Amazon Web Services ブログ
Category: Artificial Intelligence

【開催報告】AWS Summit Japan 2026 〜 Future of Agentic Commerce ブース
AWS で実現する新しい E-Commerce の形 〜 Future of Agentic Commerce […]

Chronos-2 on Amazon SageMaker AI にアクセスする3つのパターン – AutoGluon-Cloud v0.5.0 で数行に
みなさん、こんにちは。ソリューションアーキテクトの 寺山です。 AutoGluon-Cloud v0.5.0 […]
ナレッジグラフと IoT データによる生産ラインのボトルネック分析 〜AI エージェントのための製造データの構造化〜
はじめに こんにちは、IoT Specialist ソリューションアーキテクトの新澤です。2026 年 6 月 […]

【開催報告】AWS Summit Japan 2026 — 「AI ペルソナ達がビジネス課題解決を加速する」バーチャル AI エキスパート
AWS Summit Japan 2026 の流通小売・消費財・飲食ブースにて、私たちは「バーチャル AI エ […]

音声 AI エージェントで実現するセントラルキッチンのハンズフリーオペレーション
本ブログは、株式会社アドバンスト・メディア様と Amazon Web Services Japan が共同で執 […]

AIで変える鉄道保全と、「クローズド」を読み解くクラウド設計 — AWS Summit Japan 2026 展示ブース開催報告
2026年6月25日〜26日、幕張メッセで開催された AWS Summit Japan 2026 にて、AWS […]

Amazon Bedrock と Oracle Database@AWS で生成 AI ユースケースを加速する
Oracle Database@AWS 上の Oracle AI Database 26ai をベクトルストアとして使い、Amazon Bedrock の Amazon Titan 埋め込みモデルと Anthropic Claude LLM を統合した RAG アシスタントアプリケーションの構築手順を解説します。
株式会社Diverse が Amazon SageMaker で実現した「温度感」ベースのマッチング体験
はじめに 本ブログは 株式会社Diverse 様と Amazon Web Services Japan 合同会 […]

Amazon Bedrock における LLM コストの最適化:請求の帰属から運用テレメトリまで
Amazon Bedrock 上で、基盤モデル (FM) の一種である大規模言語モデル (LLM) の利用が拡 […]
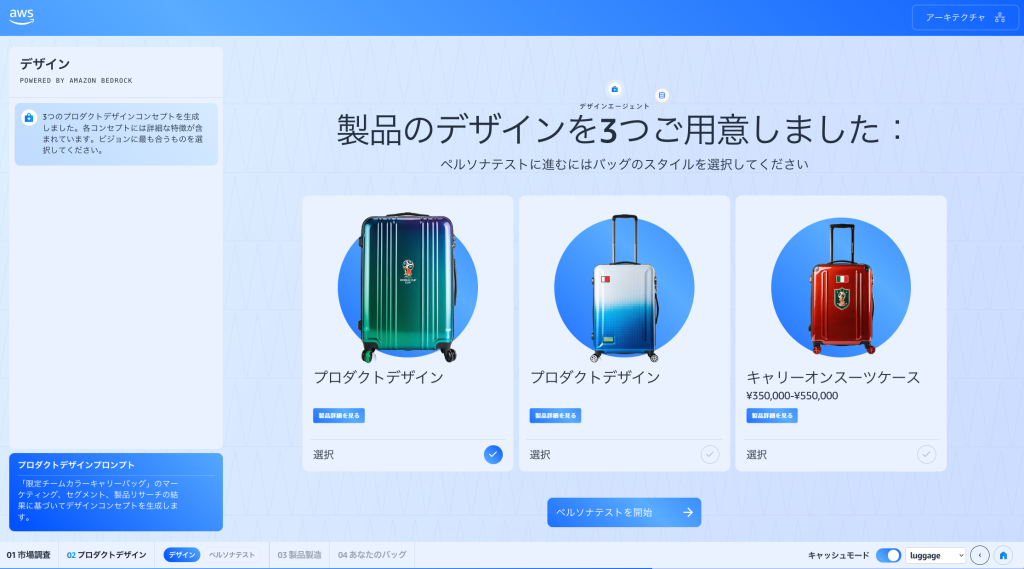
【開催報告】AWS Summit Japan 2026 ― AI で加速する製品イノベーション 〜マルチエージェントで実現する製品開発
はじめに AWS Summit Japan 2026 の流通小売・消費財・飲食ブースにて、私たちは「AI で加 […]