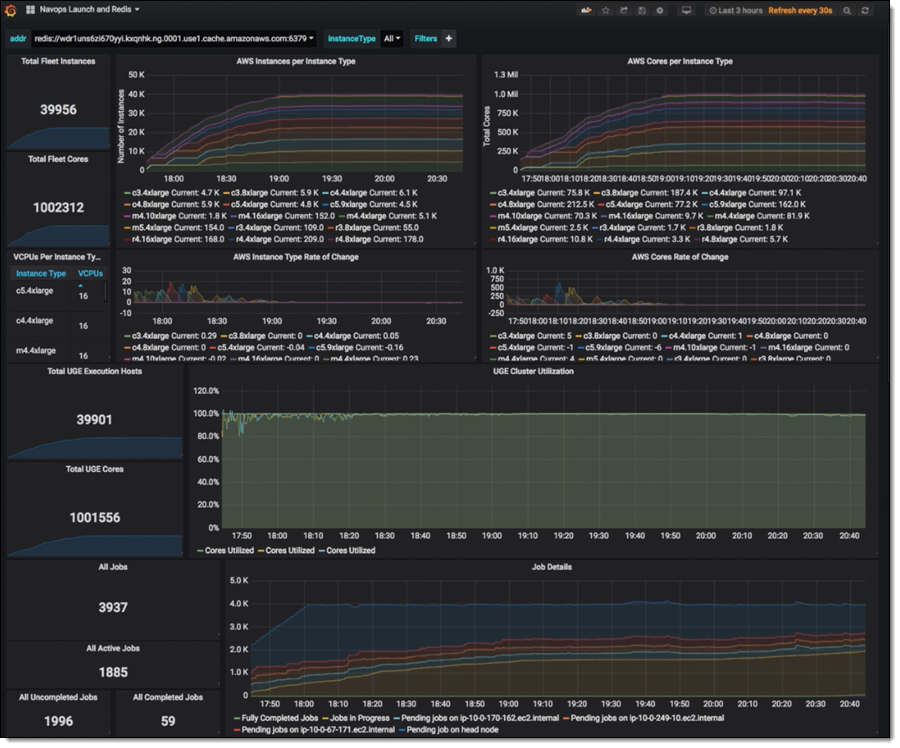
 大约两年前,Western Digital 团队运行着多个包含多达 8 万个 vCPU 的大型集群,这些集群由 EC2 Spot 实例支持,以便尽可能节约成本。在使用 8000、1.6 万和 3.2 万个 vCPU 重复成功运行后,他们将 vCPU 数量增加到了 8 万个。取得这些早期成功之后,他们定下了远大目标,决定突破极限,努力实现 100 万个 vCPU 的成功运行。他们知道,这必然会给现有的工具带来沉重的压力和负担,于是决定采用一种更好的发现/修复/进一步扩展的方法。
大约两年前,Western Digital 团队运行着多个包含多达 8 万个 vCPU 的大型集群,这些集群由 EC2 Spot 实例支持,以便尽可能节约成本。在使用 8000、1.6 万和 3.2 万个 vCPU 重复成功运行后,他们将 vCPU 数量增加到了 8 万个。取得这些早期成功之后,他们定下了远大目标,决定突破极限,努力实现 100 万个 vCPU 的成功运行。他们知道,这必然会给现有的工具带来沉重的压力和负担,于是决定采用一种更好的发现/修复/进一步扩展的方法。
Univa 的 Grid Engine 是一种批处理调度程序。它负责跟踪可用的计算资源(EC2 实例),并尽可能快速高效地为实例分派工作。目标是在最短的时间内以最低的成本完成作业。Univa 的 Navops Launch 支持基于容器的计算,并允许为 Grid Engine 和 AWS Batch 使用相同的容器,因此在此次运行中发挥了重要作用。
在 5 万台主机创建到 Grid Engine 调度程序的并发连接时,出现了一个值得关注的扩展难题。运行之后,该调度程序每秒最多可以调度 3000 个任务,但在实例意外终止并表明需要尽快重新安排 64 个或更多任务这种相对罕见的情况下,需要额外突发。该团队还发现,通过 IP 地址引用工作线程实例可让他们回避各弹性网络接口上有关 DNS 查找数量的某些内部 (AWS) 速率限制。
整个模拟过程均封装在 Docker 容器中,以方便使用。当新启动的实例联机时,它们会在 ElastiCache for Redis 集群中注册其规格(实例类型、IP 地址、vCPU 计数和内存等)。Grid Engine 使用此数据来查找和管理实例;这比持续调用 DescribeInstances 更高效,也更具可扩展性。
模拟任务从 Amazon Simple Storage Service (S3) 读取数据并向其中写入数据,利用 S3 存储海量数据以及处理任何可能出现的请求速率的能力。
模拟任务内幕
每种可行的磁头设计均由一组参数描述;整个模拟运行包括对此参数空间的探索。运行结果有助于设计人员找到可构建、可靠且可制造的设计。此次特定运行侧重于对写入操作进行建模。
每个模拟任务运行时间为 2 到 3 个小时,具体取决于 EC2 实例类型。为了避免在 Spot 实例即将终止时丢失工作,这些任务每 15 分钟会在 S3 中为自身设置一次检查点,并提供一些额外的逻辑,说明作业在终止信号之后、实际关闭之前完成的重要情况。
