Qual è la differenza tra database relazionali e non relazionali?
Qual è la differenza tra database relazionali e non relazionali?
I database relazionali e non relazionali rappresentano due metodi di archiviazione dei dati per le applicazioni. Un database relazionale (o database SQL) archivia i dati in formato tabulare con righe e colonne. Le colonne contengono attributi dei dati mentre le righe ne riportano i valori. Puoi collegare le tabelle in un database relazionale per ottenere informazioni più approfondite sull'interconnessione tra diversi punti dati. D'altra parte, i database non relazionali (o database NoSQL) utilizzano una varietà di modelli di dati per l'accesso e la gestione dei dati. Sono ottimizzati specificatamente per applicazioni che necessitano di grandi volumi di dati, latenza bassa e modelli di dati flessibili, elementi raggiungibili snellendo alcuni dei criteri di coerenza dei dati degli altri database.
In che modo i database relazionali archiviano i dati?
I database relazionali archiviano i dati in tabelle con colonne e righe. Ogni colonna rappresenta un attributo di dati specifico e ogni riga rappresenta un'istanza di tali dati.
A ogni tabella viene assegnata una chiave primaria, una colonna identificativa che descrive in modo univoco la tabella. La chiave primaria viene utilizzata per stabilire relazioni tra le tabelle. Si usa per mettere in relazione le righe tra le tabelle come chiave esterna in un'altra tabella.
Una volta collegate due tabelle, si ottengono i dati da entrambe con un'unica query. Per interagire con il database relazionale si scrivono query SQL.
Esempio di dati archiviati
Ad esempio, immagina che un rivenditore crei una tabella con tutti i suoi prodotti. In questa tabella, si possono avere colonne per i nomi dei prodotti, le descrizioni e il prezzo. Un'altra tabella contiene dati sui clienti, i loro nomi e ciò che hanno acquistato.
Le tabelle seguenti illustrano questo approccio.
|
ID_prodotto (chiave primaria) |
Nome_prodotto |
Costo_prodotto |
|
P1 |
Prodotto_A |
100 USD |
|
P2 |
Prodotto_B |
50 USD |
|
P3 |
Prodotto_C |
80 USD |
|
ID cliente |
Nome_cliente |
Oggetto_acquistato (chiave esterna) |
|
C1 |
Cliente_A |
P2 |
|
C2 |
Cliente_B |
P1 |
|
C3 |
Cliente_C |
P3 |
In che modo i database non relazionali archiviano i dati?
Esistono diversi sistemi di database non relazionali a causa dei diversi modi in cui gestiscono e archiviano i dati senza schemi. I dati senza schema sono dati archiviati senza i vincoli richiesti dai database relazionali.
Successivamente, descriveremo alcuni dei tipi più comuni di database non relazionali.
Database chiave-valore
Un database chiave-valore archivia i dati come una raccolta di coppie chiave-valore. In coppia, la chiave funge da identificatore univoco. Le chiavi e i valori possono essere qualsiasi cosa, da un oggetto semplice ad articolati oggetti composti.
Maggiori informazioni sui database chiave-valore »
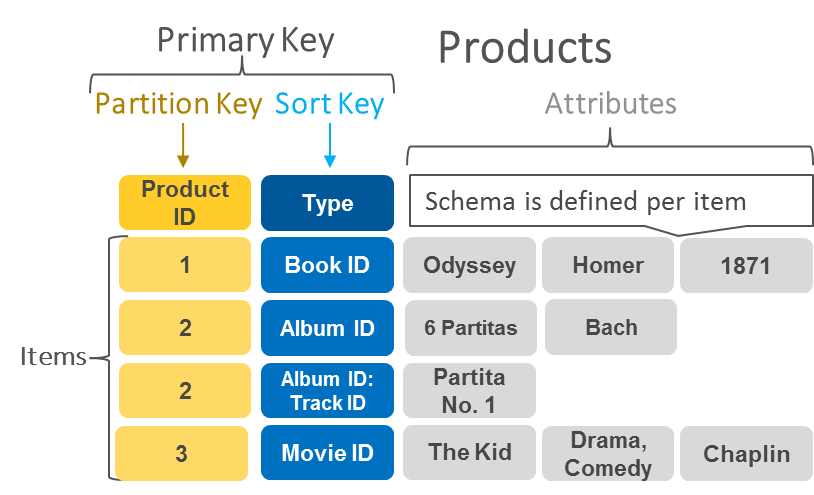
Database di documenti
I database orientati ai documenti hanno lo stesso formato del modello di documento utilizzato dagli sviluppatori nel codice dell'applicazione. Archiviano i dati come oggetti JSON di natura flessibile, semi-strutturata e gerarchica.
