Amazon Web Services ブログ
Category: Artificial Intelligence
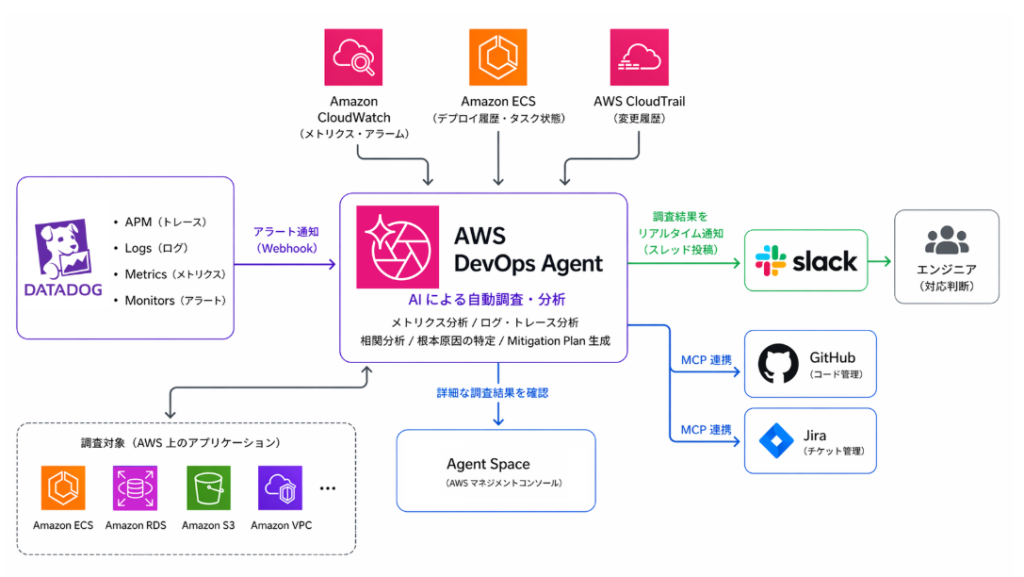
寄稿:弁護士ドットコムにおける AWS DevOps Agent の活用事例 – インシデント対応の自動化と属人化の解消
弁護士ドットコム株式会社は、『「プロフェッショナル・テック」で、次の常識をつくる。』というミッションのもと、国内最大級の法律相談ポータルサイト「弁護士ドットコム」や契約マネジメントプラットフォーム「クラウドサイン」などを運営しています。また、最近ではリーガル特化型 AI エージェント「Legal Brain エージェント」を開発し、AI を活用したリーガルサービスの進化にも取り組んでいます。PRE 部は、これらのサービスを支えるインフラの信頼性と運用効率の向上を担っています。本記事では、AWS DevOps Agent を用いたインシデント対応の自動化と運用組織のあり方の見直しを進めている事例を紹介します。

Kiro で GPT-5.6 が利用可能になりました
Kiro で初めて OpenAI のモデルが利用可能になりました。あわせてこのローンチは Kiro の 1 周年でもあります。2025 年 7 月 14 日のパブリックプレビュー以降、Kiro は仕様駆動の IDE から IDE / CLI / Web にまたがるエージェンティック開発プラットフォームへ成長してきました。本日(2026 年 7 月 14 日)より GPT-5.6 の Sol / Terra / Luna が Kiro の IDE / CLI / Web が利用可能になりました。性能とコストのカーブ上でそれぞれ異なるポイントにチューニングされた 3 段構成です。

Claude Opus 5 が Kiro で利用可能になりました
Kiro の IDE / CLI / Web すべてで Claude Opus 5 が本日から利用可能になりました。Opus 4.8 からの意味のある進化として、時間のかかる作業に強くなり、並列エージェントの協調が改善され、長いセッションにおけるコストとレイテンシをより細かく扱える新しいコントロールが備わっています。

【開催報告】Neuron Community – 2026 Vol.1
2026年7月15日 (水) に開催された「Neuron Community – 2026 Vol.1」の様子をレポートします。このイベントは、「Neuron Community」の協力のもと開催しました。Neuron Community は、ユーザー間で AWS Trainium / AWS Inferentia エコシステムに関する情報や知見の共有を促進するための場として発足したものです。今回は、AWS Summit Japan 2026 開催後ということもあり、AWS Summit Japan の振り返りや、AWS Neuron のアップデート情報が多めの内容となりました。

スマートグラス × 音声 AI エージェントで実現する店舗業務のハンズフリー支援
AWS Summit Japan 2026 で展示した「スマートグラス × 音声 AI エージェント」による店舗業務支援デモを紹介します。Amazon Nova 2 Sonic と Amazon Bedrock AgentCore Gateway を中核に、声で話しかけるだけで AI が音声と AR 表示で即答する体験を、システム構成や技術的なポイントとともに解説します。

【開催報告】AWS Summit Japan 2026 — 物流異常を Amazon Quick が自動解決:配送在庫の異常検知〜問合せまで一気通貫
物流の現場では、基幹・受発注・在庫・配送など複数のシステムにデータが分散しています。今回の展示では、Amazon Quick がこれらの課題をどのように解決するかを、実際の業務シナリオに沿ってデモでお見せしました。皆さまの物流現場でも、こんな課題はありませんか?

AWS Japan Summit 2026 スマートマシンデモ ー自律診断とリアルタイム安全監視ー 展示報告
はじめに 2026年6月25日、26日に幕張メッセで開催された AWS Summit Japan 2026にお […]

AWS Weekly Roundup: ワンクリック Lambda セットアッププロンプト、Bedrock での OpenAI GPT-5.6 モデルなど (2026 年 7 月 20 日)
2026 年 7 月 20 日週、私のチームは AWS Korea User Group (AWSKRUG) […]

9 社合同 AI-DLC Unicorn Gym:AI と作った 2 日間で見えた、 「書く」から「決める」への転換
2026 年 6 月、事業ドメインの異なる 9 社 11 チーム・約 90 名が一堂に会し、Kiro と Claude Code を使って自社の実課題に挑む AI-DLC Unicorn Gym を合同開催しました。動くものを見ながらビジネスと開発がその場で会話する 2日間を通じて、多くのチームが「開発の主役が書くことから決めることへ移る」という手応えを掴み、参加者アンケートでは満足度 4.7/5・平均 74% の工数削減という結果につながりました。各チームが持ち込んだテーマ、成果発表のハイライト、そして率直なお客様の声まで、合同開催だからこそ見えた 2 日間をレポートします。

週刊生成AI with AWS – 2026/7/13 週
今週の「週刊生成AI with AWS」は、3 万人が利用する生成 AI 基盤を AIエージェント活用基盤へ進化させた村田製作所様の事例をはじめ、音声 AI や Well-Architected レビューでのAI活用、LLMコスト最適化など幅広い話題をお届けします。公開から 1 周年を迎えた Kiro については、この 1 年の振り返りや GPT-5.6 対応などの記事に加え、AWS Summit Japan 2026
各ブースの開催報告もまとめてご紹介。サービスアップデートでは、OpenAI GPT-5.6 の Amazon Bedrock での一般提供開始や、Amazon GuardDuty AI Protection・AWS Security
Hub の AI インベントリなど、AI ワークロードのセキュリティ強化に関する発表が並びます。