Blog de Amazon Web Services (AWS)
Acelere la migración de bases de datos mediante el uso de AWS DMS con opciones de carga paralela y filtros
AWS DMS es un servicio de migración de datos que cuenta con características sólidas para soportar migraciones de bases de datos homogéneas y heterogéneas. AWS DMS ofrece opciones de carga en paralelo y filtros para cargar datos de manera óptima. También ayuda a reducir el tiempo de carga de datos.
En esta publicación, demostramos cómo puede acelerar las migraciones de bases de datos mediante el uso de las opciones de carga paralela y filtros de AWS DMS para hacer que la carga de datos sea más eficiente para tablas relacionales, vistas y colecciones.
Carga completa en paralelo
La carga en paralelo puede mejorar la migración de bases de datos dividiendo una sola tarea de carga completa en múltiples subprocesos en paralelo. Para utilizar la carga paralela, puede segmentar su tabla, vista o colección definiendo una regla de asignación de tablas de tipo table-settings con parallel-load y establecer el parámetro de tipo parallel-load con una de las siguientes configuraciones:
- Cargar todas las particiones de una tabla o vista existentes usando partitions-auto, o cargar solo las particiones seleccionadas usando el tipo partitions-list con una matriz de particiones especificada
- Cargar todas las subparticiones existentes de una tabla o vista usando el tipo subpartitions-auto (solo para puntos de conexión de Oracle)
- Cargar segmentos de una tabla, vista o colección que defina mediante límites de valor de columna, especificando los tipos de rangos (range) con columnas especificadas
Sin embargo, es importante saber dónde usar partitions-auto en lugar de partitions-list, donde rangos es una buena opción, y posibles combinaciones de estos ajustes.
Auto Particiones (partitions-auto)
Cuando usamos la opción de carga paralela con el tipo partitions-auto, cada partición de tabla, vista o colección (o segmento) o subpartición se asigna automáticamente a su propio hilo de trabajo(thread). Veamos cómo podemos optimizar la carga de datos mediante el uso de partitions-auto.
Por ejemplo, tenemos la tabla SALES_HIST en Oracle con 258 millones de filas y tenemos cinco particiones definidas en la columna sales_year:
Utilizamos la siguiente configuración sin carga paralela en nuestra configuración de tareas y medimos el rendimiento del tiempo de carga de datos:
La siguiente captura de pantalla muestra que nuestra tarea tomó alrededor de 9 minutos.

Luego modificamos table-settings en la tarea con carga paralela con el tipo partition-auto. El siguiente código es nuestra configuración de la tarea actualizada en formato JSON:
La nueva tarea tardó 6 minutos en migrar el mismo número de filas, como podemos ver en la siguiente captura de pantalla.

Echemos un vistazo más de cerca a Amazon CloudWatch Logs para ver cómo AWS DMS trató esta tarea. Al verificar los registros, podemos ver que AWS DMS creó cinco hilos de trabajo (threads), ya que la tabla SALES_HIST tiene cinco particiones y cargó los datos en paralelo.

AWS recomienda que no cargue una gran cantidad de colecciones grandes usando una sola tarea con carga paralela. AWS DMS limita la contención de recursos, así como el número de segmentos cargados en paralelo usando el valor del parámetro de configuración de tareas MaxFullLoadSubTasks, que tiene un valor máximo de 49.
Para obtener más información sobre los registros en CloudWatch, consulte Configuración de registro de tareas.
Lista de Particiones (partitions-list)
Para superar este problema con carga paralela, AWS DMS proporciona otra opción para cargar particiones en paralelo: partitions-list.
Con partitions-list, solo las particiones especificadas de la tabla o vista se cargan en paralelo, a diferencia de partition-auto, donde todas las particiones se cargan en paralelo. Nuevamente, cada partición que especifique se asigna a su propio hilo de trabajo(thread).
Veamos cómo podemos usar partitions-list y optimizar la carga de datos aplicando partitions-list para nuestra tabla SALES_HIST.
La siguiente consulta muestra cómo se asignan las filas a cada partición en nuestra tabla SALES_HIST:

En esta prueba, creamos tres tareas diferentes y distribuimos todas las particiones de la tabla SALES_HIST a cada tarea. Entonces, la tarea saleshist-partition-list-2018-2019 cargó dos particiones (2018 y 2019), la tarea saleshist-partition-list-2020-2021 lcargó dos particiones (2020 y 2021) y la tarea saleshist-partition-list-2022 cargó la partición 2022.
Utilizamos la siguiente configuración de tarea para cada tarea:
En la siguiente captura de pantalla se muestra el resultado de cada tarea.