实际运行
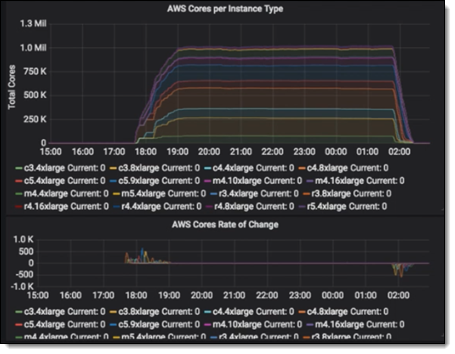
经过仅仅 6 周的规划和准备(包括多次大规模 AWS Batch 运行以生成输入文件),Western Digital/Univa/AWS 联合团队就为全面运行做好了准备。他们使用 AWS CloudFormation 模板启动了 Grid Engine 和集群。得益于我先前描述的基于 Redis 的跟踪,他们能够在实例可用时立即开始将任务分派给实例。该集群在 1 小时 32 分钟内扩展到 100 万个 vCPU,并全速运行了 6 个小时:
当没有更多未分派的任务可用时,Grid Engine 开始关闭实例,在大约一小时内关闭所有实例。在运行期间,Grid Engine 能够保证实例在 99% 的时间内均能满负荷工作。该运行组合使用了 C3、C4、M4、R3、R4 和 M5 实例。下图显示了此次运行过程的详细情况:
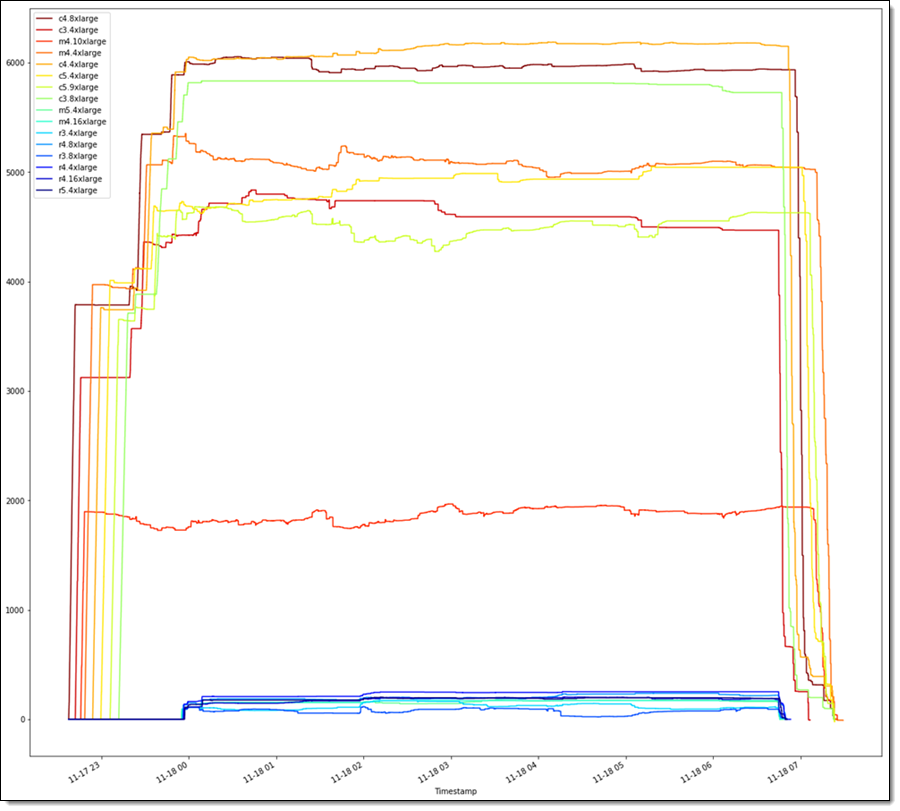
该作业涉及到美国东部(弗吉尼亚北部)区域中的所有 6 个可用区。Spot 报价以按需价格为依据。在运行过程中,机组中大约 1.5% 的实例被终止并自动更换;绝大多数实例都全程保持正常运行。
就是如此轻松
这项作业运行了 8 小时,费用为 137307 USD(每小时 17164 USD)。根据与我交流过的人员预估,这样的费用是在内部集群上运行时费用的一半 – 前提是他们得有同等规模的内部集群!
在评估这次运行的成功情况时,Steve Phillpott(Western Digital 的 CIO)告诉我们:
 “存储技术非常复杂,我们不断突破物理和工程的极限,以提供下一代产能和技术创新。与 AWS 的这次成功合作展示了基于云的 HPC 的超大规模、强大能力和高度敏捷性,可帮助我们运行复杂的模拟,为未来的存储架构分析和材料科学探索提供支持。通过使用 AWS 轻松将模拟时间从 20 天缩短到 8 小时,Western Digital 研发团队能以不久之前还不可想象的速度探索新的设计和创新。”
“存储技术非常复杂,我们不断突破物理和工程的极限,以提供下一代产能和技术创新。与 AWS 的这次成功合作展示了基于云的 HPC 的超大规模、强大能力和高度敏捷性,可帮助我们运行复杂的模拟,为未来的存储架构分析和材料科学探索提供支持。通过使用 AWS 轻松将模拟时间从 20 天缩短到 8 小时,Western Digital 研发团队能以不久之前还不可想象的速度探索新的设计和创新。”
参与这次合作的 Western Digital 团队目前正在诚招研发工程技术专家,还有其他许多职位虚位以待!
我们也可为您安排运行
如果您想实现包含 10 万到 100 万个内核(或更多内核)的大规模运行,我们的 HPC 团队将竭诚相助,我们的合作伙伴 Univa 同样随时待命。若要开始体验,欢迎联系 HPC 销售部门!
– Jeff;