L'esempio seguente mostra che aspetto hanno i dati archiviati in un database di documenti.
|
{ company_name: "AnyCompany", address: {street: "1212 Main Street", city: "Anytown"}, phone_number: "1-800-555-0101", industry: ["food processing", "appliances"] type: "private", number_of_employees: 987 } |
Scopri di più sui database di documenti »
Database a grafo
I database a grafo sono progettati appositamente per l’archiviazione e la navigazione di relazioni. Essi usano i nodi per archiviare le entità di dati e i bordi per archiviare le relazioni tra le entità.
Un bordo ha sempre un nodo iniziale, un nodo finale, un tipo e una direzione. Ad esempio, può descrivere le relazioni padre-figlio, le operazioni e la proprietà.
Maggiori informazioni sui database a grafo »

Differenze principali tra i database relazionali e quelli non relazionali
I database relazionali e non relazionali archiviano e gestiscono i dati in modo molto diverso. Nelle sezioni seguenti sono descritte le differenze specifiche.
Struttura
I database relazionali archiviano i dati in forma tabulare e seguono regole rigide relative alle variazioni dei dati e alle relazioni tra tabelle. Consentono di elaborare query complesse su dati strutturati mantenendo l'integrità e la coerenza dei dati.
I database non relazionali sono più flessibili e utili per i dati con requisiti mutevoli. Puoi utilizzarli per archiviare immagini, video, documenti e altri contenuti semi-strutturati e non strutturati.
Meccanismo di integrità dei dati
Atomicità, consistenza, isolamento e durabilità (ACID) si riferiscono alla capacità del database di mantenere l'integrità dei dati nonostante errori o interruzioni nell'elaborazione dei dati.
Un modello di database relazionale segue rigide proprietà ACID. Ciò significa che una serie di operazioni consequenziali verranno sempre completate insieme. Se una singola operazione fallisce, fallisce l'intera serie di operazioni. Ciò garantisce l'accuratezza dei dati in ogni momento.
Per contro, i database non relazionali offrono un modello più flessibile di disponibilità, soft-state e definitivamente coerenti (BASE).
I database non relazionali garantiscono la disponibilità ma non la coerenza immediata. Lo stato del database può cambiare nel tempo e alla fine diventare coerente. Alcuni database non relazionali possono offrire la conformità ACID alle prestazioni o altri compromessi.
Prestazioni
Le prestazioni dei database relazionali dipendono dal relativo sottosistema di dischi. Per migliorare le prestazioni del database, è possibile utilizzare SSD e ottimizzare il disco configurandolo con una serie ridondante di dischi indipendenti (RAID). Per ottenere prestazioni ottimali, è inoltre necessario ottimizzare gli indici, le strutture delle tabelle e le query.
Al contrario, le prestazioni dei database NoSQL dipendono dalla latenza di rete, dalle dimensioni del cluster hardware e dall'applicazione chiamante. Esistono diversi modi per migliorare le prestazioni di un database non relazionale:
- Aumentare le dimensioni del cluster
- Ridurre al minimo la latenza di rete
- Indicizzare e memorizzare nella cache
I database NoSQL offrono prestazioni e scalabilità più elevate per casi d'uso specifici rispetto a un database relazionale.
Scalabilità
Lo schema rigido di un sistema di database relazionale su larga scala può presentare dei problemi. In genere è possibile scalare verticalmente aggiungendo più CPU o risorse RAM al server. Puoi anche scalare orizzontalmente duplicando i dati tra i server per carichi di lavoro di sola lettura. Tuttavia, il dimensionamento orizzontale per i carichi di lavoro di lettura-scrittura richiede strategie speciali come il partizionamento e lo sharding.
Maggiori informazioni sullo sharding dei database »
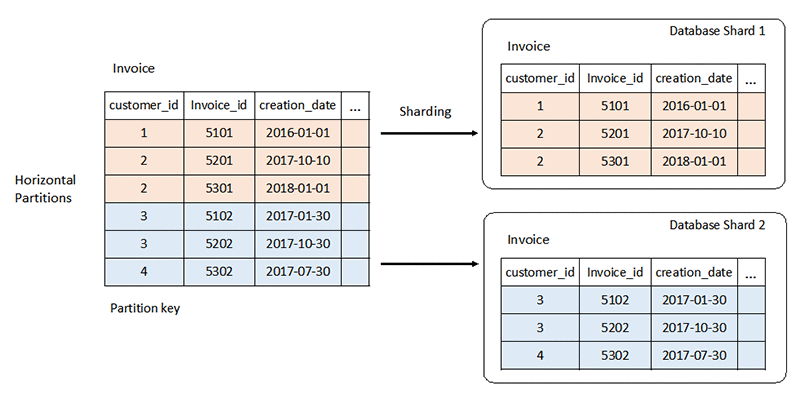
Al contrario, i database NoSQL sono altamente scalabili. Puoi distribuire più facilmente il loro carico di lavoro su più nodi. Questi database possono elaborare grandi volumi di dati partizionandoli in set più piccoli e distribuendo i set su più nodi.

