There are two ways to get started with a GraphQL API on AWS:
- Using AWS AppSync, a fully managed serverless GraphQL service; or
- Setting up a self-hosted GraphQL server, using open-source projects like Apollo Server, Express GraphQL, GraphQL Java, Hasura, or Hot Chocolate .NET.
What is serverless GraphQL
AWS AppSync is a serverless GraphQL API service that simplifies application development by providing a single endpoint to securely query or update data from multiple data sources, like Amazon DynamoDB and Amazon Aurora RDS. AWS AppSync also supports subscriptions, making it easy to implement engaging real-time application experiences by automatically publishing data updates to subscribed API clients via serverless WebSockets connections. AWS AppSync GraphQL APIs are fully serverless, scale to meet demand, and have integrated data caching, fine-grained access control, flexible security options, logging, observability, and schema and resolver creation and editing through the AWS AppSync console. All of this is available with per-request billing, keeping management minimal to maintain focus on business use cases and development.
How to set up serverless GraphQL APIs
There are several ways to set up AWS AppSync, depending on how creation needs to work with the API and data tier. Every path to set up an AWS AppSync API is just a few steps.
Guided schema creation wizard
The guided schema creation wizard, available in the AWS AppSync console, generates a fully functional GraphQL API in as little as two steps:
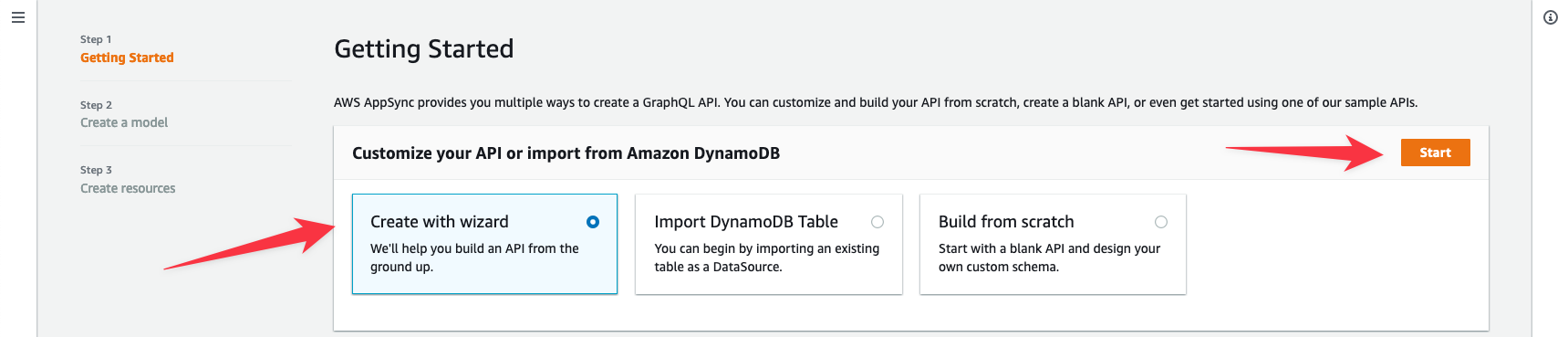
- Select Create API.
- Select the wizard and click Start.
- Add field options and set configurations, then select Create.
- Confirm the API name and select Create.
Refer to the Guided Schema Wizard documentation for more details on the various options and flows of the wizard.
Import from an existing DynamoDB table
AWS AppSync can also take an existing database table and introspect its design to build a GraphQL API endpoint from that table design. It only takes a few steps to set up a fully functional serverless GraphQL API:
- If the table exists, in the AWS AppSync console, navigate to Data Sources and choose New.
- Enter a name for the data source and select Amazon DynamoDB.
- Choose the table and then Automatically generate GraphQL.
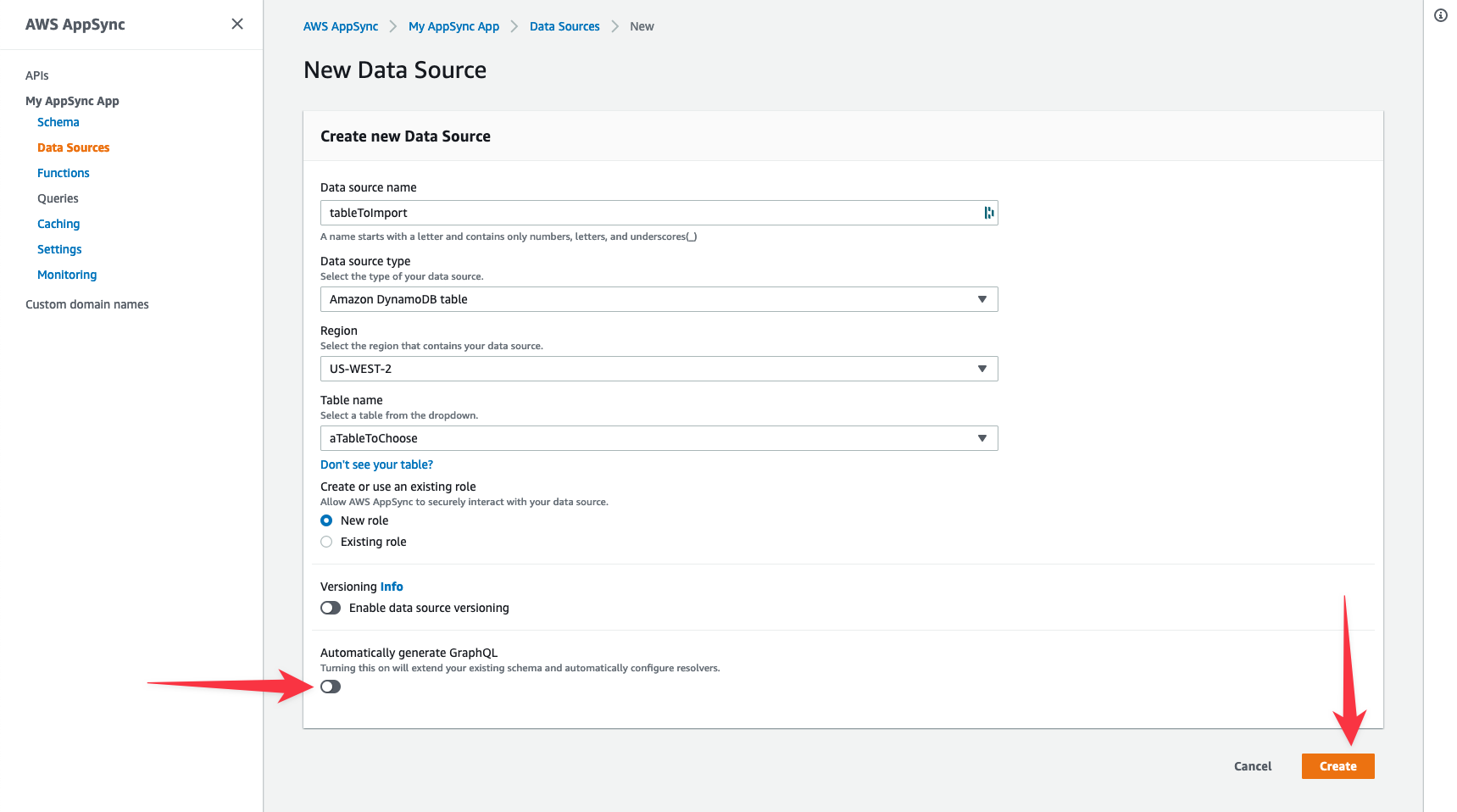
With that done, there is now a fully deployed, available, and instrumented serverless GraphQL API ready for use.
Schema first
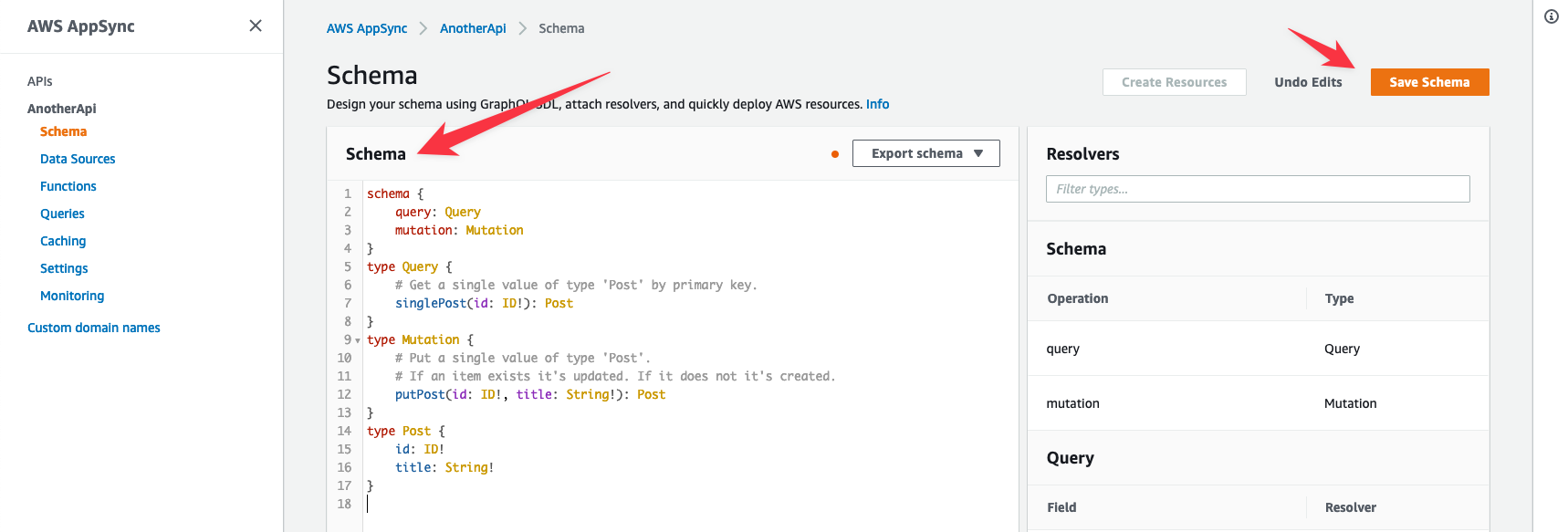
It is just as straightforward to create schema types, queries, and mutations from scratch. Type or paste the schema into the AWS AppSync console. For example, the following is a good starting schema.
schema {
query: Query
mutation: Mutation
}
type Query {
singlePost(id: ID!): Post
}
type Mutation {
putPost(id: ID!, title: String!): Post
}
type Post {
id: ID!
title: String!
}- Select Build from Scratch in the create API wizard, then select Start from the AWS AppSync console.
- Next, Edit schema.
- Finally, enter the schema and select Save Schema.
Code first
A code-first approach offers a developer workflow with:
- Modularity: organizing schema type definitions into different files
- Reusability: simplifying boilerplate or repetitive code
- Consistency: resolvers and schema definition are always synced
The code-first approach allows for dynamic schema generation. Developers can generate schema programmatically based on variables and templates to reduce code duplication. Developers who prefer to use a code-first approach can use the AWS Cloud Development Kit (CDK) to describe and define their GraphQL APIs.
AWS Amplify CLI
Another way to create an AWS AppSync API is by using the Amplify CLI. This involves a two-step process.
- Issue the amplify add api command, which walks through a selection of various options for the API.
- Next, issue the amplify push command. After a few moments, the API is deployed and available.
For more details on this option, refer to the Amplify CLI documentation. The Amplify Docs Overview is excellent as well and includes sections on data modeling, authorization rules, business logic, and others.
Other infrastructure as code options
Most infrastructure as code (IaC) solutions provide support for AWS AppSync. Options include AWS CLI and AWS Cloud Development Kit (AWS CDK), as well as third-party providers such as HashiCorp Terraform, Pulumi, Serverless Framework, and Serverless Stack.
As an example, the AWS CLI also has deployment options for AWS AppSync with the create-graphql-api command with options to set up the various integrations and other capabilities of AWS AppSync. The following is an example of this command:
aws appsync create-graphql-api --name samplingApi --authentication-type API_KEY
For more details on this method, refer to the AWS CLI command reference, and specifically, the create-graphql-api subcommand.
For more information on AWS CDK, Terraform, or Pulumi, here are some starting points.
- AWS CDK – The module for AWS CDK focused on AWS AppSync
- Terraform – The AWS AppSync Terraform Module
- Pulumi – The AWS AppSync entry in the Pulumi registry
- Serverless Framework – AWS AppSync Plugin
- Serverless Stack
Tips for building serverless GraphQL APIs with AWS AppSync
- When building an AWS AppSync GraphQL API, implement a minimal schema first, then build in small steps iteratively. This ensures any changes that cause errors or warnings can be rooted out more quickly and appropriate changes made during development.
- When shifting into ongoing development, use IaC tooling like AWS CLI, Amplify CLI, AWS CDK, or third-party tools to automatically deploy schema changes. This helps prevent any out-of-cycle changes from causing build errors or confusion as changes are applied during iterative development.
- For quick prototypes and demos, use the AWS AppSync console to quickly build an API. For ongoing day-to-day development, shift to a mixed IDE and AWS AppSync console use, and for automation of deployment, shift to continuous integration and deployment (CI/CD) with Amplify CLI, AWS CDK, and AWS CLI as needed. This provides an appropriate combination of visual design and quick interactive implementation for development of a fully automated headless option for CI/CD interactions.
- When setting up caching, verify the profile of queries before turning on caching, then determine if per resolver or full request caching works best for the scenario. This provides an accurate assessment of differences in query time and response. Verify cache effectiveness using AWS X-Ray traces.
- Turn on logging and logging levels based on development, testing, or production needs. For example, if utilizing an immutable infrastructure pattern, logging levels should be minimal in production but might be set higher in a development environment.
When to use a self-hosted, open-source GraphQL server
For some, a fully-managed serverless GraphQL solution like AWS AppSync isn't the right fit. Maybe more fine-grained control over the transports, delivery guarantees, offline queuing, batching, or sampling is needed, all of which may be best served by a self-hosted option. Choices include creating your own GraphQL API Server with Express GraphQL or Hot Chocolate .NET, starting with libraries like Apollo, or taking advantage of GraphQL server options like Hasura or GraphCMS. Then deploy it via Amazon EC2, AWS Beanstalk, or AWS Lambda, fronted by API Gateway or Application Load Balancers.
Keep in mind that with any of these options, developers also need to implement the secure connectivity required to retrieve data from backend data sources, and have the pertinent OpenID, JWT Tokens, or related authentication and authorization mechanisms developed, built, integrated, and working across the GraphQL API itself. Also required is the development of auto scaling, monitoring, logging, and tracing capabilities, which can be built using AWS services like AWS X-Ray, CloudWatch, and Auto Scaling.
How to quickly set up a GraphQL server
To get started with a quick self-hosted option, Apollo GraphQL Server is a popular option. The process involves the following steps.
1. Set up a Node.js project npm init --y
2. Install dependencies npm install apollo-server graphql
3. Create a file and add the Apollo Server dependency const { ApolloServer, gql } = require('apollo-server');
4. Set up a constant with the GraphQL schema const typeDefs = gql`schema goes here`
5. Create data or connect to a data source for queries and mutations that the schema takes actions against
6. Define a resolver that executes those actions against the respective data or data sources:
const resolvers = {
Query: {
objectType: () => functionToGetOjbectType,
},
};7. Instantiate the Apollo GraphQL server const server = new ApolloServer({ typeDefs, resolvers });
8. Set up a listen for the server:
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});9. Start the server with Node node server.js
Now the GraphQL server is available for testing and development and could even be deployed to AWS with containers, using either AWS Fargate, Amazon Elastic Compute Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), or another container option. It is also possible to use Lambda deployments or deploy it straight to VM with Amazon EC2 or create an automated deployment to VM with AWS Beanstalk.
For more details on the various features and capabilities of Apollo GraphQL Server, refer to the Get Started with Apollo Server documentation.
Tips for building GraphQL APIs with a self-hosted server
- When setting up a self-hosted option, be sure to verify which type of service best meets the requirements of the underlying libraries and data requirements. For example, Apollo Server provides federation and subscription options, but the library that provides those is different from the standard server library and requires additional resources that can cause problems on a Lambda deployment. Another example may be a .NET GraphQL Server deployment that may require a particular runtime that would require Windows Server, which would exclude a number of deployment options.
- Another important factor is to determine where the server and data is located. If a virtual private network is in one Region and the data is in another Region, for example, it could add considerable latency and cause a number of issues. Ensuring that the data, database, or services called by the GraphQL server are co-located with the fewest network hops possible ensures the best response time and consistency between the database and GraphQL Server.
- Logging, observability, auto scaling, load balancing, and other requirements can be fulfilled with a number of options available from AWS. There are also numerous third-party options available, but be sure to verify that those options have the appropriate VPN, firewall, and related access capabilities to integrate with a self-hosted solution.
Looking for a fully managed GraphQL service?

Explore AWS AppSync
AWS AppSync is an enterprise level, fully managed serverless GraphQL service with real-time data synchronization and offline programming features. AppSync makes it easy to build data driven mobile and web applications by securely handling all the application data management tasks such as real-time and offline data access, data synchronization, and data manipulation across multiple data sources.