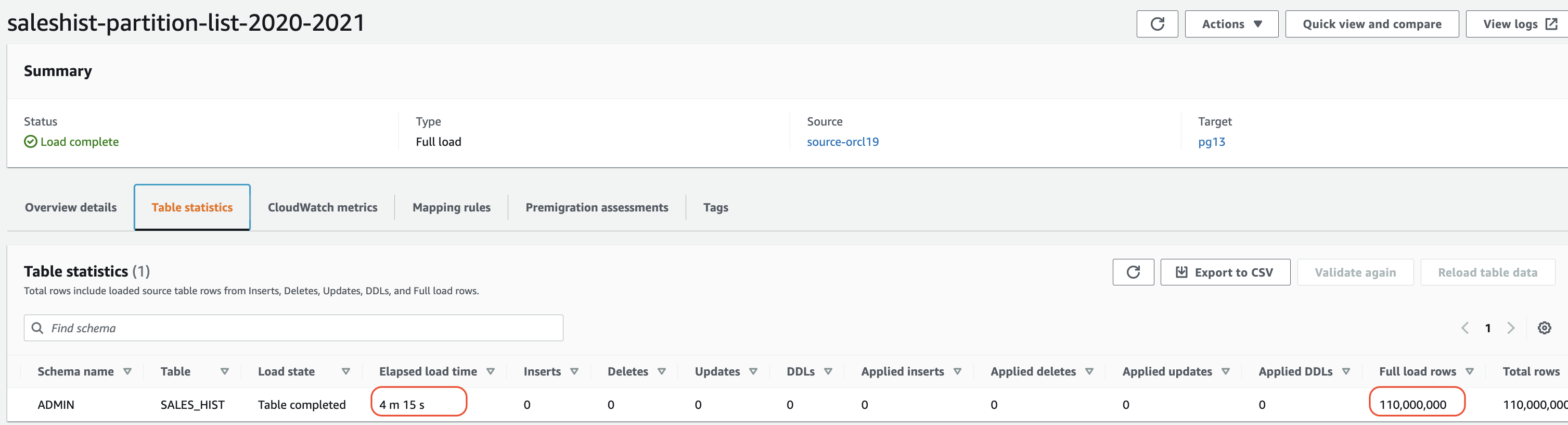

El tiempo máximo es de aproximadamente 4 minutos para la segunda tarea, lo que significa que cargamos las cinco particiones en solo 4 minutos creando tres tareas usando partition-list.
Podría considerar partition-list para los siguientes casos de uso:
- Tiene una gran cantidad de particiones para una sola tabla
- No quieres mover todas las particiones
Rangos (ranges)
Supongamos que tiene tablas enormes sin particionar. ¿Cómo se pueden cargar los datos de manera eficiente mediante el uso de carga paralela?
El tipo rangos(range) define los rangos de datos para todos los segmentos de la tabla o vista, especificando una matriz de límites así como el valor de los límites. Cada segmento de tabla, vista o colección que identifique se asigna a su propio hilo de trabajo (thread). Estos segmentos se especifican por nombres de columna (columns) y valores de columna (boundaries).
Cargamos nuestra tabla SALES_HISTusando rangos con carga paralela. Para ello, primero necesitamos saber qué columna es una buena opción para crear límites. Siempre es una buena idea usar columnas únicas e indexadas. En este caso, tenemos la columna product_id, que es única e indexada en la tabla SALES_HIST.
Primero vamos a encontrar los valores min y max para esta columna:

Creamos 10 límites usando PRODUCT_ID especificando rangos en nuestra tarea:
La siguiente captura de pantalla muestra que AWS DMS cargó la tabla en 5 minutos y redujo nuestro tiempo de carga en casi un 50% en comparación con la carga sin paralelismo.

Revisemos más de cerca cómo AWS DMS utiliza los rangos para cargar los datos. En este caso, AWS DMS creó 10 segmentos, uno para cada límite, y cargó las filas en paralelo usando la siguiente cláusula WHERE:
- segmento1 carga las filas con
PRODUCT_ID <=100000 - segmento2 carga las filas con
PRODUCT_ID <=200000 and rows other than segment1 - segmento3 carga las filas con
PRODUCT_ID <=300000 and rows other than segment1 and segment2, y así sucesivamente
Los registros de CloudWatch muestran que tenemos 10 hilos de trabajo (un hilo asignado a cada límite).

La opción de rangos de AWS DMS le permite cargar datos en paralelo para tablas enormes incluso sin particionar.
Debe considerar lo siguiente al usar rangos:
- Si es posible, utilice una clave principal o una columna de índice único para evitar duplicaciones
- Evite la distribución desigual de los registros; si es posible, use columnas de rango que distribuyan registros uniformemente entre rangos
- Puede especificar hasta 10 columnas
- No puede usar columnas para definir límites de segmento con los siguientes tipos de datos en AWS DMS: DOUBLE, FLOAT, BLOB, CLOB y NCLOB
- Especificar columnas indexadas puede mejorar el rendimiento
- Puede crear múltiples tareas usando rangos para un mejor rendimiento
Filtros de fila
A veces, incluso después de usar todas las opciones de carga paralela, no obtenemos un rendimiento óptimo de carga de datos. ¿Qué debemos hacer en ese caso?
AWS DMS proporciona la opción de filtros para limitar las filas y dividir las tablas grandes en múltiples segmentos mediante la creación de una cláusula WHERE. Estas tareas funcionan de forma independiente y pueden ejecutarse simultáneamente. Por ejemplo, nuestra tabla SALES_HIST tiene más de 150 millones de filas, y queremos dividir esta tabla en múltiples tareas para un mejor rendimiento. Primero, necesitamos encontrar un filtro eficiente que podamos usar para segmentar la tabla. Siempre es buena idea segmentar una tabla con el mismo número de filas.
Seleccionemos la columna SALES_YEAR para crear el filtro de las filas.
Segmentemos la tabla en tres tareas usando un operador de filtro en cada partición usando la columna SALES_YEAR,y usamos los siguientes ajustes de tarea para cada tarea:
Considere lo siguiente al usar filtros:
- La columna de filtro siempre debe tener un índice.
- Trate de segmentar la tabla en un número igual de filas tanto como sea posible.
- Aplicar filtros solo a columnas inmutables, que no se actualizan después de la creación.
- Realice un monitoreo de su instancia de replicación mediante los registros de CloudWatch y no sobrecargue la instancia de replicación y el servidor de origen. La instancia de replicación tiene una cuota máxima de 100 tareas.
Conclusión
En esta publicación, compartimos algunas de las mejores prácticas para mejorar el rendimiento de una carga completa de AWS DMS y reducir los tiempos de carga de datos usando opciones de carga en paralelo y filtros. Si tiene algúna retroalimentación o duda, déjela en los comentarios.
Este artículo fue traducido del Blog de AWS en Inglés.
Acerca del Autor
 Ashar Abbas es un arquitecto especializado en bases de datos en Amazon Web Services. El acelera al cliente en la migración de la base de datos a AWS. Se especializa en bases de datos y cuenta con más de 20 años de experiencia.
Ashar Abbas es un arquitecto especializado en bases de datos en Amazon Web Services. El acelera al cliente en la migración de la base de datos a AWS. Se especializa en bases de datos y cuenta con más de 20 años de experiencia.
Traductor
 Sergio Nuñez es especialista en bases de datos con el equipo de aceleración de la nube de Amazon Web Services. Sergio se enfoca en liderar los esfuerzos de migración de bases de datos a AWS, así como proporcionar orientación técnica que incluye optimización de costos, monitoreo y experiencia en modernización a los clientes de Amazon.
Sergio Nuñez es especialista en bases de datos con el equipo de aceleración de la nube de Amazon Web Services. Sergio se enfoca en liderar los esfuerzos de migración de bases de datos a AWS, así como proporcionar orientación técnica que incluye optimización de costos, monitoreo y experiencia en modernización a los clientes de Amazon.