Quando utilizzare i database relazionali e quando i non relazionali
I database relazionali sono la scelta migliore se i dati sono prevedibili in termini di dimensioni, struttura e frequenza di accesso. Potresti anche preferire un sistema di gestione di database relazionali se le relazioni tra le entità sono importanti. Ad esempio, se disponi di un set di dati di grandi dimensioni con una struttura e relazioni complesse, desideri che le relazioni si distinguano per analisi e facilità d'uso.
Al contrario, un modello non relazionale funziona meglio per archiviare dati che sono flessibili nella forma o nelle dimensioni o che potrebbero cambiare in futuro.
Inoltre, in alcuni casi, le relazioni tra i dati semplicemente non si adattano bene al formato tabulare delle chiavi primarie ed esterne. Ad esempio, per modellare gli amici e le relazioni in un social network, in un database relazionale avresti bisogno di una tabella con centinaia di righe.
Al contrario, in un database non relazionale questo può essere rappresentato in una singola riga. L'esempio seguente mostra i dati di un membro con quattro amici in un database non relazionale.
|
Member_id Friend_id M1 M2 M1 M3 M1 M4 M1 M5 |
{member name: “member 1” member friends: “member 2, member 3, member 4, member 5”} |
Riepilogo delle differenze: database relazionali e non relazionali
|
Categoria |
Database relazionali |
Database non relazionale |
|
Modello di dati |
Tabulare. |
Chiave-valore, documento o grafico. |
|
Tipo di dati |
Strutturato. |
Dati strutturati, semi-strutturati e non strutturati. |
|
Integrità dei dati |
Alto con piena conformità ACID. |
Modello di consistenza definitivo. |
|
Prestazioni |
Migliorato con l'aggiunta di più risorse al server. |
Migliorato con l'aggiunta di più nodi del server. |
|
Dimensionamento |
Il dimensionamento orizzontale richiede strategie di gestione dei dati aggiuntive. |
Il dimensionamento orizzontale è semplice e diretto. |
In che modo AWS può supportare i requisiti dei tuoi database relazionali e non relazionali?
Amazon Web Services (AWS) offre numerosi servizi per i requisiti di database relazionali e non relazionali.
Servizi AWS per database relazionali
Amazon Relational Database Service (Amazon RDS) è una raccolta di servizi gestiti che semplifica la configurazione, l'utilizzo e il dimensionamento di un database relazionale nel cloud. I database cloud offrono molti vantaggi come prestazioni, scalabilità ed efficienza in termini di costi. Puoi usare motori di database relazionali come questi:
- Amazon RDS per SQL Server per distribuire più edizioni di SQL Server (2014, 2016, 2017 e 2019)
- Amazon RDS for MySQL supporterà le versioni 5.7 e 8.0 di MySQL Community Edition
- Amazon RDS per MariaDB supporterà le versioni di MariaDB Server 10.3, 10.4, 10.5 e 10.6
Inoltre, Amazon RDS for Oracle ha due diversi modelli di licenza, il che significa che non sono necessarie licenze Oracle acquistate separatamente se non le possiedi.
Servizi AWS per database non relazionali
AWS dispone anche di diversi servizi di database NoSQL per soddisfare tutti i requisiti NoSQL. Ecco alcuni esempi:
- Amazon DynamoDB è un servizio di database chiave-valore che fornisce una latenza costante di millisecondi a una cifra per carichi di lavoro su qualsiasi scala.
- Amazon DocumentDB (con compatibilità MondoDB) è un popolare database orientato ai documenti con API potenti e intuitive per uno sviluppo flessibile e iterativo.
- Amazon MemoryDB è un servizio di database in memoria durevole. Offre una latenza di lettura e scrittura di microsecondi per prestazioni ultra veloci.
- Amazon Neptune è un servizio di database a grafo completamente gestito per creare ed eseguire applicazioni grafiche ad alte prestazioni.
- Amazon OpenSearch Service è stato creato appositamente per fornire visualizzazioni e analisi quasi in tempo reale di dati generati da macchine.
Inizia a usare database relazionali e non relazionali su AWS creando un account oggi stesso.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages