Amazon Web Services ブログ
Category: Artificial Intelligence

Kiro でテスト駆動開発(TDD):こうあるべき体験
私のキャリアの初期に、所属していた組織は、コード品質の向上と自信を持ってリファクタリングできる体制づくりのために、本格的にユニットテストを導入するという正しい判断を下しました。私たちは テスト駆動開発(TDD) の導入を試みました。その利点は理解していたものの、TDD を実践する作業自体が負担に感じられ、エンジニアたちにこの手法を一貫して適用してもらえませんでした。私自身、TDD というアイデアは大好きでしたが、実際の作業は嫌いでした。本記事では、Kiro を使って TDD を実践する方法を紹介し、red-green-refactor サイクルに沿ったテストを手作業で書くという苦痛を伴うことなく、TDD の恩恵を受ける方法をお見せします。

月刊 AWS 製造 2026 年 7 月号
みなさん、こんにちは。ソリューションアーキテクトの吉川です。FIFA ワールドカップ 2026 がいよいよ佳境 […]

【開催報告】AWS GenAI Catapult! 〜AI 駆動型ハッカソンイベント:ユースケース創出から Kiro によるプロトタイプ開発まで〜
2026年6月11日(木)、12日(金)の2日間、AWS 麻布台オフィスにて AI 駆動型ハッカソンイベント「 […]

AWS Weekly Roundup: AWS Builder Center 1 周年、セキュリティハブにおけるネットワークスキャン、Loom for AWS など (2026 年 7 月 13 日)
AWS Builder Center は 2026年 7 月 6 日週、提供開始から 1 周年を迎えました。2 […]
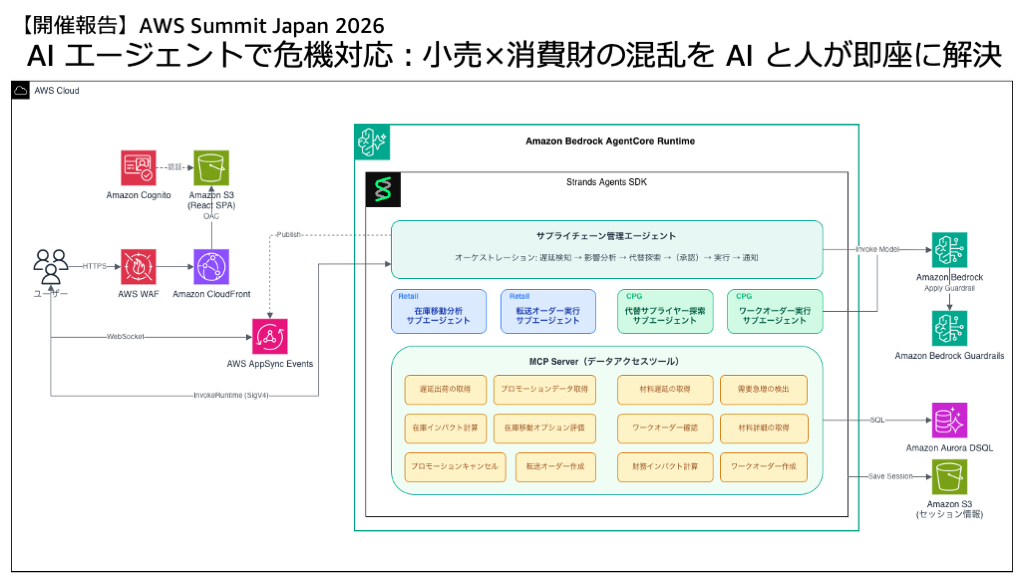
【開催報告】AWS Summit Japan 2026 — AI エージェントで危機対応:小売×消費財の混乱を AI と人が即座に解決
サプライチェーンの「想定外」に AI エージェントと人間が即応するデモを AWS Summit Japan 2026 で展示しました。BCP 訓練の実態、Human-in-the-Loop の仕組み、来場者との対話から見えた課題と期待、そして今日から試せるワークショップまでを一本にまとめた開催報告です。

AI と一緒に進める AWS Well-Architected Framework レビュー のすすめ
「セキュリティは大丈夫だろうか」「障害が起きたときに復旧できるだろうか」「このアーキテクチャはベストプラクティスに沿っているだろうか」AWS 上にシステムを構築・運用する中で、このような不安を感じたことはないでしょうか。こうした潜在的リスクを体系的に炙り出し、改善していくためのフレームワークとして有用なのが AWS Well-Architected Framework です。
しかし、Well-Architected レビューの実施には「フレームワークの内容を理解するのが難しい」「いつでも気軽に相談できるアドバイザーが欲しい」「時間がなくてレビューを実施できない」という悩みの声を耳にします。そこで本記事では、AI を活用して Well-Architected レビューを加速する 3 つのアプローチを紹介します。(AWS Summit Japan 2026 の Well-Architected ブース展示内容)

ハイテクインターが Amazon Rekognition と Graviton プロセッサで実現した富山市の人流観測プラットフォーム
本ブログは ハイテクインター株式会社 様と Amazon Web Services Japan 合同会社が共同 […]
株式会社村田製作所様の AWS 生成 AI 活用事例 : 3 万人利用の「Murata Coworker」を AI エージェント活用基盤へ進化させるまで
みなさん、こんにちは。AWS ソリューションアーキテクトの池田です。 AI エージェントの活用に取り組む企業が […]

Kiro のバースデーウィークへようこそ
Kiro は誕生から 1 周年を迎え、AI コーディングからエージェンティックエンジニアリングへと進化しました。7 月 13 日から 17 日まで(太平洋時間)の 1 週間、コミュニティへの感謝を込めたバースデーウィークを開催します。ボーナスクレジットを獲得できるデイリーコーディングチャレンジ、7 月 15 日のバースデーパーティーライブストリーム、コミュニティスポットライト、そしていくつかのサプライズをご用意しています。#BuildWithKiro #TeamKiro #1YearOfKiro で、皆さんの 1 年目を一緒にお祝いしましょう。
AWS Transform for migrations が 13 言語のローカライズに対応
AWS Transform for migrations が 13 言語のローカライズに対応しました。移行チームはコンソールの設定で表示言語を切り替えることができ、会話型インターフェースやジョブプランなどのマイグレーションワークフロー全体を母国語で利用できるようになりました。